 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Learning to Predict Outcomes of Compute Cluster Jobs with Application to Decision Support
Dec 14, 2020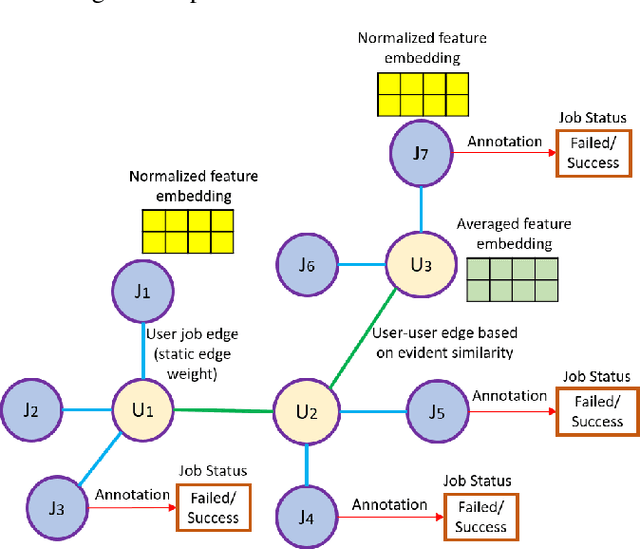

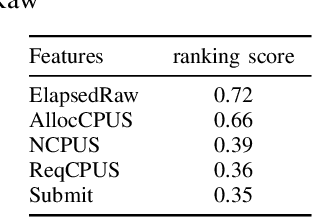
We present a machine learning framework and a new test bed for data mining from the Slurm Workload Manager for high-performance computing (HPC) clusters. The focus was to find a method for selecting features to support decisions: helping users decide whether to resubmit failed jobs with boosted CPU and memory allocations or migrate them to a computing cloud. This task was cast as both supervised classification and regression learning, specifically, sequential problem solving suitable for reinforcement learning. Selecting relevant features can improve training accuracy, reduce training time, and produce a more comprehensible model, with an intelligent system that can explain predictions and inferences. We present a supervised learning model trained on a Simple Linux Utility for Resource Management (Slurm) data set of HPC jobs using three different techniques for selecting features: linear regression, lasso, and ridge regression. Our data set represented both HPC jobs that failed and those that succeeded, so our model was reliable, less likely to overfit, and generalizable. Our model achieved an R^2 of 95\% with 99\% accuracy. We identified five predictors for both CPU and memory properties.
Machine Learning for Predictive Analytics of Compute Cluster Jobs
May 20, 2018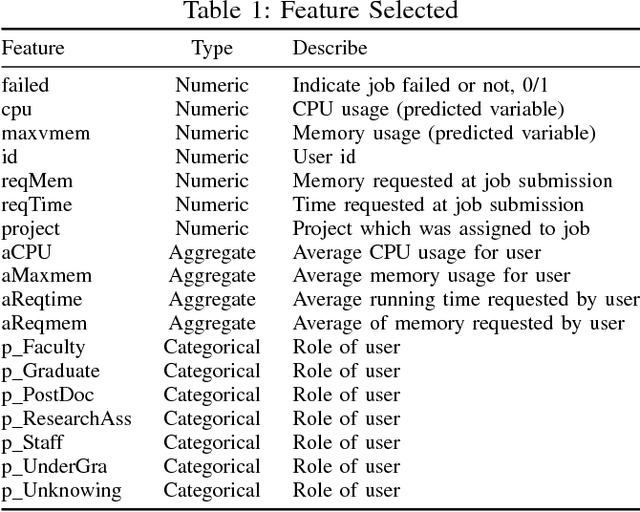
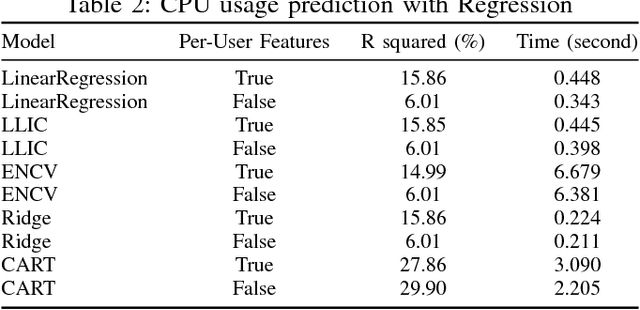
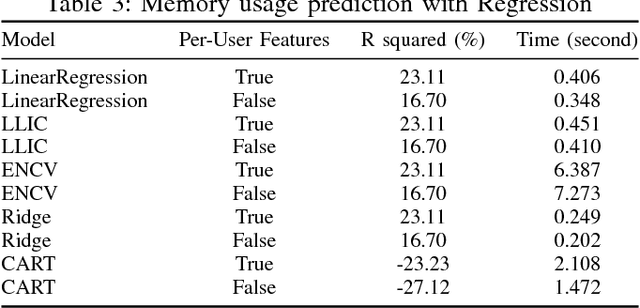
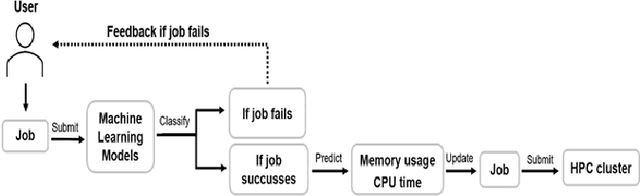
We address the problem of predicting whether sufficient memory and CPU resources have been requested for jobs at submission time. For this purpose, we examine the task of training a supervised machine learning system to predict the outcome - whether the job will fail specifically due to insufficient resources - as a classification task. Sufficiently high accuracy, precision, and recall at this task facilitates more anticipatory decision support applications in the domain of HPC resource allocation. Our preliminary results using a new test bed show that the probability of failed jobs is associated with information freely available at job submission time and may thus be usable by a learning system for user modeling that gives personalized feedback to users.