 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfant hip screening using multi-class ultrasound scan segmentation
Nov 08, 2022



Developmental dysplasia of the hip (DDH) is a condition in infants where the femoral head is incorrectly located in the hip joint. We propose a deep learning algorithm for segmenting key structures within ultrasound images, employing this to calculate Femoral Head Coverage (FHC) and provide a screening diagnosis for DDH. To our knowledge, this is the first study to automate FHC calculation for DDH screening. Our algorithm outperforms the international state of the art, agreeing with expert clinicians on 89.8% of our test images.
CopyNext: Explicit Span Copying and Alignment in Sequence to Sequence Models
Oct 28, 2020
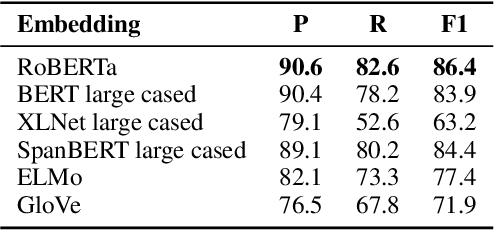
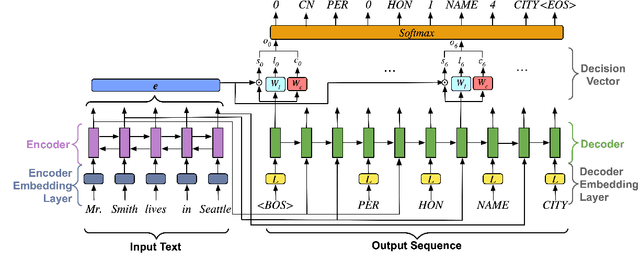
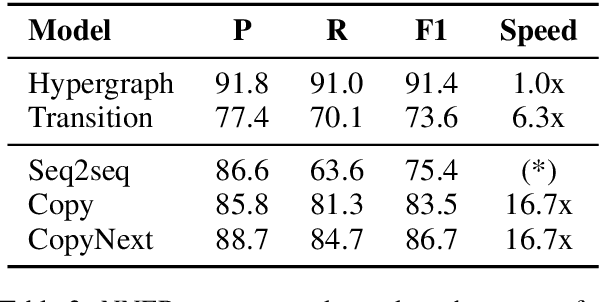
Copy mechanisms are employed in sequence to sequence models (seq2seq) to generate reproductions of words from the input to the output. These frameworks, operating at the lexical type level, fail to provide an explicit alignment that records where each token was copied from. Further, they require contiguous token sequences from the input (spans) to be copied individually. We present a model with an explicit token-level copy operation and extend it to copying entire spans. Our model provides hard alignments between spans in the input and output, allowing for nontraditional applications of seq2seq, like information extraction. We demonstrate the approach on Nested Named Entity Recognition, achieving near state-of-the-art accuracy with an order of magnitude increase in decoding speed.
A reaction network scheme which implements inference and learning for Hidden Markov Models
Jun 22, 2019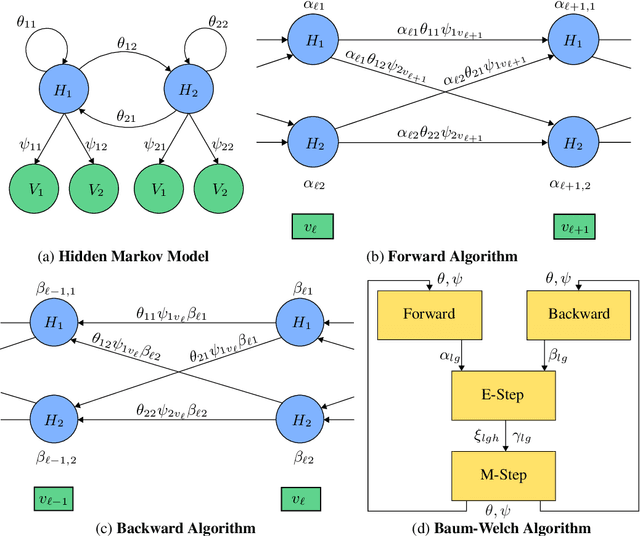


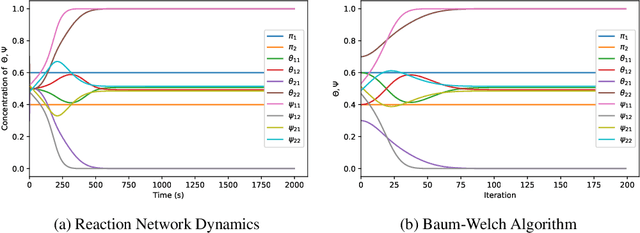
With a view towards molecular communication systems and molecular multi-agent systems, we propose the Chemical Baum-Welch Algorithm, a novel reaction network scheme that learns parameters for Hidden Markov Models (HMMs). Each reaction in our scheme changes only one molecule of one species to one molecule of another. The reverse change is also accessible but via a different set of enzymes, in a design reminiscent of futile cycles in biochemical pathways. We show that every fixed point of the Baum-Welch algorithm for HMMs is a fixed point of our reaction network scheme, and every positive fixed point of our scheme is a fixed point of the Baum-Welch algorithm. We prove that the "Expectation" step and the "Maximization" step of our reaction network separately converge exponentially fast. We simulate mass-action kinetics for our network on an example sequence, and show that it learns the same parameters for the HMM as the Baum-Welch algorithm.