 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
Dec 16, 2024WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
Selecting Shots for Demographic Fairness in Few-Shot Learning with Large Language Models
Nov 14, 2023Recently, work in NLP has shifted to few-shot (in-context) learning, with large language models (LLMs) performing well across a range of tasks. However, while fairness evaluations have become a standard for supervised methods, little is known about the fairness of LLMs as prediction systems. Further, common standard methods for fairness involve access to models weights or are applied during finetuning, which are not applicable in few-shot learning. Do LLMs exhibit prediction biases when used for standard NLP tasks? In this work, we explore the effect of shots, which directly affect the performance of models, on the fairness of LLMs as NLP classification systems. We consider how different shot selection strategies, both existing and new demographically sensitive methods, affect model fairness across three standard fairness datasets. We discuss how future work can include LLM fairness evaluations.
Generalizing Fairness using Multi-Task Learning without Demographic Information
May 22, 2023To ensure the fairness of machine learning systems, we can include a fairness loss during training based on demographic information associated with the training data. However, we cannot train debiased classifiers for most tasks since the relevant datasets lack demographic annotations. Can we utilize demographic data for a related task to improve the fairness of our target task? We demonstrate that demographic fairness objectives transfer to new tasks trained within a multi-task framework. We adapt a single-task fairness loss to a multi-task setting to exploit demographic labels from a related task in debiasing a target task. We explore different settings with missing demographic data and show how our loss can improve fairness even without in-task demographics, across various domains and tasks.
Using Open-Ended Stressor Responses to Predict Depressive Symptoms across Demographics
Nov 15, 2022Stressors are related to depression, but this relationship is complex. We investigate the relationship between open-ended text responses about stressors and depressive symptoms across gender and racial/ethnic groups. First, we use topic models and other NLP tools to find thematic and vocabulary differences when reporting stressors across demographic groups. We train language models using self-reported stressors to predict depressive symptoms, finding a relationship between stressors and depression. Finally, we find that differences in stressors translate to downstream performance differences across demographic groups.
Gender and Racial Fairness in Depression Research using Social Media
Mar 18, 2021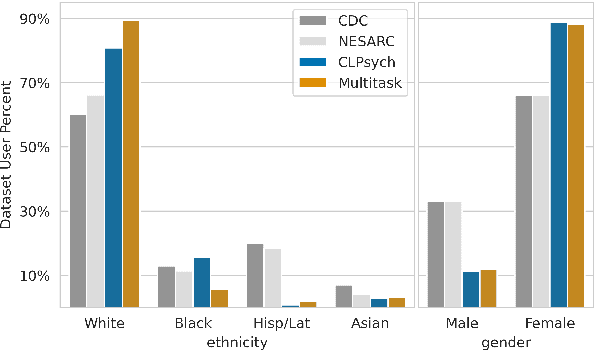
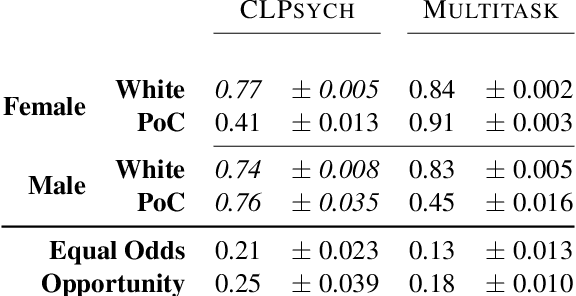
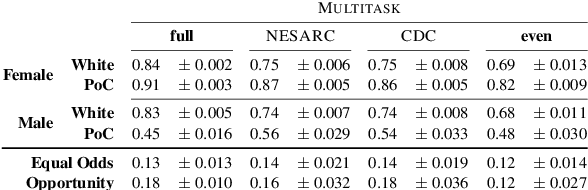
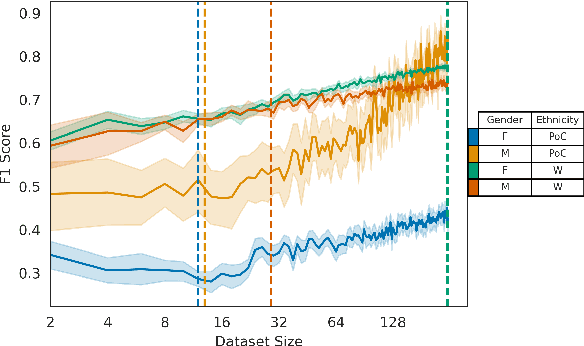
Multiple studies have demonstrated that behavior on internet-based social media platforms can be indicative of an individual's mental health status. The widespread availability of such data has spurred interest in mental health research from a computational lens. While previous research has raised concerns about possible biases in models produced from this data, no study has quantified how these biases actually manifest themselves with respect to different demographic groups, such as gender and racial/ethnic groups. Here, we analyze the fairness of depression classifiers trained on Twitter data with respect to gender and racial demographic groups. We find that model performance systematically differs for underrepresented groups and that these discrepancies cannot be fully explained by trivial data representation issues. Our study concludes with recommendations on how to avoid these biases in future research.
