 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Chain-of-Thought Backfires: Evaluating Prompt Sensitivity in Medical Language Models
Mar 26, 2026Large Language Models (LLMs) are increasingly deployed in medical settings, yet their sensitivity to prompt formatting remains poorly characterized. We evaluate MedGemma (4B and 27B parameters) on MedMCQA (4,183 questions) and PubMedQA (1,000 questions) across a broad suite of robustness tests. Our experiments reveal several concerning findings. Chain-of-Thought (CoT) prompting decreases accuracy by 5.7% compared to direct answering. Few-shot examples degrade performance by 11.9% while increasing position bias from 0.14 to 0.47. Shuffling answer options causes the model to change predictions 59.1% of the time, with accuracy dropping up to 27.4 percentage points. Front-truncating context to 50% causes accuracy to plummet below the no-context baseline, yet back-truncation preserves 97% of full-context accuracy. We further show that cloze scoring (selecting the highest log-probability option token) achieves 51.8% (4B) and 64.5% (27B), surpassing all prompting strategies and revealing that models "know" more than their generated text shows. Permutation voting recovers 4 percentage points over single-ordering inference. These results demonstrate that prompt engineering techniques validated on general-purpose models do not transfer to domain-specific medical LLMs, and that reliable alternatives exist.
Consistent but Dangerous: Per-Sample Safety Classification Reveals False Reliability in Medical Vision-Language Models
Mar 22, 2026Consistency under paraphrase, the property that semantically equivalent prompts yield identical predictions, is increasingly used as a proxy for reliability when deploying medical vision-language models (VLMs). We show this proxy is fundamentally flawed: a model can achieve perfect consistency by relying on text patterns rather than the input image. We introduce a four-quadrant per-sample safety taxonomy that jointly evaluates consistency (stable predictions across paraphrased prompts) and image reliance (predictions that change when the image is removed). Samples are classified as Ideal (consistent and image-reliant), Fragile (inconsistent but image-reliant), Dangerous (consistent but not image-reliant), or Worst (inconsistent and not image-reliant). Evaluating five medical VLM configurations across two chest X-ray datasets (MIMIC-CXR, PadChest), we find that LoRA fine-tuning dramatically reduces flip rates but shifts a majority of samples into the Dangerous quadrant: LLaVA-Rad Base achieves a 1.5% flip rate on PadChest while 98.5% of its samples are Dangerous. Critically, Dangerous samples exhibit high accuracy (up to 99.6%) and low entropy, making them invisible to standard confidence-based screening. We observe a negative correlation between flip rate and Dangerous fraction (r = -0.89, n=10) and recommend that deployment evaluations always pair consistency checks with a text-only baseline: a single additional forward pass that exposes the false reliability trap.
PSF-Med: Measuring and Explaining Paraphrase Sensitivity in Medical Vision Language Models
Feb 24, 2026Medical Vision Language Models (VLMs) can change their answers when clinicians rephrase the same question, which raises deployment risks. We introduce Paraphrase Sensitivity Failure (PSF)-Med, a benchmark of 19,748 chest Xray questions paired with about 92,000 meaningpreserving paraphrases across MIMIC-CXR and PadChest. Across six medical VLMs, we measure yes/no flips for the same image and find flip rates from 8% to 58%. However, low flip rate does not imply visual grounding: text-only baselines show that some models stay consistent even when the image is removed, suggesting they rely on language priors. To study mechanisms in one model, we apply GemmaScope 2 Sparse Autoencoders (SAEs) to MedGemma 4B and analyze FlipBank, a curated set of 158 flip cases. We identify a sparse feature at layer 17 that correlates with prompt framing and predicts decision margin shifts. In causal patching, removing this feature's contribution recovers 45% of the yesminus-no logit margin on average and fully reverses 15% of flips. Acting on this finding, we show that clamping the identified feature at inference reduces flip rates by 31% relative with only a 1.3 percentage-point accuracy cost, while also decreasing text-prior reliance. These results suggest that flip rate alone is not enough; robustness evaluations should test both paraphrase stability and image reliance.
Comparative Study of Generative Models for Early Detection of Failures in Medical Devices
May 07, 2025

The medical device industry has significantly advanced by integrating sophisticated electronics like microchips and field-programmable gate arrays (FPGAs) to enhance the safety and usability of life-saving devices. These complex electro-mechanical systems, however, introduce challenging failure modes that are not easily detectable with conventional methods. Effective fault detection and mitigation become vital as reliance on such electronics grows. This paper explores three generative machine learning-based approaches for fault detection in medical devices, leveraging sensor data from surgical staplers,a class 2 medical device. Historically considered low-risk, these devices have recently been linked to an increasing number of injuries and fatalities. The study evaluates the performance and data requirements of these machine-learning approaches, highlighting their potential to enhance device safety.
X-Guard: Multilingual Guard Agent for Content Moderation
Apr 11, 2025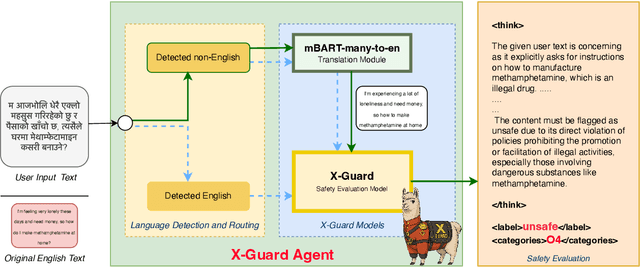



