 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Drug Effects from High-Dimensional, Asymmetric Drug Datasets by Using Graph Neural Networks: A Comprehensive Analysis of Multitarget Drug Effect Prediction
Oct 11, 2024



Graph neural networks (GNNs) have emerged as one of the most effective ML techniques for drug effect prediction from drug molecular graphs. Despite having immense potential, GNN models lack performance when using datasets that contain high-dimensional, asymmetrically co-occurrent drug effects as targets with complex correlations between them. Training individual learning models for each drug effect and incorporating every prediction result for a wide spectrum of drug effects are impractical. Therefore, an opportunity exists to address this challenge as multitarget prediction problems and predict all drug effects at a time. We developed standard and hybrid GNNs to perform two separate tasks: multiregression for continuous values and multilabel classification for categorical values contained in our datasets. Because multilabel classification makes the target data even more sparse and introduces asymmetric label co-occurrence, learning these models becomes difficult and heavily impacts the GNN's performance. To address these challenges, we propose a new data oversampling technique to improve multilabel classification performances on all the given imbalanced molecular graph datasets. Using the technique, we improve the data imbalance ratio of the drug effects while protecting the datasets' integrity. Finally, we evaluate the multilabel classification performance of the best-performing hybrid GNN model on all the oversampled datasets obtained from the proposed oversampling technique. In all the evaluation metrics (i.e., precision, recall, and F1 score), this model significantly outperforms other ML models, including GNN models when they are trained on the original datasets or oversampled datasets with MLSMOTE, which is a well-known oversampling technique.
Correlating Power Outage Spread with Infrastructure Interdependencies During Hurricanes
Jul 13, 2024Power outages caused by extreme weather events, such as hurricanes, can significantly disrupt essential services and delay recovery efforts, underscoring the importance of enhancing our infrastructure's resilience. This study investigates the spread of power outages during hurricanes by analyzing the correlation between the network of critical infrastructure and outage propagation. We leveraged datasets from Hurricanemapping.com, the North American Energy Resilience Model Interdependency Analysis (NAERM-IA), and historical power outage data from the Oak Ridge National Laboratory (ORNL)'s EAGLE-I system. Our analysis reveals a consistent positive correlation between the extent of critical infrastructure components accessible within a certain number of steps (k-hop distance) from initial impact areas and the occurrence of power outages in broader regions. This insight suggests that understanding the interconnectedness among critical infrastructure elements is key to identifying areas indirectly affected by extreme weather events.
Feature Selection for Learning to Predict Outcomes of Compute Cluster Jobs with Application to Decision Support
Dec 14, 2020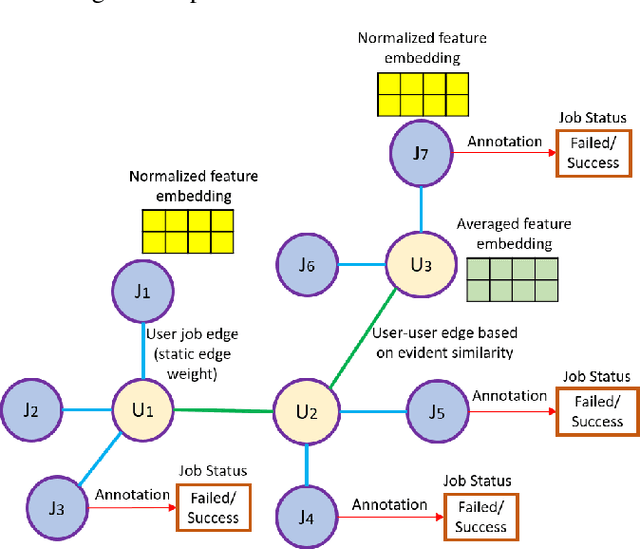

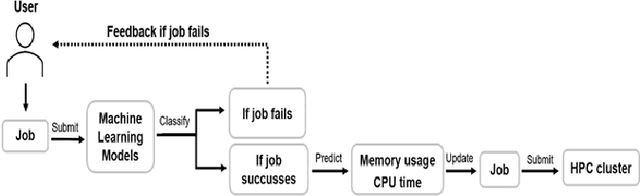
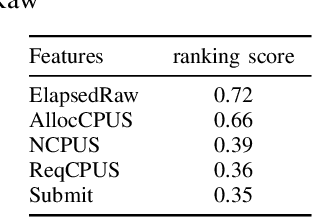
We present a machine learning framework and a new test bed for data mining from the Slurm Workload Manager for high-performance computing (HPC) clusters. The focus was to find a method for selecting features to support decisions: helping users decide whether to resubmit failed jobs with boosted CPU and memory allocations or migrate them to a computing cloud. This task was cast as both supervised classification and regression learning, specifically, sequential problem solving suitable for reinforcement learning. Selecting relevant features can improve training accuracy, reduce training time, and produce a more comprehensible model, with an intelligent system that can explain predictions and inferences. We present a supervised learning model trained on a Simple Linux Utility for Resource Management (Slurm) data set of HPC jobs using three different techniques for selecting features: linear regression, lasso, and ridge regression. Our data set represented both HPC jobs that failed and those that succeeded, so our model was reliable, less likely to overfit, and generalizable. Our model achieved an R^2 of 95\% with 99\% accuracy. We identified five predictors for both CPU and memory properties.
A Novel Approach for Detection and Ranking of Trendy and Emerging Cyber Threat Events in Twitter Streams
Jul 12, 2019

