 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemFollowIR: a Multilingual Benchmark for Instruction Following in Retrieval
Jan 31, 2025



Retrieval systems generally focus on web-style queries that are short and underspecified. However, advances in language models have facilitated the nascent rise of retrieval models that can understand more complex queries with diverse intents. However, these efforts have focused exclusively on English; therefore, we do not yet understand how they work across languages. We introduce mFollowIR, a multilingual benchmark for measuring instruction-following ability in retrieval models. mFollowIR builds upon the TREC NeuCLIR narratives (or instructions) that span three diverse languages (Russian, Chinese, Persian) giving both query and instruction to the retrieval models. We make small changes to the narratives and isolate how well retrieval models can follow these nuanced changes. We present results for both multilingual (XX-XX) and cross-lingual (En-XX) performance. We see strong cross-lingual performance with English-based retrievers that trained using instructions, but find a notable drop in performance in the multilingual setting, indicating that more work is needed in developing data for instruction-based multilingual retrievers.
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Jul 14, 2024Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
MultiMUC: Multilingual Template Filling on MUC-4
Jan 29, 2024
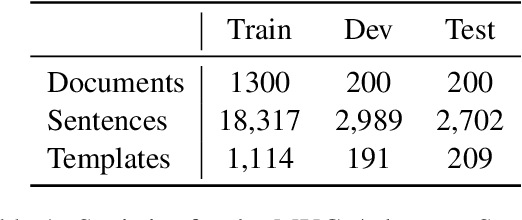

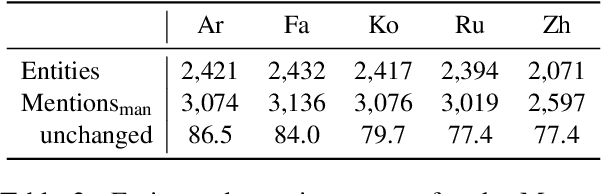
We introduce MultiMUC, the first multilingual parallel corpus for template filling, comprising translations of the classic MUC-4 template filling benchmark into five languages: Arabic, Chinese, Farsi, Korean, and Russian. We obtain automatic translations from a strong multilingual machine translation system and manually project the original English annotations into each target language. For all languages, we also provide human translations for sentences in the dev and test splits that contain annotated template arguments. Finally, we present baselines on MultiMUC both with state-of-the-art template filling models and with ChatGPT.
MegaWika: Millions of reports and their sources across 50 diverse languages
Jul 13, 2023To foster the development of new models for collaborative AI-assisted report generation, we introduce MegaWika, consisting of 13 million Wikipedia articles in 50 diverse languages, along with their 71 million referenced source materials. We process this dataset for a myriad of applications, going beyond the initial Wikipedia citation extraction and web scraping of content, including translating non-English articles for cross-lingual applications and providing FrameNet parses for automated semantic analysis. MegaWika is the largest resource for sentence-level report generation and the only report generation dataset that is multilingual. We manually analyze the quality of this resource through a semantically stratified sample. Finally, we provide baseline results and trained models for crucial steps in automated report generation: cross-lingual question answering and citation retrieval.
Multilingual Coreference Resolution in Multiparty Dialogue
Aug 02, 2022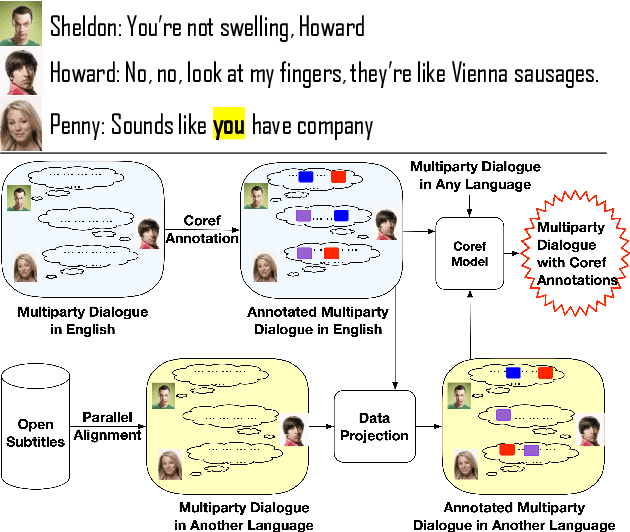
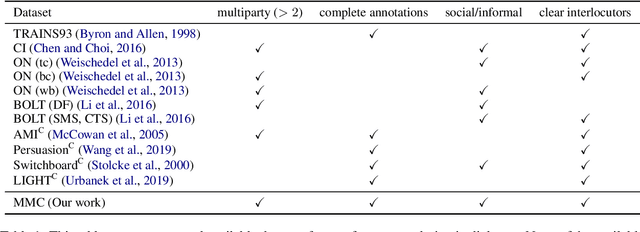
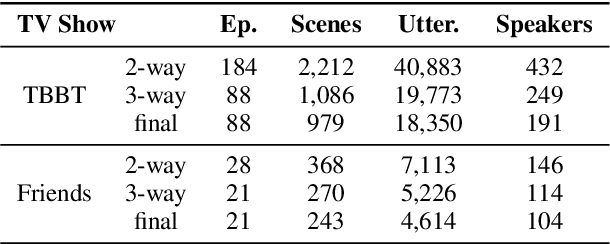
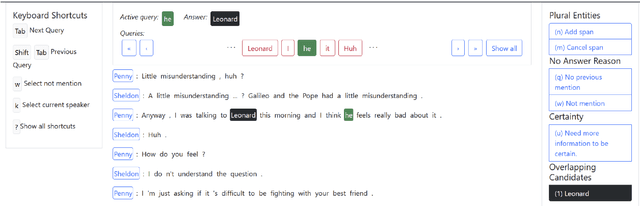
Existing multiparty dialogue datasets for coreference resolution are nascent, and many challenges are still unaddressed. We create a large-scale dataset, Multilingual Multiparty Coref (MMC), for this task based on TV transcripts. Due to the availability of gold-quality subtitles in multiple languages, we propose reusing the annotations to create silver coreference data in other languages (Chinese and Farsi) via annotation projection. On the gold (English) data, off-the-shelf models perform relatively poorly on MMC, suggesting that MMC has broader coverage of multiparty coreference than prior datasets. On the silver data, we find success both using it for data augmentation and training from scratch, which effectively simulates the zero-shot cross-lingual setting.
Everything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021

