 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dataset Bias in Medical AI: A Generalized and Modality-Agnostic Auditing Framework
Mar 13, 2025Data-driven AI is establishing itself at the center of evidence-based medicine. However, reports of shortcomings and unexpected behavior are growing due to AI's reliance on association-based learning. A major reason for this behavior: latent bias in machine learning datasets can be amplified during training and/or hidden during testing. We present a data modality-agnostic auditing framework for generating targeted hypotheses about sources of bias which we refer to as Generalized Attribute Utility and Detectability-Induced bias Testing (G-AUDIT) for datasets. Our method examines the relationship between task-level annotations and data properties including protected attributes (e.g., race, age, sex) and environment and acquisition characteristics (e.g., clinical site, imaging protocols). G-AUDIT automatically quantifies the extent to which the observed data attributes may enable shortcut learning, or in the case of testing data, hide predictions made based on spurious associations. We demonstrate the broad applicability and value of our method by analyzing large-scale medical datasets for three distinct modalities and learning tasks: skin lesion classification in images, stigmatizing language classification in Electronic Health Records (EHR), and mortality prediction for ICU tabular data. In each setting, G-AUDIT successfully identifies subtle biases commonly overlooked by traditional qualitative methods that focus primarily on social and ethical objectives, underscoring its practical value in exposing dataset-level risks and supporting the downstream development of reliable AI systems. Our method paves the way for achieving deeper understanding of machine learning datasets throughout the AI development life-cycle from initial prototyping all the way to regulation, and creates opportunities to reduce model bias, enabling safer and more trustworthy AI systems.
Are Clinical T5 Models Better for Clinical Text?
Dec 08, 2024



Large language models with a transformer-based encoder/decoder architecture, such as T5, have become standard platforms for supervised tasks. To bring these technologies to the clinical domain, recent work has trained new or adapted existing models to clinical data. However, the evaluation of these clinical T5 models and comparison to other models has been limited. Are the clinical T5 models better choices than FLAN-tuned generic T5 models? Do they generalize better to new clinical domains that differ from the training sets? We comprehensively evaluate these models across several clinical tasks and domains. We find that clinical T5 models provide marginal improvements over existing models, and perform worse when evaluated on different domains. Our results inform future choices in developing clinical LLMs.
Give me Some Hard Questions: Synthetic Data Generation for Clinical QA
Dec 05, 2024



Clinical Question Answering (QA) systems enable doctors to quickly access patient information from electronic health records (EHRs). However, training these systems requires significant annotated data, which is limited due to the expertise needed and the privacy concerns associated with clinical data. This paper explores generating Clinical QA data using large language models (LLMs) in a zero-shot setting. We find that naive prompting often results in easy questions that do not reflect the complexity of clinical scenarios. To address this, we propose two prompting strategies: 1) instructing the model to generate questions that do not overlap with the input context, and 2) summarizing the input record using a predefined schema to scaffold question generation. Experiments on two Clinical QA datasets demonstrate that our method generates more challenging questions, significantly improving fine-tuning performance over baselines. We compare synthetic and gold data and find a gap between their training efficacy resulting from the quality of synthetically generated answers.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
An Eye on Clinical BERT: Investigating Language Model Generalization for Diabetic Eye Disease Phenotyping
Nov 15, 2023Diabetic eye disease is a major cause of blindness worldwide. The ability to monitor relevant clinical trajectories and detect lapses in care is critical to managing the disease and preventing blindness. Alas, much of the information necessary to support these goals is found only in the free text of the electronic medical record. To fill this information gap, we introduce a system for extracting evidence from clinical text of 19 clinical concepts related to diabetic eye disease and inferring relevant attributes for each. In developing this ophthalmology phenotyping system, we are also afforded a unique opportunity to evaluate the effectiveness of clinical language models at adapting to new clinical domains. Across multiple training paradigms, we find that BERT language models pretrained on out-of-distribution clinical data offer no significant improvement over BERT language models pretrained on non-clinical data for our domain. Our study tempers recent claims that language models pretrained on clinical data are necessary for clinical NLP tasks and highlights the importance of not treating clinical language data as a single homogeneous domain.