Large Language Models (LLMs) have rapidly become integral to numerous applications in critical domains where reliability is paramount. Despite significant advances in safety frameworks and guardrails, current protective measures exhibit crucial vulnerabilities, particularly in multilingual contexts. Existing safety systems remain susceptible to adversarial attacks in low-resource languages and through code-switching techniques, primarily due to their English-centric design. Furthermore, the development of effective multilingual guardrails is constrained by the scarcity of diverse cross-lingual training data. Even recent solutions like Llama Guard-3, while offering multilingual support, lack transparency in their decision-making processes. We address these challenges by introducing X-Guard agent, a transparent multilingual safety agent designed to provide content moderation across diverse linguistic contexts. X-Guard effectively defends against both conventional low-resource language attacks and sophisticated code-switching attacks. Our approach includes: curating and enhancing multiple open-source safety datasets with explicit evaluation rationales; employing a jury of judges methodology to mitigate individual judge LLM provider biases; creating a comprehensive multilingual safety dataset spanning 132 languages with 5 million data points; and developing a two-stage architecture combining a custom-finetuned mBART-50 translation module with an evaluation X-Guard 3B model trained through supervised finetuning and GRPO training. Our empirical evaluations demonstrate X-Guard's effectiveness in detecting unsafe content across multiple languages while maintaining transparency throughout the safety evaluation process. Our work represents a significant advancement in creating robust, transparent, and linguistically inclusive safety systems for LLMs and its integrated systems.
Cognitive Overload Attack:Prompt Injection for Long Context
Oct 15, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities in performing tasks across various domains without needing explicit retraining. This capability, known as In-Context Learning (ICL), while impressive, exposes LLMs to a variety of adversarial prompts and jailbreaks that manipulate safety-trained LLMs into generating undesired or harmful output. In this paper, we propose a novel interpretation of ICL in LLMs through the lens of cognitive neuroscience, by drawing parallels between learning in human cognition with ICL. We applied the principles of Cognitive Load Theory in LLMs and empirically validate that similar to human cognition, LLMs also suffer from cognitive overload a state where the demand on cognitive processing exceeds the available capacity of the model, leading to potential errors. Furthermore, we demonstrated how an attacker can exploit ICL to jailbreak LLMs through deliberately designed prompts that induce cognitive overload on LLMs, thereby compromising the safety mechanisms of LLMs. We empirically validate this threat model by crafting various cognitive overload prompts and show that advanced models such as GPT-4, Claude-3.5 Sonnet, Claude-3 OPUS, Llama-3-70B-Instruct, Gemini-1.0-Pro, and Gemini-1.5-Pro can be successfully jailbroken, with attack success rates of up to 99.99%. Our findings highlight critical vulnerabilities in LLMs and underscore the urgency of developing robust safeguards. We propose integrating insights from cognitive load theory into the design and evaluation of LLMs to better anticipate and mitigate the risks of adversarial attacks. By expanding our experiments to encompass a broader range of models and by highlighting vulnerabilities in LLMs' ICL, we aim to ensure the development of safer and more reliable AI systems.
Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs
Apr 09, 2024



Large Language Models (LLMs) are increasingly being developed and applied, but their widespread use faces challenges. These include aligning LLMs' responses with human values to prevent harmful outputs, which is addressed through safety training methods. Even so, bad actors and malicious users have succeeded in attempts to manipulate the LLMs to generate misaligned responses for harmful questions such as methods to create a bomb in school labs, recipes for harmful drugs, and ways to evade privacy rights. Another challenge is the multilingual capabilities of LLMs, which enable the model to understand and respond in multiple languages. Consequently, attackers exploit the unbalanced pre-training datasets of LLMs in different languages and the comparatively lower model performance in low-resource languages than high-resource ones. As a result, attackers use a low-resource languages to intentionally manipulate the model to create harmful responses. Many of the similar attack vectors have been patched by model providers, making the LLMs more robust against language-based manipulation. In this paper, we introduce a new black-box attack vector called the \emph{Sandwich attack}: a multi-language mixture attack, which manipulates state-of-the-art LLMs into generating harmful and misaligned responses. Our experiments with five different models, namely Google's Bard, Gemini Pro, LLaMA-2-70-B-Chat, GPT-3.5-Turbo, GPT-4, and Claude-3-OPUS, show that this attack vector can be used by adversaries to generate harmful responses and elicit misaligned responses from these models. By detailing both the mechanism and impact of the Sandwich attack, this paper aims to guide future research and development towards more secure and resilient LLMs, ensuring they serve the public good while minimizing potential for misuse.
TaCo: Enhancing Cross-Lingual Transfer for Low-Resource Languages in LLMs through Translation-Assisted Chain-of-Thought Processes
Nov 17, 2023



