 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Learning to Predict Outcomes of Compute Cluster Jobs with Application to Decision Support
Dec 14, 2020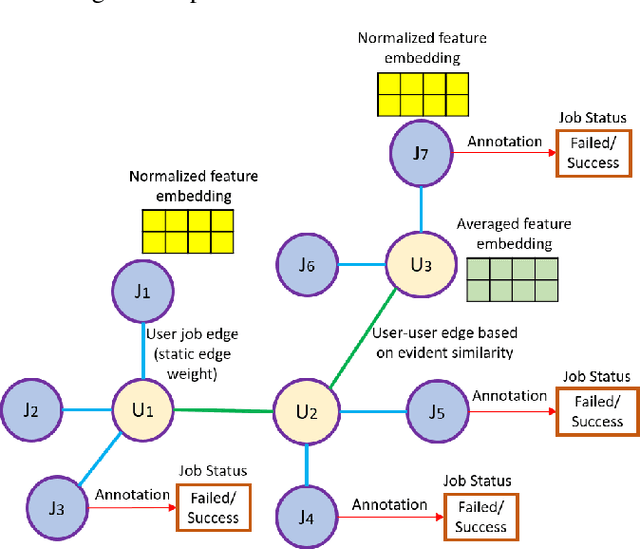

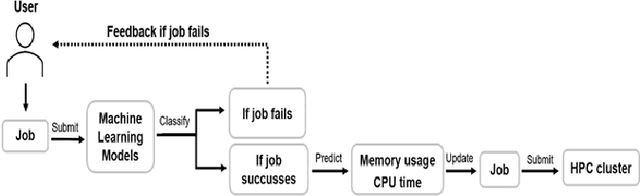
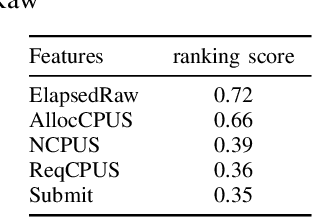
We present a machine learning framework and a new test bed for data mining from the Slurm Workload Manager for high-performance computing (HPC) clusters. The focus was to find a method for selecting features to support decisions: helping users decide whether to resubmit failed jobs with boosted CPU and memory allocations or migrate them to a computing cloud. This task was cast as both supervised classification and regression learning, specifically, sequential problem solving suitable for reinforcement learning. Selecting relevant features can improve training accuracy, reduce training time, and produce a more comprehensible model, with an intelligent system that can explain predictions and inferences. We present a supervised learning model trained on a Simple Linux Utility for Resource Management (Slurm) data set of HPC jobs using three different techniques for selecting features: linear regression, lasso, and ridge regression. Our data set represented both HPC jobs that failed and those that succeeded, so our model was reliable, less likely to overfit, and generalizable. Our model achieved an R^2 of 95\% with 99\% accuracy. We identified five predictors for both CPU and memory properties.
Vision-Based Layout Detection from Scientific Literature using Recurrent Convolutional Neural Networks
Oct 18, 2020

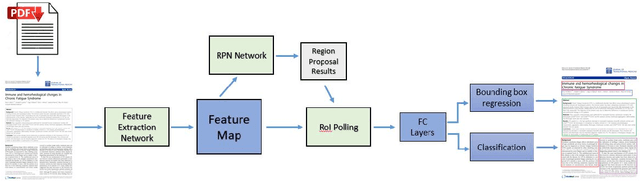

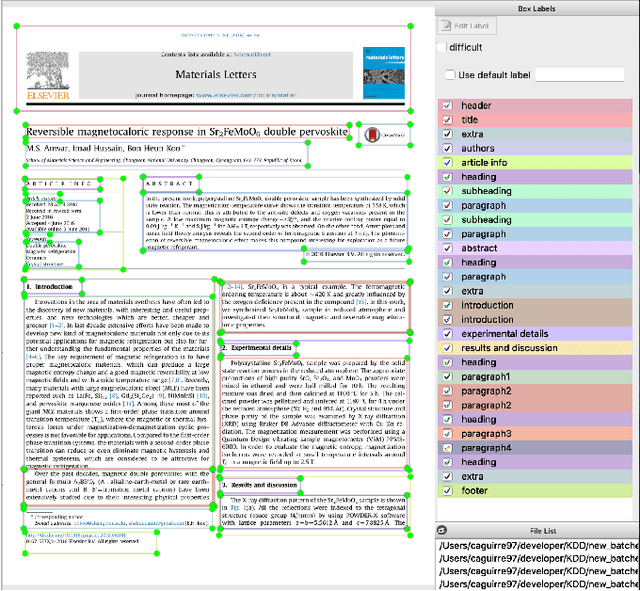
We present an approach for adapting convolutional neural networks for object recognition and classification to scientific literature layout detection (SLLD), a shared subtask of several information extraction problems. Scientific publications contain multiple types of information sought by researchers in various disciplines, organized into an abstract, bibliography, and sections documenting related work, experimental methods, and results; however, there is no effective way to extract this information due to their diverse layout. In this paper, we present a novel approach to developing an end-to-end learning framework to segment and classify major regions of a scientific document. We consider scientific document layout analysis as an object detection task over digital images, without any additional text features that need to be added into the network during the training process. Our technical objective is to implement transfer learning via fine-tuning of pre-trained