The Problem of Semantic Shift in Longitudinal Monitoring of Social Media: A Case Study on Mental Health During the COVID-19 Pandemic
Jun 22, 2022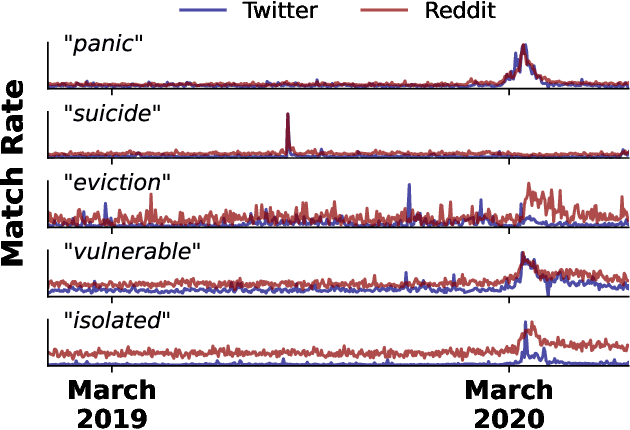
Social media allows researchers to track societal and cultural changes over time based on language analysis tools. Many of these tools rely on statistical algorithms which need to be tuned to specific types of language. Recent studies have shown the absence of appropriate tuning, specifically in the presence of semantic shift, can hinder robustness of the underlying methods. However, little is known about the practical effect this sensitivity may have on downstream longitudinal analyses. We explore this gap in the literature through a timely case study: understanding shifts in depression during the course of the COVID-19 pandemic. We find that inclusion of only a small number of semantically-unstable features can promote significant changes in longitudinal estimates of our target outcome. At the same time, we demonstrate that a recently-introduced method for measuring semantic shift may be used to proactively identify failure points of language-based models and, in turn, improve predictive generalization.
Then and Now: Quantifying the Longitudinal Validity of Self-Disclosed Depression Diagnoses
Jun 22, 2022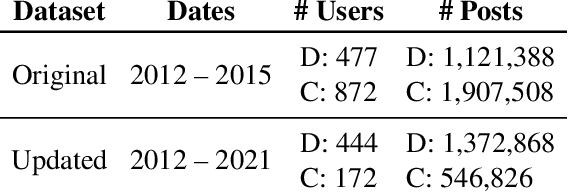
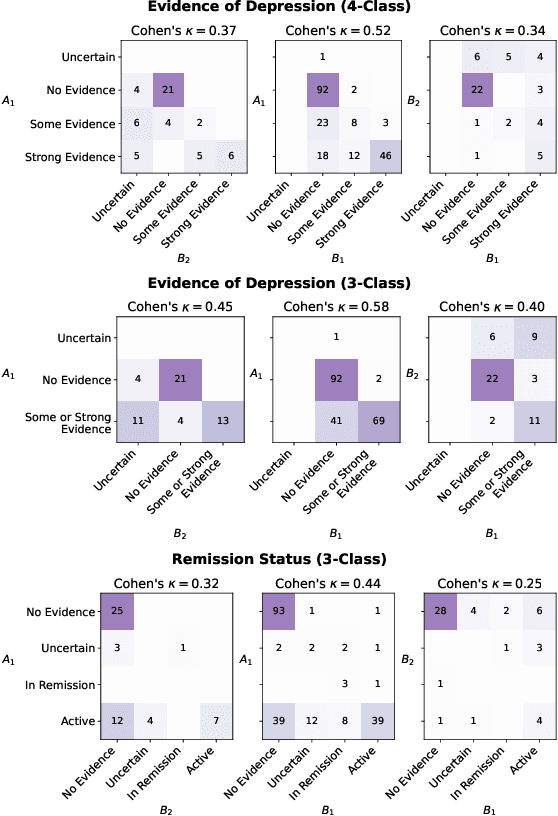
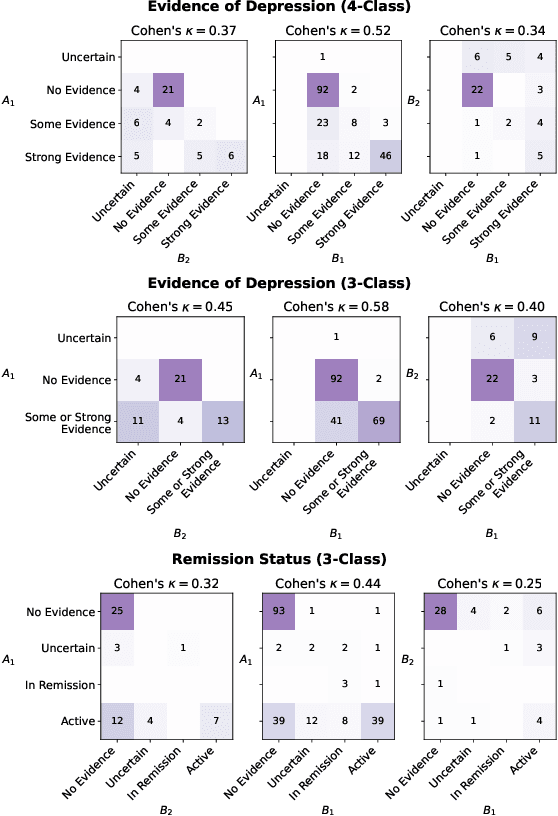
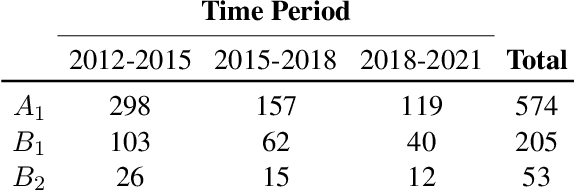
Self-disclosed mental health diagnoses, which serve as ground truth annotations of mental health status in the absence of clinical measures, underpin the conclusions behind most computational studies of mental health language from the last decade. However, psychiatric conditions are dynamic; a prior depression diagnosis may no longer be indicative of an individual's mental health, either due to treatment or other mitigating factors. We ask: to what extent are