 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Layout Detection from Scientific Literature using Recurrent Convolutional Neural Networks
Oct 18, 2020

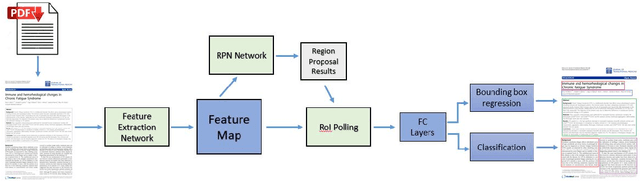

We present an approach for adapting convolutional neural networks for object recognition and classification to scientific literature layout detection (SLLD), a shared subtask of several information extraction problems. Scientific publications contain multiple types of information sought by researchers in various disciplines, organized into an abstract, bibliography, and sections documenting related work, experimental methods, and results; however, there is no effective way to extract this information due to their diverse layout. In this paper, we present a novel approach to developing an end-to-end learning framework to segment and classify major regions of a scientific document. We consider scientific document layout analysis as an object detection task over digital images, without any additional text features that need to be added into the network during the training process. Our technical objective is to implement transfer learning via fine-tuning of pre-trained networks and thereby demonstrate that this deep learning architecture is suitable for tasks that lack very large document corpora for training ab initio. As part of the experimental test bed for empirical evaluation of this approach, we created a merged multi-corpus data set for scientific publication layout detection tasks. Our results show good improvement with fine-tuning of a pre-trained base network using this merged data set, compared to the baseline convolutional neural network architecture.
* 8 pages
Pipelines for Procedural Information Extraction from Scientific Literature: Towards Recipes using Machine Learning and Data Science
Dec 16, 2019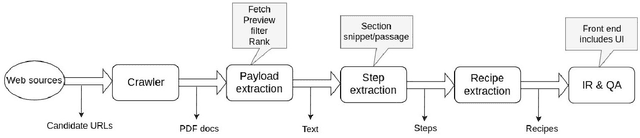
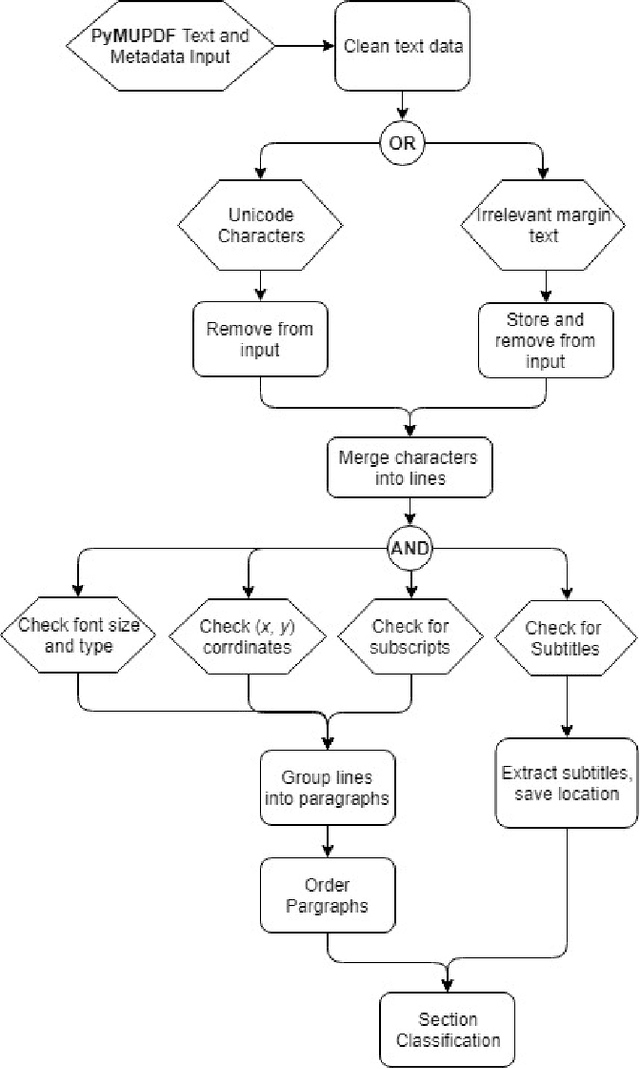
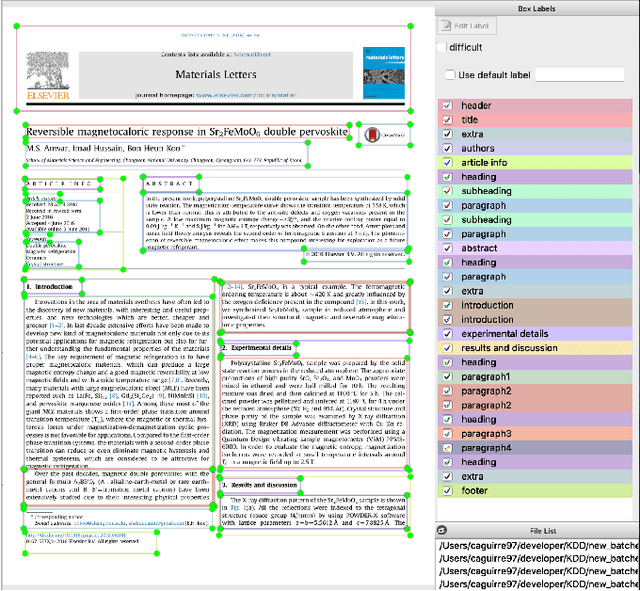

