 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstromer 2
Feb 04, 2025



Foundational models have emerged as a powerful paradigm in deep learning field, leveraging their capacity to learn robust representations from large-scale datasets and effectively to diverse downstream applications such as classification. In this paper, we present Astromer 2 a foundational model specifically designed for extracting light curve embeddings. We introduce Astromer 2 as an enhanced iteration of our self-supervised model for light curve analysis. This paper highlights the advantages of its pre-trained embeddings, compares its performance with that of its predecessor, Astromer 1, and provides a detailed empirical analysis of its capabilities, offering deeper insights into the model's representations. Astromer 2 is pretrained on 1.5 million single-band light curves from the MACHO survey using a self-supervised learning task that predicts randomly masked observations within sequences. Fine-tuning on a smaller labeled dataset allows us to assess its performance in classification tasks. The quality of the embeddings is measured by the F1 score of an MLP classifier trained on Astromer-generated embeddings. Our results demonstrate that Astromer 2 significantly outperforms Astromer 1 across all evaluated scenarios, including limited datasets of 20, 100, and 500 samples per class. The use of weighted per-sample embeddings, which integrate intermediate representations from Astromer's attention blocks, is particularly impactful. Notably, Astromer 2 achieves a 15% improvement in F1 score on the ATLAS dataset compared to prior models, showcasing robust generalization to new datasets. This enhanced performance, especially with minimal labeled data, underscores the potential of Astromer 2 for more efficient and scalable light curve analysis.
Scalable End-to-end Recurrent Neural Network for Variable star classification
Feb 03, 2020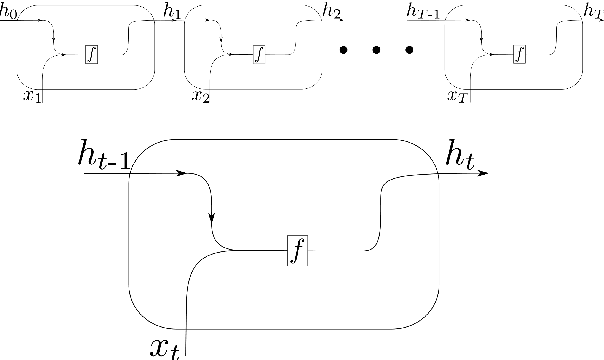

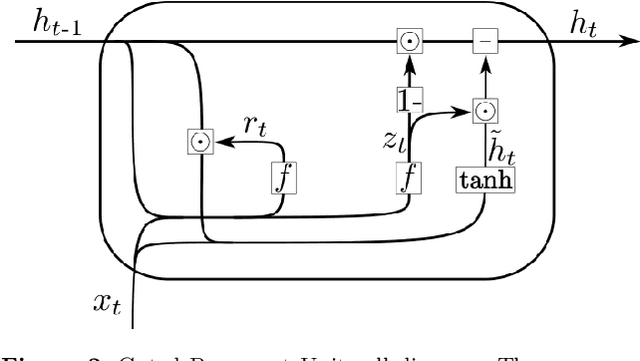
During the last decade, considerable effort has been made to perform automatic classification of variable stars using machine learning techniques. Traditionally, light curves are represented as a vector of descriptors or features used as input for many algorithms. Some features are computationally expensive, cannot be updated quickly and hence for large datasets such as the LSST cannot be applied. Previous work has been done to develop alternative unsupervised feature extraction algorithms for light curves, but the cost of doing so still remains high. In this work, we propose an end-to-end algorithm that automatically learns the representation of light curves that allows an accurate automatic classification. We study a series of deep learning architectures based on Recurrent Neural Networks and test them in automated classification scenarios. Our method uses minimal data preprocessing, can be updated with a low computational cost for new observations and light curves, and can scale up to massive datasets. We transform each light curve into an input matrix representation whose elements are the differences in time and magnitude, and the outputs are classification probabilities. We test our method in three surveys: OGLE-III, Gaia and WISE. We obtain accuracies of about $95\%$ in the main classes and $75\%$ in the majority of subclasses. We compare our results with the Random Forest classifier and obtain competitive accuracies while being faster and scalable. The analysis shows that the computational complexity of our approach grows up linearly with the light curve size, while the traditional approach cost grows as $N\log{(N)}$.