networks and thereby demonstrate that this deep learning architecture is suitable for tasks that lack very large document corpora for training ab initio. As part of the experimental test bed for empirical evaluation of this approach, we created a merged multi-corpus data set for scientific publication layout detection tasks. Our results show good improvement with fine-tuning of a pre-trained base network using this merged data set, compared to the baseline convolutional neural network architecture.
* 8 pages
Pipelines for Procedural Information Extraction from Scientific Literature: Towards Recipes using Machine Learning and Data Science
Dec 16, 2019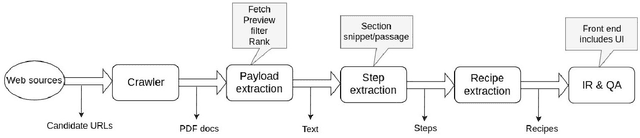
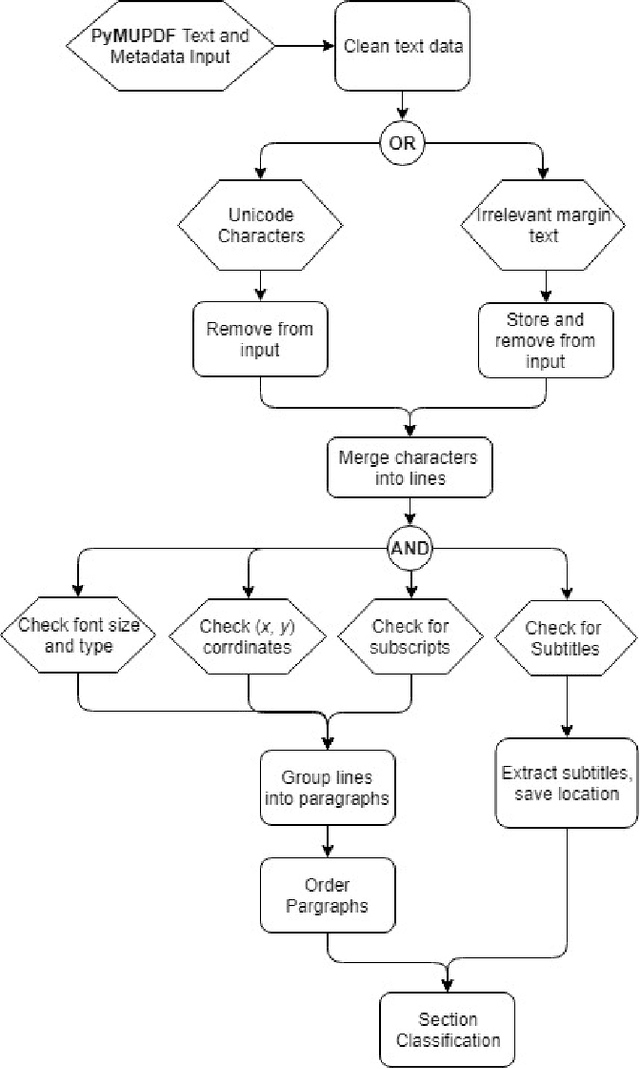

This paper describes a machine learning and data science pipeline for structured information extraction from documents, implemented as a suite of open-source tools and extensions to existing tools. It centers around a methodology for extracting procedural information in the form of recipes, stepwise procedures for creating an artifact (in this case synthesizing a nanomaterial), from published scientific literature. From our overall goal of producing recipes from free text, we derive the technical objectives of a system consisting of pipeline stages: document acquisition and filtering, payload extraction, recipe step extraction as a relationship extraction task, recipe assembly, and presentation through an information retrieval interface with question answering (QA) functionality. This system meets computational information and knowledge management (CIKM) requirements of metadata-driven payload extraction, named entity extraction, and relationship extraction from text. Functional contributions described in this paper include semi-supervised machine learning methods for PDF filtering and payload extraction tasks, followed by structured extraction and data transformation tasks beginning with section extraction, recipe steps as information tuples, and finally assembled recipes. Measurable objective criteria for extraction quality include precision and recall of recipe steps, ordering constraints, and QA accuracy, precision, and recall. Results, key novel contributions, and significant open problems derived from this work center around the attribution of these holistic quality measures to specific machine learning and inference stages of the pipeline, each with their performance measures. The desired recipes contain identified preconditions, material inputs, and operations, and constitute the overall output generated by our computational information and knowledge management (CIKM) system.
