 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Guard: Multilingual Guard Agent for Content Moderation
Apr 11, 2025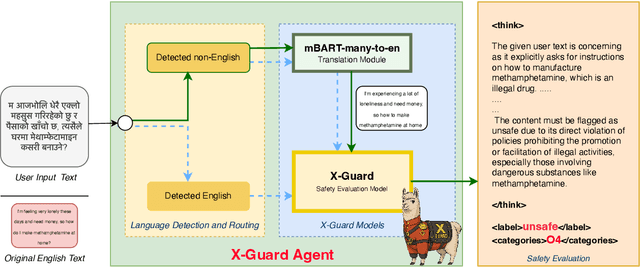



Large Language Models (LLMs) have rapidly become integral to numerous applications in critical domains where reliability is paramount. Despite significant advances in safety frameworks and guardrails, current protective measures exhibit crucial vulnerabilities, particularly in multilingual contexts. Existing safety systems remain susceptible to adversarial attacks in low-resource languages and through code-switching techniques, primarily due to their English-centric design. Furthermore, the development of effective multilingual guardrails is constrained by the scarcity of diverse cross-lingual training data. Even recent solutions like Llama Guard-3, while offering multilingual support, lack transparency in their decision-making processes. We address these challenges by introducing X-Guard agent, a transparent multilingual safety agent designed to provide content moderation across diverse linguistic contexts. X-Guard effectively defends against both conventional low-resource language attacks and sophisticated code-switching attacks. Our approach includes: curating and enhancing multiple open-source safety datasets with explicit evaluation rationales; employing a jury of judges methodology to mitigate individual judge LLM provider biases; creating a comprehensive multilingual safety dataset spanning 132 languages with 5 million data points; and developing a two-stage architecture combining a custom-finetuned mBART-50 translation module with an evaluation X-Guard 3B model trained through supervised finetuning and GRPO training. Our empirical evaluations demonstrate X-Guard's effectiveness in detecting unsafe content across multiple languages while maintaining transparency throughout the safety evaluation process. Our work represents a significant advancement in creating robust, transparent, and linguistically inclusive safety systems for LLMs and its integrated systems.
Cognitive Overload Attack:Prompt Injection for Long Context
Oct 15, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities in performing tasks across various domains without needing explicit retraining. This capability, known as In-Context Learning (ICL), while impressive, exposes LLMs to a variety of adversarial prompts and jailbreaks that manipulate safety-trained LLMs into generating undesired or harmful output. In this paper, we propose a novel interpretation of ICL in LLMs through the lens of cognitive neuroscience, by drawing parallels between learning in human cognition with ICL. We applied the principles of Cognitive Load Theory in LLMs and empirically validate that similar to human cognition, LLMs also suffer from cognitive overload a state where the demand on cognitive processing exceeds the available capacity of the model, leading to potential errors. Furthermore, we demonstrated how an attacker can exploit ICL to jailbreak LLMs through deliberately designed prompts that induce cognitive overload on LLMs, thereby compromising the safety mechanisms of LLMs. We empirically validate this threat model by crafting various cognitive overload prompts and show that advanced models such as GPT-4, Claude-3.5 Sonnet, Claude-3 OPUS, Llama-3-70B-Instruct, Gemini-1.0-Pro, and Gemini-1.5-Pro can be successfully jailbroken, with attack success rates of up to 99.99%. Our findings highlight critical vulnerabilities in LLMs and underscore the urgency of developing robust safeguards. We propose integrating insights from cognitive load theory into the design and evaluation of LLMs to better anticipate and mitigate the risks of adversarial attacks. By expanding our experiments to encompass a broader range of models and by highlighting vulnerabilities in LLMs' ICL, we aim to ensure the development of safer and more reliable AI systems.
Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs
Apr 09, 2024



Large Language Models (LLMs) are increasingly being developed and applied, but their widespread use faces challenges. These include aligning LLMs' responses with human values to prevent harmful outputs, which is addressed through safety training methods. Even so, bad actors and malicious users have succeeded in attempts to manipulate the LLMs to generate misaligned responses for harmful questions such as methods to create a bomb in school labs, recipes for harmful drugs, and ways to evade privacy rights. Another challenge is the multilingual capabilities of LLMs, which enable the model to understand and respond in multiple languages. Consequently, attackers exploit the unbalanced pre-training datasets of LLMs in different languages and the comparatively lower model performance in low-resource languages than high-resource ones. As a result, attackers use a low-resource languages to intentionally manipulate the model to create harmful responses. Many of the similar attack vectors have been patched by model providers, making the LLMs more robust against language-based manipulation. In this paper, we introduce a new black-box attack vector called the \emph{Sandwich attack}: a multi-language mixture attack, which manipulates state-of-the-art LLMs into generating harmful and misaligned responses. Our experiments with five different models, namely Google's Bard, Gemini Pro, LLaMA-2-70-B-Chat, GPT-3.5-Turbo, GPT-4, and Claude-3-OPUS, show that this attack vector can be used by adversaries to generate harmful responses and elicit misaligned responses from these models. By detailing both the mechanism and impact of the Sandwich attack, this paper aims to guide future research and development towards more secure and resilient LLMs, ensuring they serve the public good while minimizing potential for misuse.
TaCo: Enhancing Cross-Lingual Transfer for Low-Resource Languages in LLMs through Translation-Assisted Chain-of-Thought Processes
Nov 17, 2023