Deep multi-survey classification of variable stars
Oct 21, 2018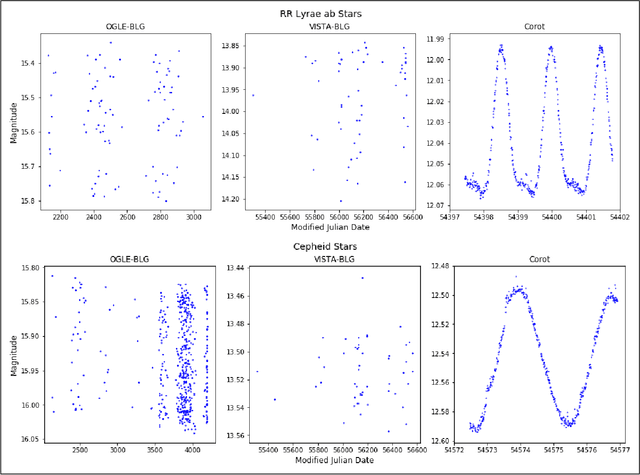
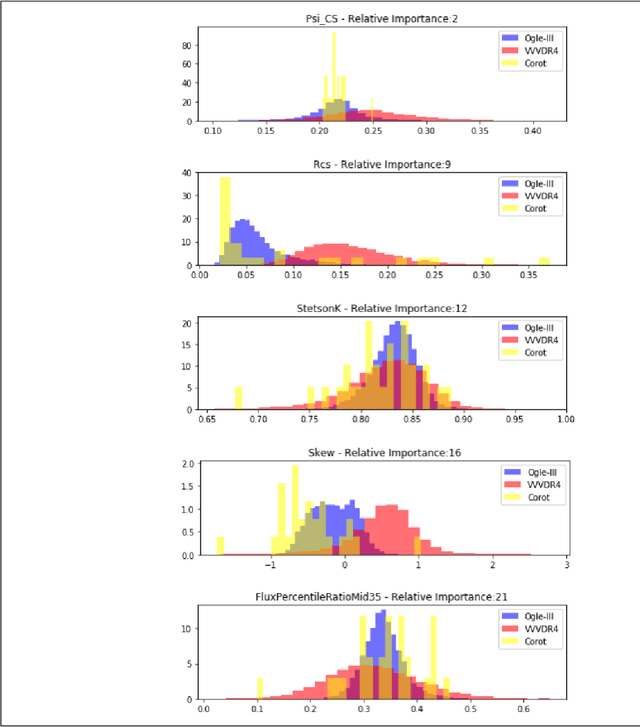
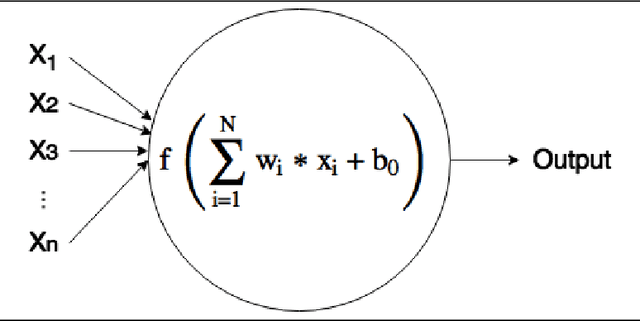
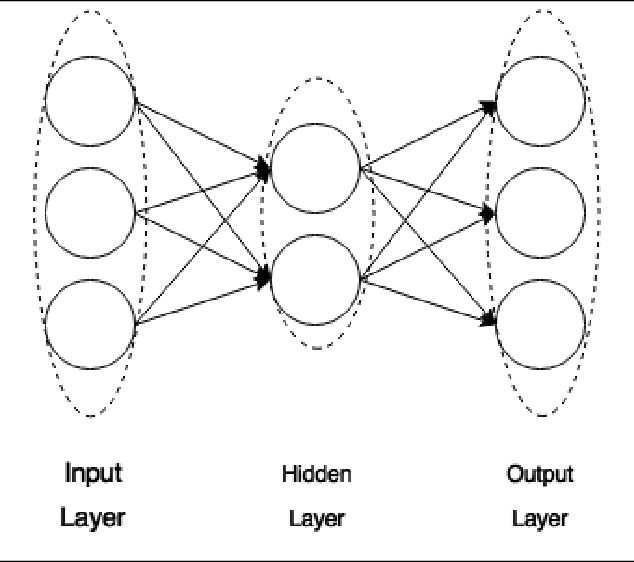
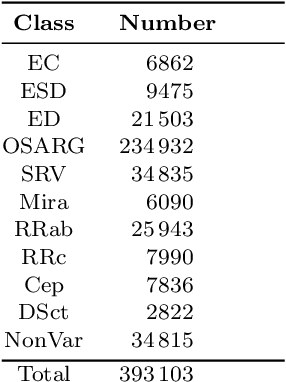
During the last decade, a considerable amount of effort has been made to classify variable stars using different machine learning techniques. Typically, light curves are represented as vectors of statistical descriptors or features that are used to train various algorithms. These features demand big computational powers that can last from hours to days, making impossible to create scalable and efficient ways of automatically classifying variable stars. Also, light curves from different surveys cannot be integrated and analyzed together when using features, because of observational differences. For example, having variations in cadence and filters, feature distributions become biased and require expensive data-calibration models. The vast amount of data that will be generated soon make necessary to develop scalable machine learning architectures without expensive integration techniques. Convolutional Neural Networks have shown impressing results in raw image classification and representation within the machine learning literature. In this work, we present a novel Deep Learning model for light curve classification, mainly based on convolutional units. Our architecture receives as input the differences between time and magnitude of light curves. It captures the essential classification patterns regardless of cadence and filter. In addition, we introduce a novel data augmentation schema for unevenly sampled time series. We test our method using three different surveys: OGLE-III; Corot; and VVV, which differ in filters, cadence, and area of the sky. We show that besides the benefit of scalability, our model obtains state of the art levels accuracy in light curve classification benchmarks.