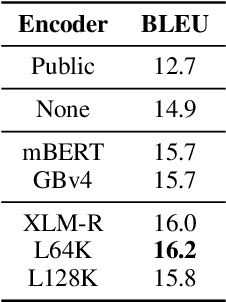

Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
Gradual Fine-Tuning for Low-Resource Domain Adaptation
Mar 03, 2021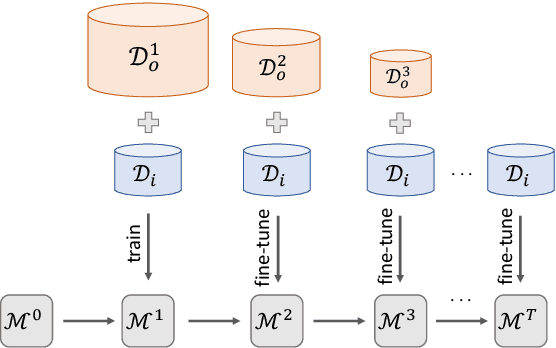
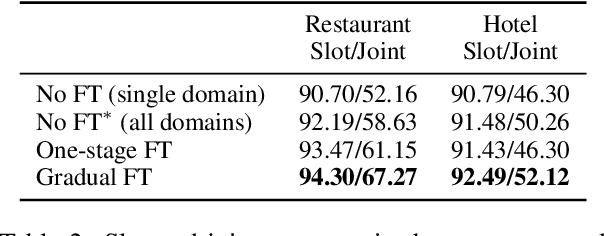
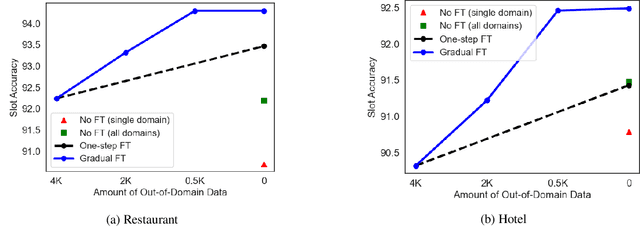
Fine-tuning is known to improve NLP models by adapting an initial model trained on more plentiful but less domain-salient examples to data in a target domain. Such domain adaptation is typically done using one stage of fine-tuning. We demonstrate that gradually fine-tuning in a multi-stage process can yield substantial further gains and can be applied without modifying the model or learning objective.
CopyNext: Explicit Span Copying and Alignment in Sequence to Sequence Models
Oct 28, 2020
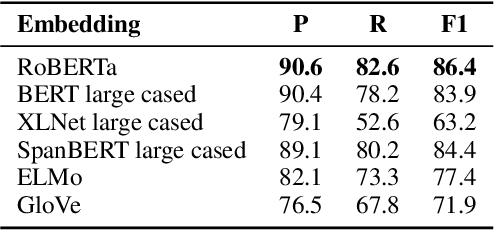
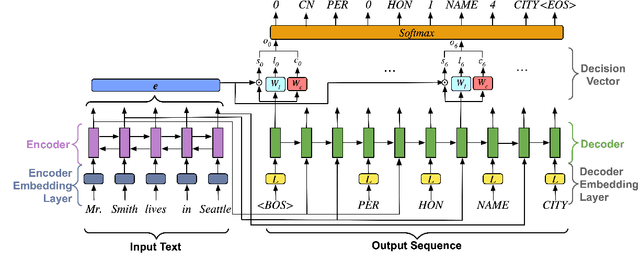
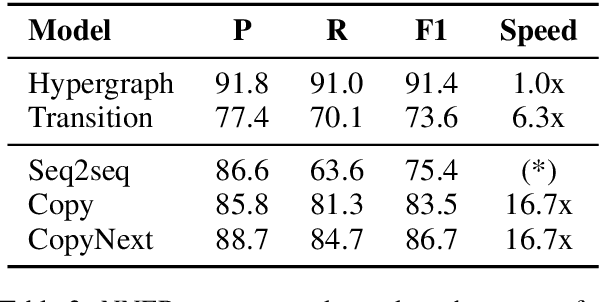
Copy mechanisms are employed in sequence to sequence models (seq2seq) to generate reproductions of words from the input to the output. These frameworks, operating at the lexical type level, fail to provide an explicit alignment that records where each token was copied from. Further, they require contiguous token sequences from the input (spans) to be copied individually. We present a model with an explicit token-level copy operation and extend it to copying entire spans. Our model provides hard alignments between spans in the input and output, allowing for nontraditional applications of seq2seq, like information extraction. We demonstrate the approach on Nested Named Entity Recognition, achieving near state-of-the-art accuracy with an order of magnitude increase in decoding speed.