On the State of Social Media Data for Mental Health Research
Nov 10, 2020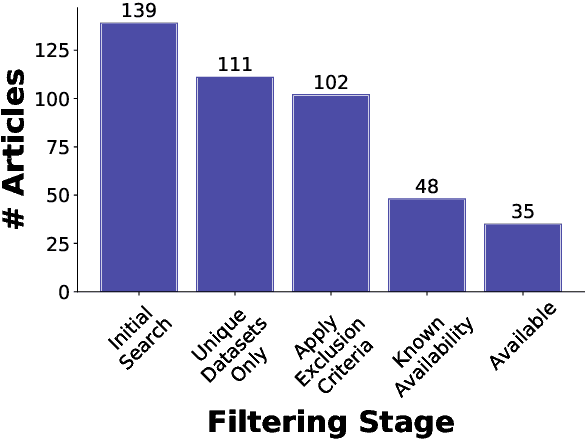
Data-driven methods for mental health treatment and surveillance have become a major focus in computational science research in the last decade. However, progress in the domain, in terms of both medical understanding and system performance, remains bounded by the availability of adequate data. Prior systematic reviews have not necessarily made it possible to measure the degree to which data-related challenges have affected research progress. In this paper, we offer an analysis specifically on the state of social media data that exists for conducting mental health research. We do so by introducing an open-source directory of mental health datasets, annotated using a standardized schema to facilitate meta-analysis.
Scalable End-to-end Recurrent Neural Network for Variable star classification
Feb 03, 2020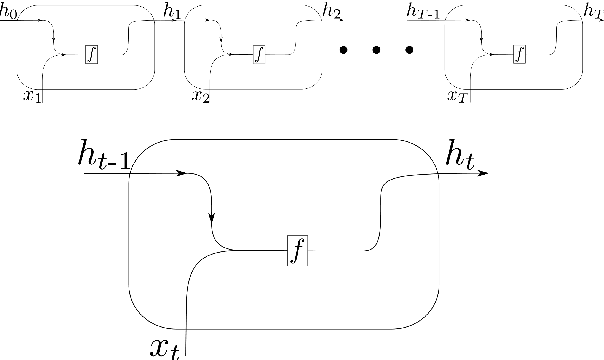

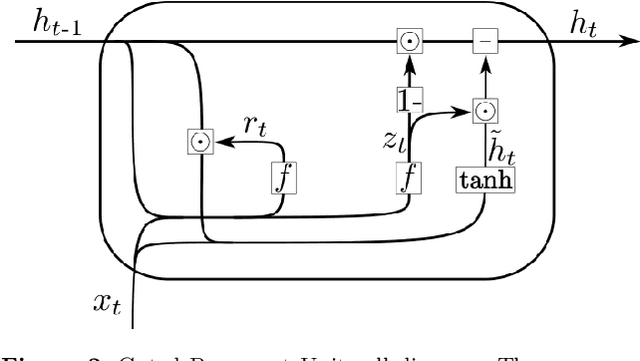
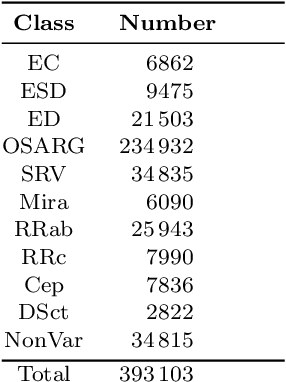
During the last decade, considerable effort has been made to perform automatic classification of variable stars using machine learning techniques. Traditionally, light curves are represented as a vector of descriptors or features used as input for many algorithms. Some features are computationally expensive, cannot be updated quickly and hence for large datasets such as the LSST cannot be applied. Previous work has been done to develop alternative unsupervised feature extraction algorithms for light curves, but the cost of doing so still remains high. In this work, we propose an end-to-end algorithm that automatically learns the representation of light curves that allows an accurate automatic classification. We study a series of deep learning architectures based on Recurrent Neural Networks and test them in automated classification scenarios. Our method uses minimal data preprocessing, can be updated with a low computational cost for new observations and light curves, and can scale up to massive datasets. We transform each light curve into an input matrix representation whose elements are the differences in time and magnitude, and the outputs are classification probabilities. We test our method in three surveys: OGLE-III, Gaia and WISE. We obtain accuracies of about $95\%$ in the main classes and $75\%$ in the majority of subclasses. We compare our results with the Random Forest classifier and obtain competitive accuracies while being faster and scalable. The analysis shows that the computational complexity of our approach grows up linearly with the light curve size, while the traditional approach cost grows as $N\log{(N)}$.