self-disclosures of mental health diagnoses actually relevant over time? We analyze recent activity from individuals who disclosed a depression diagnosis on social media over five years ago and, in turn, acquire a new understanding of how presentations of mental health status on social media manifest longitudinally. We also provide expanded evidence for the presence of personality-related biases in datasets curated using self-disclosed diagnoses. Our findings motivate three practical recommendations for improving mental health datasets curated using self-disclosed diagnoses: 1) Annotate diagnosis dates and psychiatric comorbidities; 2) Sample control groups using propensity score matching; 3) Identify and remove spurious correlations introduced by selection bias.
Gender and Racial Fairness in Depression Research using Social Media
Mar 18, 2021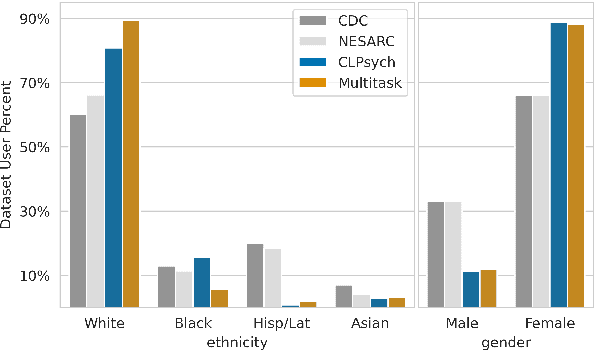
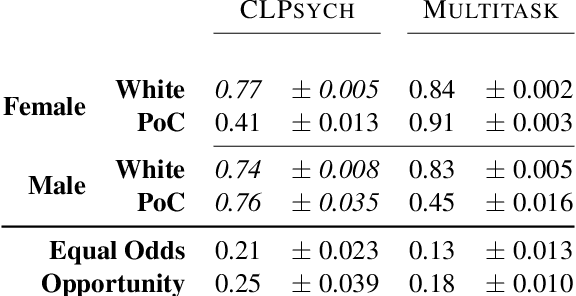
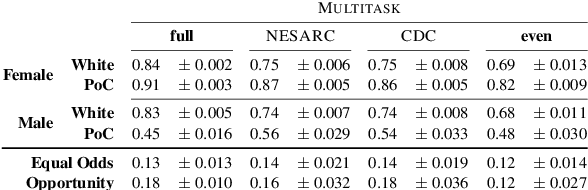
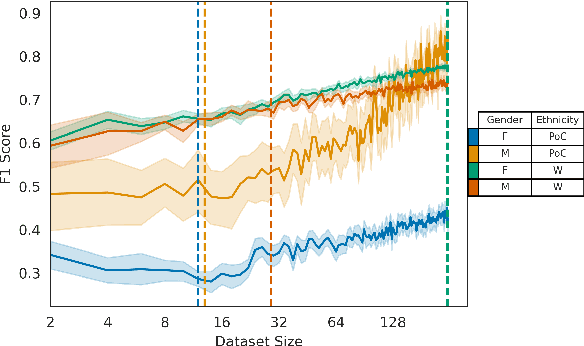
Multiple studies have demonstrated that behavior on internet-based social media platforms can be indicative of an individual's mental health status. The widespread availability of such data has spurred interest in mental health research from a computational lens. While previous research has raised concerns about possible biases in models produced from this data, no study has quantified how these biases actually manifest themselves with respect to different demographic groups, such as gender and racial/ethnic groups. Here, we analyze the fairness of depression classifiers trained on Twitter data with respect to gender and racial demographic groups. We find that model performance systematically differs for underrepresented groups and that these discrepancies cannot be fully explained by trivial data representation issues. Our study concludes with recommendations on how to avoid these biases in future research.