Machine Learning for Predictive Analytics of Compute Cluster Jobs
May 20, 2018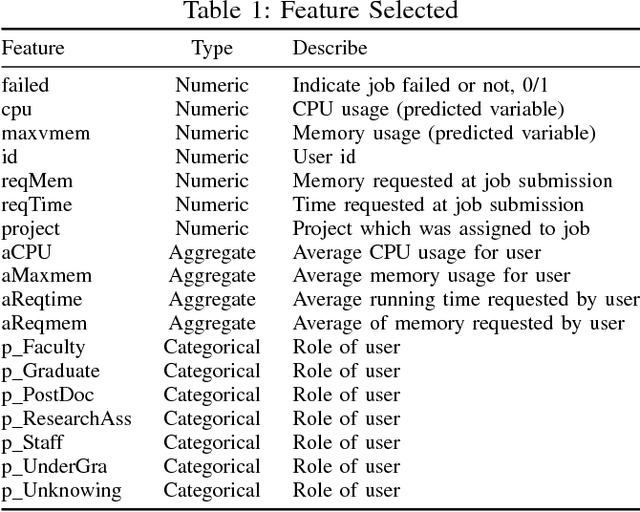
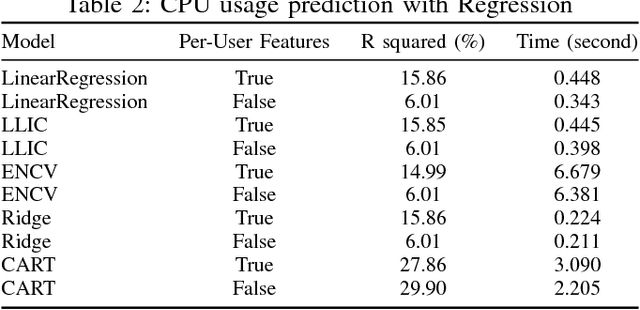
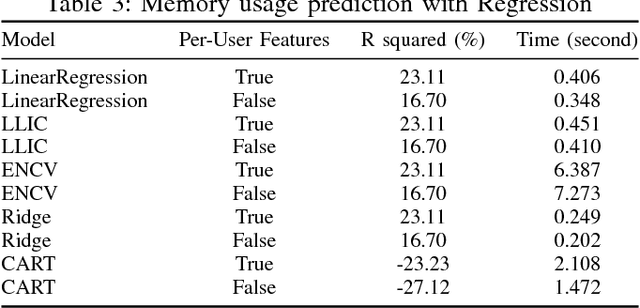
We address the problem of predicting whether sufficient memory and CPU resources have been requested for jobs at submission time. For this purpose, we examine the task of training a supervised machine learning system to predict the outcome - whether the job will fail specifically due to insufficient resources - as a classification task. Sufficiently high accuracy, precision, and recall at this task facilitates more anticipatory decision support applications in the domain of HPC resource allocation. Our preliminary results using a new test bed show that the probability of failed jobs is associated with information freely available at job submission time and may thus be usable by a learning system for user modeling that gives personalized feedback to users.