 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dataset Bias in Medical AI: A Generalized and Modality-Agnostic Auditing Framework
Mar 13, 2025Data-driven AI is establishing itself at the center of evidence-based medicine. However, reports of shortcomings and unexpected behavior are growing due to AI's reliance on association-based learning. A major reason for this behavior: latent bias in machine learning datasets can be amplified during training and/or hidden during testing. We present a data modality-agnostic auditing framework for generating targeted hypotheses about sources of bias which we refer to as Generalized Attribute Utility and Detectability-Induced bias Testing (G-AUDIT) for datasets. Our method examines the relationship between task-level annotations and data properties including protected attributes (e.g., race, age, sex) and environment and acquisition characteristics (e.g., clinical site, imaging protocols). G-AUDIT automatically quantifies the extent to which the observed data attributes may enable shortcut learning, or in the case of testing data, hide predictions made based on spurious associations. We demonstrate the broad applicability and value of our method by analyzing large-scale medical datasets for three distinct modalities and learning tasks: skin lesion classification in images, stigmatizing language classification in Electronic Health Records (EHR), and mortality prediction for ICU tabular data. In each setting, G-AUDIT successfully identifies subtle biases commonly overlooked by traditional qualitative methods that focus primarily on social and ethical objectives, underscoring its practical value in exposing dataset-level risks and supporting the downstream development of reliable AI systems. Our method paves the way for achieving deeper understanding of machine learning datasets throughout the AI development life-cycle from initial prototyping all the way to regulation, and creates opportunities to reduce model bias, enabling safer and more trustworthy AI systems.
Data AUDIT: Identifying Attribute Utility- and Detectability-Induced Bias in Task Models
Apr 06, 2023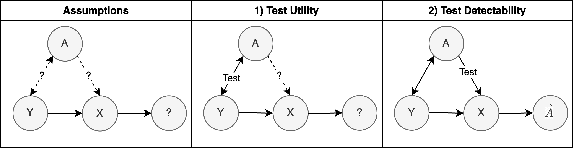
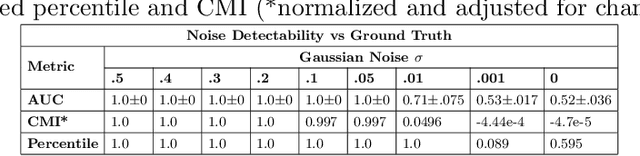
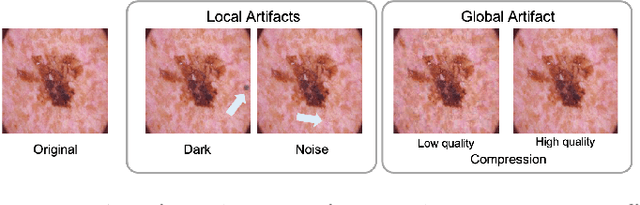
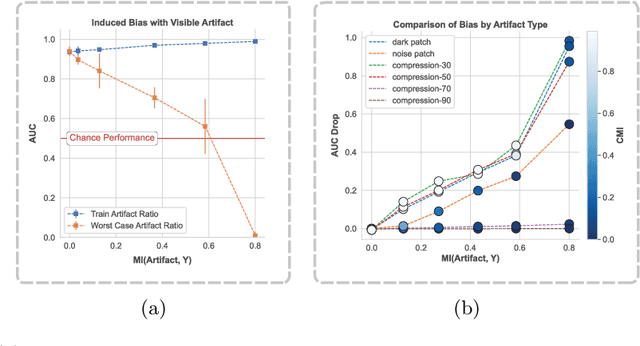
To safely deploy deep learning-based computer vision models for computer-aided detection and diagnosis, we must ensure that they are robust and reliable. Towards that goal, algorithmic auditing has received substantial attention. To guide their audit procedures, existing methods rely on heuristic approaches or high-level objectives (e.g., non-discrimination in regards to protected attributes, such as sex, gender, or race). However, algorithms may show bias with respect to various attributes beyond the more obvious ones, and integrity issues related to these more subtle attributes can have serious consequences. To enable the generation of actionable, data-driven hypotheses which identify specific dataset attributes likely to induce model bias, we contribute a first technique for the rigorous, quantitative screening of medical image datasets. Drawing from literature in the causal inference and information theory domains, our procedure decomposes the risks associated with dataset attributes in terms of their detectability and utility (defined as the amount of information knowing the attribute gives about a task label). To demonstrate the effectiveness and sensitivity of our method, we develop a variety of datasets with synthetically inserted artifacts with different degrees of association to the target label that allow evaluation of inherited model biases via comparison of performance against true counterfactual examples. Using these datasets and results from hundreds of trained models, we show our screening method reliably identifies nearly imperceptible bias-inducing artifacts. Lastly, we apply our method to the natural attributes of a popular skin-lesion dataset and demonstrate its success. Our approach provides a means to perform more systematic algorithmic audits and guide future data collection efforts in pursuit of safer and more reliable models.