On the State of Social Media Data for Mental Health Research
Nov 10, 2020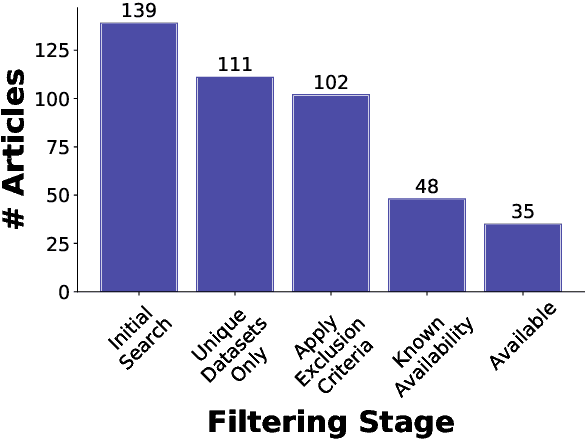
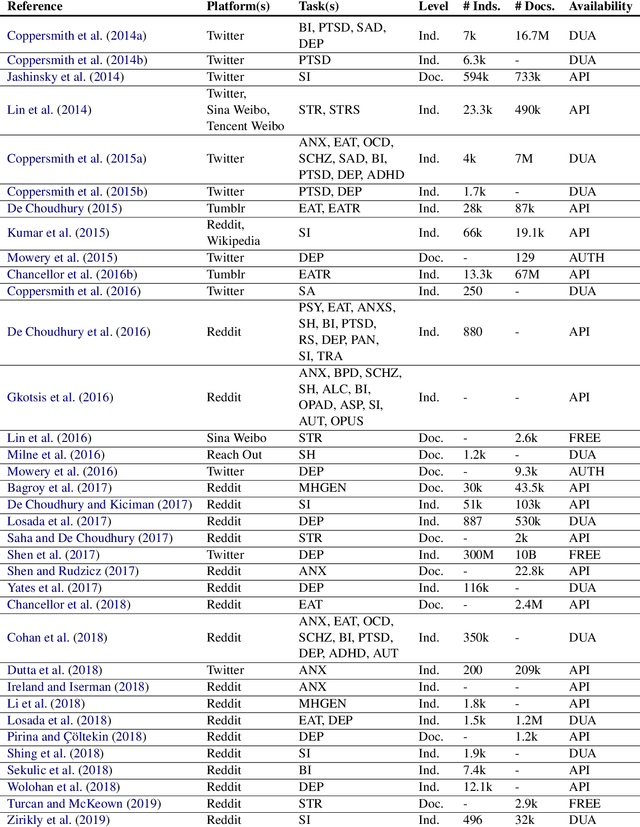
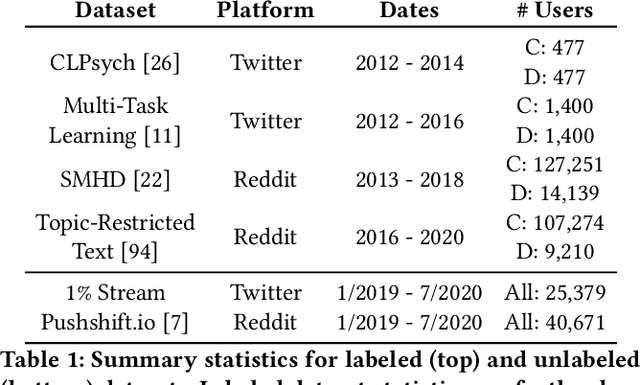
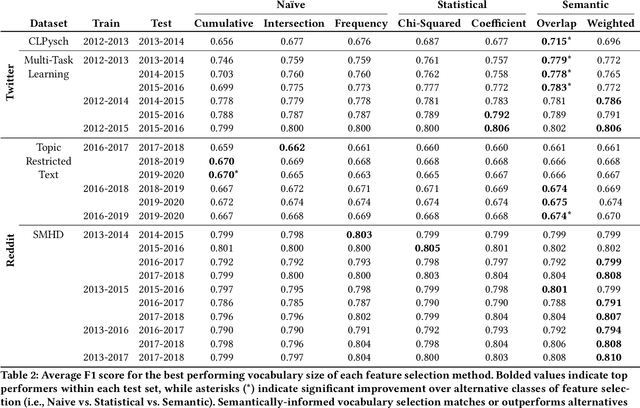
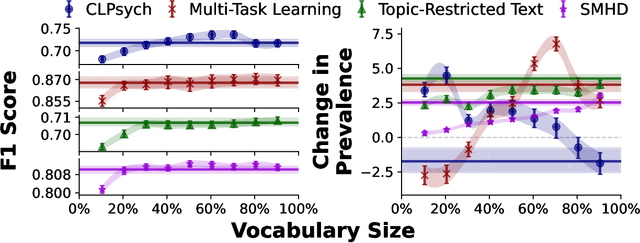
Data-driven methods for mental health treatment and surveillance have become a major focus in computational science research in the last decade. However, progress in the domain, in terms of both medical understanding and system performance, remains bounded by the availability of adequate data. Prior systematic reviews have not necessarily made it possible to measure the degree to which data-related challenges have affected research progress. In this paper, we offer an analysis specifically on the state of social media data that exists for conducting mental health research. We do so by introducing an open-source directory of mental health datasets, annotated using a standardized schema to facilitate meta-analysis.