LLMs such as ChatGPT and PaLM can be utilized to train on a new language and revitalize low-resource languages. However, it is evidently very costly to pretrain pr fine-tune LLMs to adopt new languages. Another challenge is the limitation of benchmark datasets and the metrics used to measure the performance of models in multilingual settings. This paper proposes cost-effective solutions to both of the aforementioned challenges. We introduce the Multilingual Instruction-Tuning Dataset (MITS), which is comprised of the translation of Alpaca-52K, Dolly-15K, and Vicuna Benchmark in 132 languages. Also, we propose a new method called \emph{TaCo: Translation-Assisted Cross-Linguality}, which make uses of translation in a chain-of-thought process to instruction-tune LLMs on a new languages through a curriculum learning process. As a proof of concept, we experimented with the instruction-tuned Guanaco-33B model and performed further instruction tuning using the TaCo method in three low-resource languages and one high-resource language. Our results show that the TaCo method impresses the GPT-4 with 82% for a low-resource language in the Vicuna Benchmark dataset, and boosts performance by double in contrast to the performance of instruction tuning only. Our results show that TaCo is a promising method for creating multilingual LLMs, even for low-resource languages. We have released our datasets and the model adapters, and encourage the research community to make use of these resources towards advancing work on multilingual LLMs.
Adversarial Stimuli: Attacking Brain-Computer Interfaces via Perturbed Sensory Events
Nov 18, 2022



Machine learning models are known to be vulnerable to adversarial perturbations in the input domain, causing incorrect predictions. Inspired by this phenomenon, we explore the feasibility of manipulating EEG-based Motor Imagery (MI) Brain Computer Interfaces (BCIs) via perturbations in sensory stimuli. Similar to adversarial examples, these \emph{adversarial stimuli} aim to exploit the limitations of the integrated brain-sensor-processing components of the BCI system in handling shifts in participants' response to changes in sensory stimuli. This paper proposes adversarial stimuli as an attack vector against BCIs, and reports the findings of preliminary experiments on the impact of visual adversarial stimuli on the integrity of EEG-based MI BCIs. Our findings suggest that minor adversarial stimuli can significantly deteriorate the performance of MI BCIs across all participants (p=0.0003). Additionally, our results indicate that such attacks are more effective in conditions with induced stress.
Sentimental LIAR: Extended Corpus and Deep Learning Models for Fake Claim Classification
Sep 01, 2020
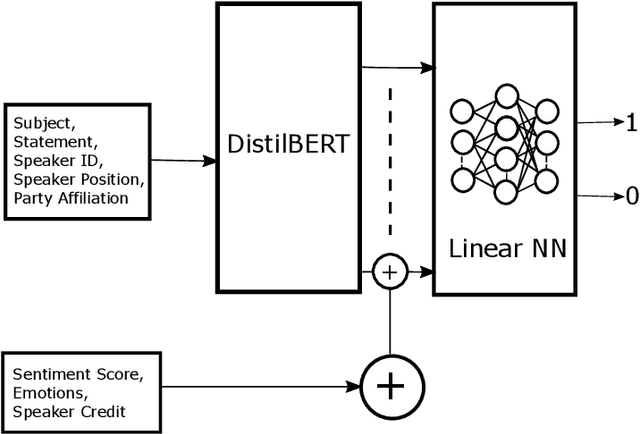
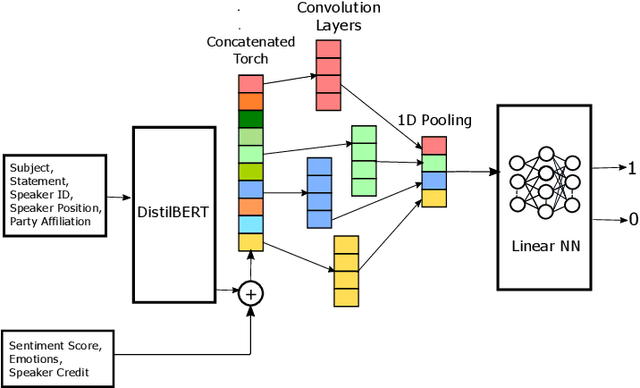
The rampant integration of social media in our every day lives and culture has given rise to fast and easier access to the flow of information than ever in human history. However, the inherently unsupervised nature of social media platforms has also made it easier to spread false information and fake news. Furthermore, the high volume and velocity of information flow in such platforms make manual supervision and control of information propagation infeasible. This paper aims to address this issue by proposing a novel deep learning approach for automated detection of false short-text claims on social media. We first introduce Sentimental LIAR, which extends the LIAR dataset of short claims by adding features based on sentiment and emotion analysis of claims. Furthermore, we propose a novel deep learning architecture based on the DistilBERT language model for classification of claims as genuine or fake. Our results demonstrate that the proposed architecture trained on Sentimental LIAR can achieve an accuracy of 70\%, which is an improvement of ~30\% over previously reported results for the LIAR benchmark.