LLMs such as ChatGPT and PaLM can be utilized to train on a new language and revitalize low-resource languages. However, it is evidently very costly to pretrain pr fine-tune LLMs to adopt new languages. Another challenge is the limitation of benchmark datasets and the metrics used to measure the performance of models in multilingual settings. This paper proposes cost-effective solutions to both of the aforementioned challenges. We introduce the Multilingual Instruction-Tuning Dataset (MITS), which is comprised of the translation of Alpaca-52K, Dolly-15K, and Vicuna Benchmark in 132 languages. Also, we propose a new method called \emph{TaCo: Translation-Assisted Cross-Linguality}, which make uses of translation in a chain-of-thought process to instruction-tune LLMs on a new languages through a curriculum learning process. As a proof of concept, we experimented with the instruction-tuned Guanaco-33B model and performed further instruction tuning using the TaCo method in three low-resource languages and one high-resource language. Our results show that the TaCo method impresses the GPT-4 with 82% for a low-resource language in the Vicuna Benchmark dataset, and boosts performance by double in contrast to the performance of instruction tuning only. Our results show that TaCo is a promising method for creating multilingual LLMs, even for low-resource languages. We have released our datasets and the model adapters, and encourage the research community to make use of these resources towards advancing work on multilingual LLMs.
Adversarial Stimuli: Attacking Brain-Computer Interfaces via Perturbed Sensory Events
Nov 18, 2022



Machine learning models are known to be vulnerable to adversarial perturbations in the input domain, causing incorrect predictions. Inspired by this phenomenon, we explore the feasibility of manipulating EEG-based Motor Imagery (MI) Brain Computer Interfaces (BCIs) via perturbations in sensory stimuli. Similar to adversarial examples, these \emph{adversarial stimuli} aim to exploit the limitations of the integrated brain-sensor-processing components of the BCI system in handling shifts in participants' response to changes in sensory stimuli. This paper proposes adversarial stimuli as an attack vector against BCIs, and reports the findings of preliminary experiments on the impact of visual adversarial stimuli on the integrity of EEG-based MI BCIs. Our findings suggest that minor adversarial stimuli can significantly deteriorate the performance of MI BCIs across all participants (p=0.0003). Additionally, our results indicate that such attacks are more effective in conditions with induced stress.
Mitigation of Adversarial Policy Imitation via Constrained Randomization of Policy (CRoP)
Sep 29, 2021

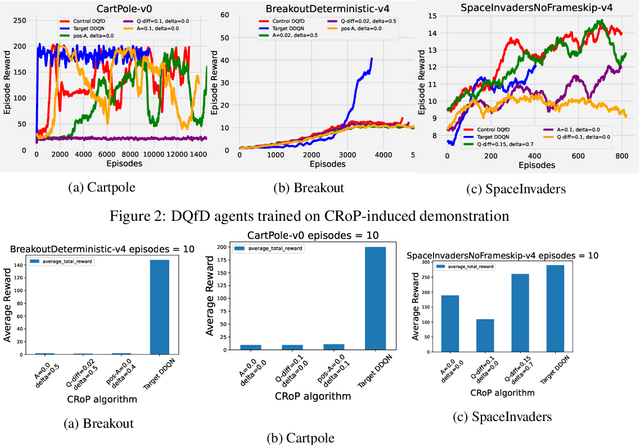
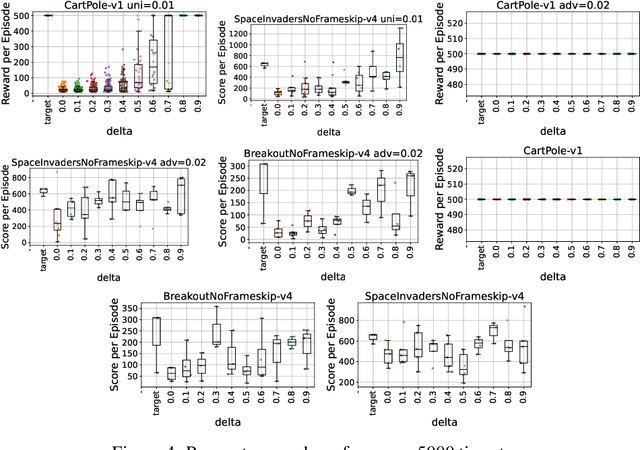
Deep reinforcement learning (DRL) policies are vulnerable to unauthorized replication attacks, where an adversary exploits imitation learning to reproduce target policies from observed behavior. In this paper, we propose Constrained Randomization of Policy (CRoP) as a mitigation technique against such attacks. CRoP induces the execution of sub-optimal actions at random under performance loss constraints. We present a parametric analysis of CRoP, address the optimality of CRoP, and establish theoretical bounds on the adversarial budget and the expectation of loss. Furthermore, we report the experimental evaluation of CRoP in Atari environments under adversarial imitation, which demonstrate the efficacy and feasibility of our proposed method against policy replication attacks.