Geocoding Without Geotags: A Text-based Approach for reddit
Oct 07, 2018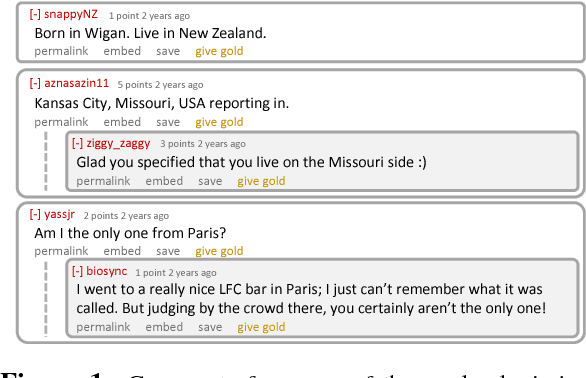


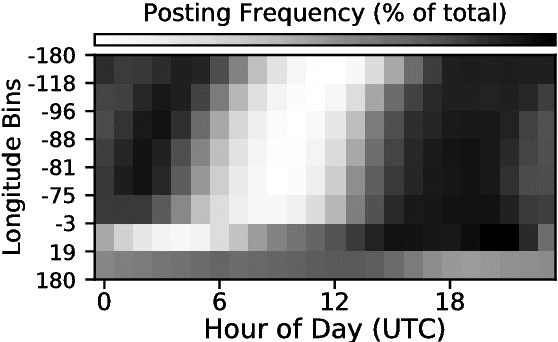
In this paper, we introduce the first geolocation inference approach for reddit, a social media platform where user pseudonymity has thus far made supervised demographic inference difficult to implement and validate. In particular, we design a text-based heuristic schema to generate ground truth location labels for reddit users in the absence of explicitly geotagged data. After evaluating the accuracy of our labeling procedure, we train and test several geolocation inference models across our reddit data set and three benchmark Twitter geolocation data sets. Ultimately, we show that geolocation models trained and applied on the same domain substantially outperform models attempting to transfer training data across domains, even more so on reddit where platform-specific interest-group metadata can be used to improve inferences.