 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender and Racial Fairness in Depression Research using Social Media
Paper and Code
Mar 18, 2021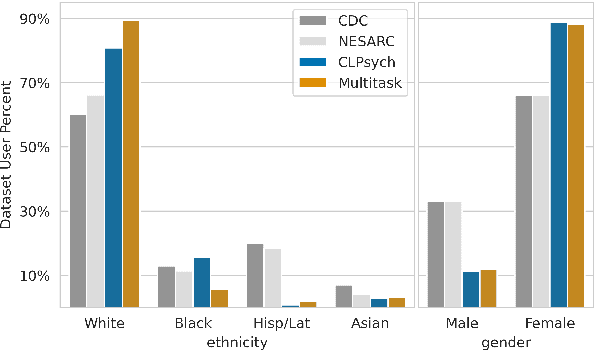
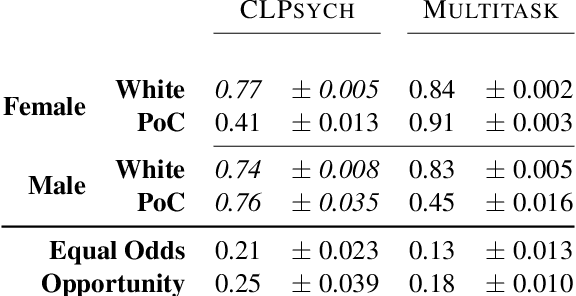
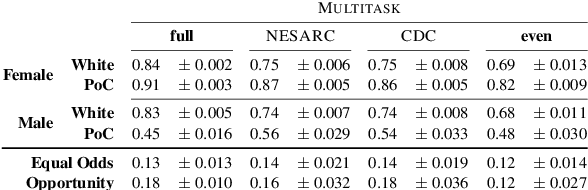
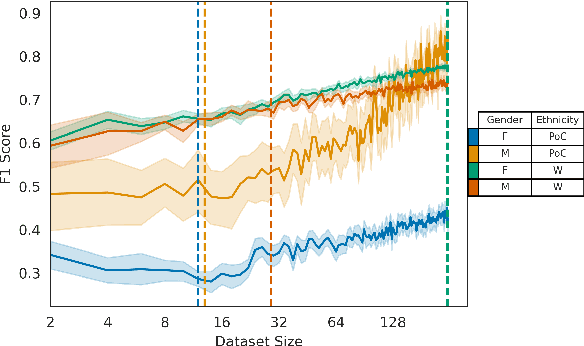
Multiple studies have demonstrated that behavior on internet-based social media platforms can be indicative of an individual's mental health status. The widespread availability of such data has spurred interest in mental health research from a computational lens. While previous research has raised concerns about possible biases in models produced from this data, no study has quantified how these biases actually manifest themselves with respect to different demographic groups, such as gender and racial/ethnic groups. Here, we analyze the fairness of depression classifiers trained on Twitter data with respect to gender and racial demographic groups. We find that model performance systematically differs for underrepresented groups and that these discrepancies cannot be fully explained by trivial data representation issues. Our study concludes with recommendations on how to avoid these biases in future research.