This paper describes a machine learning and data science pipeline for structured information extraction from documents, implemented as a suite of open-source tools and extensions to existing tools. It centers around a methodology for extracting procedural information in the form of recipes, stepwise procedures for creating an artifact (in this case synthesizing a nanomaterial), from published scientific literature. From our overall goal of producing recipes from free text, we derive the technical objectives of a system consisting of pipeline stages: document acquisition and filtering, payload extraction, recipe step extraction as a relationship extraction task, recipe assembly, and presentation through an information retrieval interface with question answering (QA) functionality. This system meets computational information and knowledge management (CIKM) requirements of metadata-driven payload extraction, named entity extraction, and relationship extraction from text. Functional contributions described in this paper include semi-supervised machine learning methods for PDF filtering and payload extraction tasks, followed by structured extraction and data transformation tasks beginning with section extraction, recipe steps as information tuples, and finally assembled recipes. Measurable objective criteria for extraction quality include precision and recall of recipe steps, ordering constraints, and QA accuracy, precision, and recall. Results, key novel contributions, and significant open problems derived from this work center around the attribution of these holistic quality measures to specific machine learning and inference stages of the pipeline, each with their performance measures. The desired recipes contain identified preconditions, material inputs, and operations, and constitute the overall output generated by our computational information and knowledge management (CIKM) system.
A Novel Approach for Detection and Ranking of Trendy and Emerging Cyber Threat Events in Twitter Streams
Jul 12, 2019

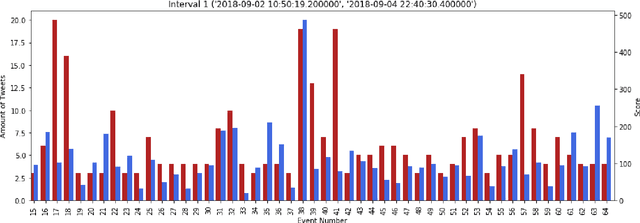
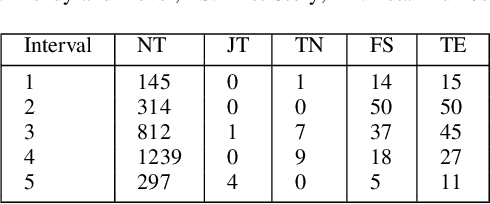
We present a new machine learning and text information extraction approach to detection of cyber threat events in Twitter that are novel (previously non-extant) and developing (marked by significance with respect to similarity with a previously detected event). While some existing approaches to event detection measure novelty and trendiness, typically as independent criteria and occasionally as a holistic measure, this work focuses on detecting both novel and developing events using an unsupervised machine learning approach. Furthermore, our proposed approach enables the ranking of cyber threat events based on an importance score by extracting the tweet terms that are characterized as named entities, keywords, or both. We also impute influence to users in order to assign a weighted score to noun phrases in proportion to user influence and the corresponding event scores for named entities and keywords. To evaluate the performance of our proposed approach, we measure the efficiency and detection error rate for events over a specified time interval, relative to human annotator ground truth.