A Novel Approach for Detection and Ranking of Trendy and Emerging Cyber Threat Events in Twitter Streams
Jul 12, 2019

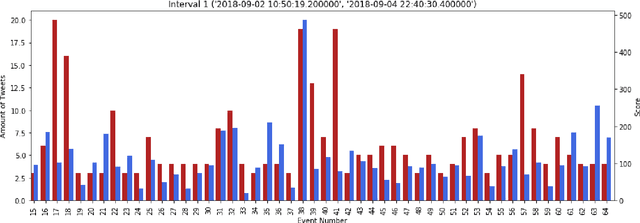
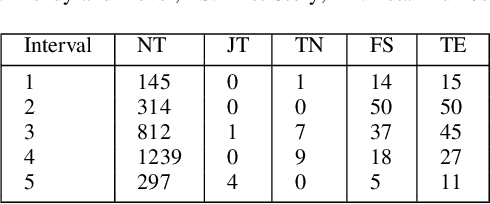
We present a new machine learning and text information extraction approach to detection of cyber threat events in Twitter that are novel (previously non-extant) and developing (marked by significance with respect to similarity with a previously detected event). While some existing approaches to event detection measure novelty and trendiness, typically as independent criteria and occasionally as a holistic measure, this work focuses on detecting both novel and developing events using an unsupervised machine learning approach. Furthermore, our proposed approach enables the ranking of cyber threat events based on an importance score by extracting the tweet terms that are characterized as named entities, keywords, or both. We also impute influence to users in order to assign a weighted score to noun phrases in proportion to user influence and the corresponding event scores for named entities and keywords. To evaluate the performance of our proposed approach, we measure the efficiency and detection error rate for events over a specified time interval, relative to human annotator ground truth.
Deep multi-survey classification of variable stars
Oct 21, 2018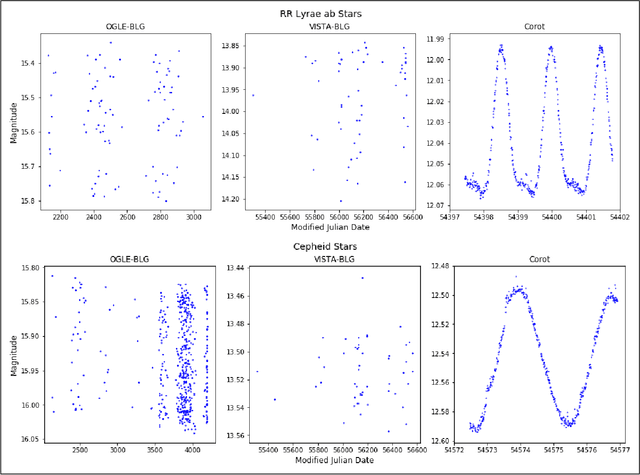
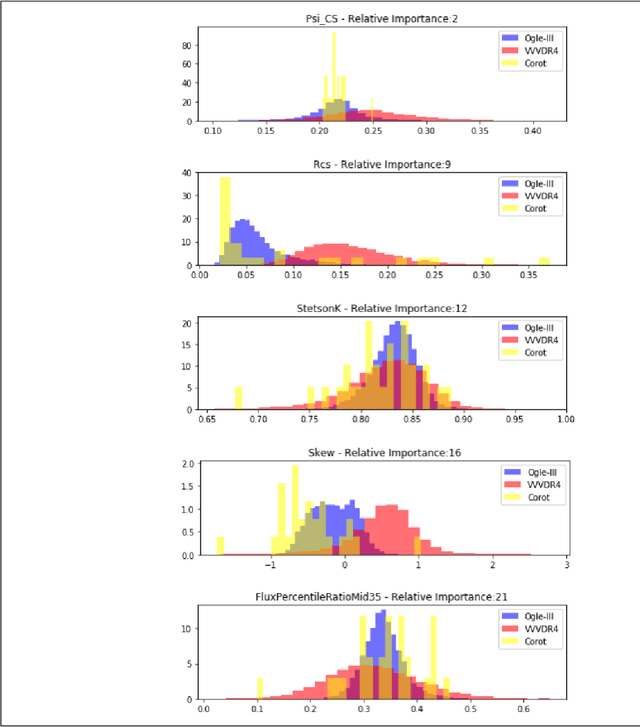
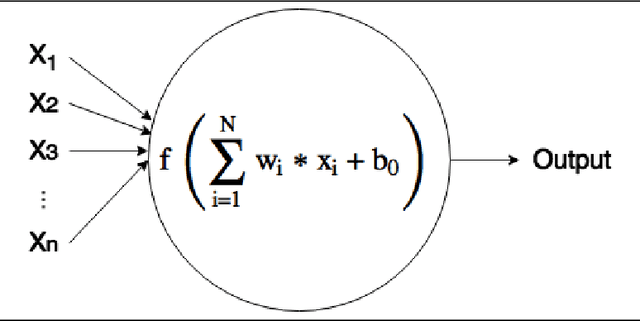
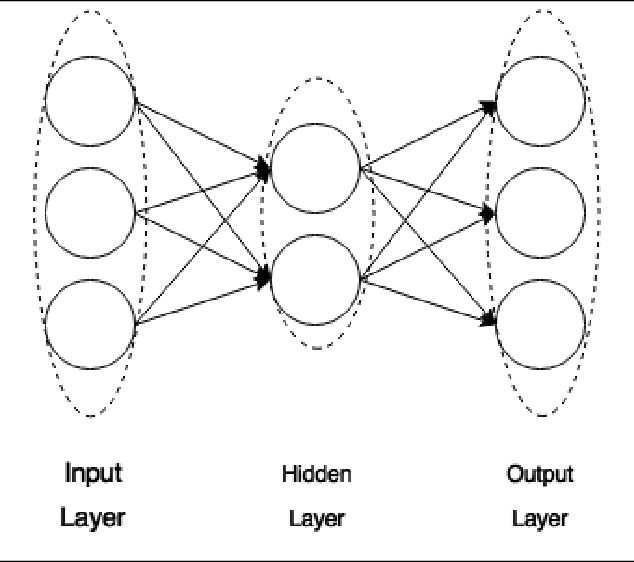
During the last decade, a considerable amount of effort has been made to classify variable stars using different machine learning techniques. Typically, light curves are represented as vectors of statistical descriptors or features that are used to train various algorithms. These features demand big computational powers that can last from hours to days, making impossible to create scalable and efficient ways of automatically classifying variable stars. Also, light curves from different surveys cannot be integrated and analyzed together when using features, because of observational differences. For example, having variations in cadence and filters, feature distributions become biased and require expensive data-calibration models. The vast amount of data that will be generated soon make necessary to develop scalable machine learning architectures without expensive integration techniques. Convolutional Neural Networks have shown impressing results in raw image classification and representation within the machine learning literature. In this work, we present a novel Deep Learning model for light curve classification, mainly based on convolutional units. Our architecture receives as input the differences between time and magnitude of light curves. It captures the essential classification patterns regardless of cadence and filter. In addition, we introduce a novel data augmentation schema for unevenly sampled time series. We test our method using three different surveys: OGLE-III; Corot; and VVV, which differ in filters, cadence, and area of the sky. We show that besides the benefit of scalability, our model obtains state of the art levels accuracy in light curve classification benchmarks.