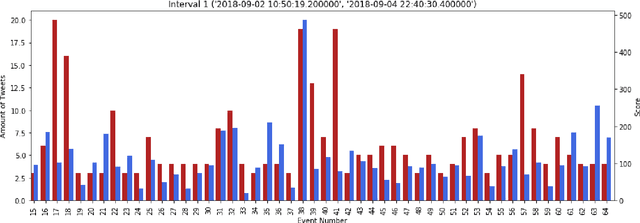
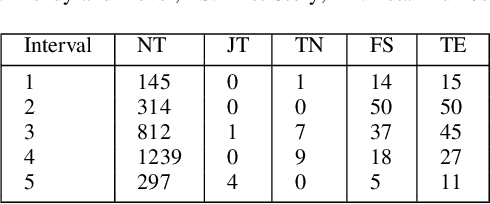
We present a new machine learning and text information extraction approach to detection of cyber threat events in Twitter that are novel (previously non-extant) and developing (marked by significance with respect to similarity with a previously detected event). While some existing approaches to event detection measure novelty and trendiness, typically as independent criteria and occasionally as a holistic measure, this work focuses on detecting both novel and developing events using an unsupervised machine learning approach. Furthermore, our proposed approach enables the ranking of cyber threat events based on an importance score by extracting the tweet terms that are characterized as named entities, keywords, or both. We also impute influence to users in order to assign a weighted score to noun phrases in proportion to user influence and the corresponding event scores for named entities and keywords. To evaluate the performance of our proposed approach, we measure the efficiency and detection error rate for events over a specified time interval, relative to human annotator ground truth.
A Comparative Quantitative Analysis of Contemporary Big Data Clustering Algorithms for Market Segmentation in Hospitality Industry
Sep 18, 2017

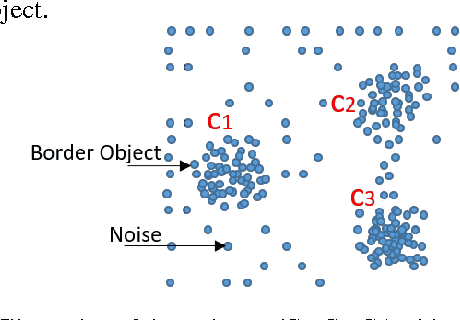
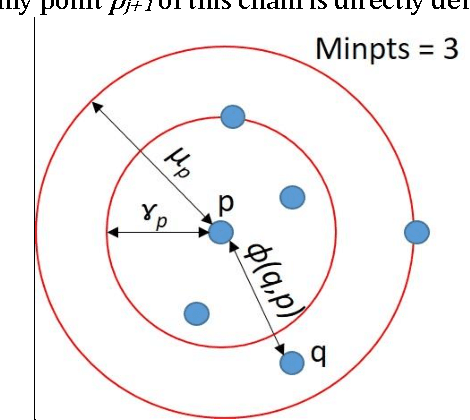
The hospitality industry is one of the data-rich industries that receives huge Volumes of data streaming at high Velocity with considerably Variety, Veracity, and Variability. These properties make the data analysis in the hospitality industry a big data problem. Meeting the customers' expectations is a key factor in the hospitality industry to grasp the customers' loyalty. To achieve this goal, marketing professionals in this industry actively look for ways to utilize their data in the best possible manner and advance their data analytic solutions, such as identifying a unique market segmentation clustering and developing a recommendation system. In this paper, we present a comprehensive literature review of existing big data clustering algorithms and their advantages and disadvantages for various use cases. We implement the existing big data clustering algorithms and provide a quantitative comparison of the performance of different clustering algorithms for different scenarios. We also present our insights and recommendations regarding the suitability of different big data clustering algorithms for different use cases. These recommendations will be helpful for hoteliers in selecting the appropriate market segmentation clustering algorithm for different clustering datasets to improve the customer experience and maximize the hotel revenue.