 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024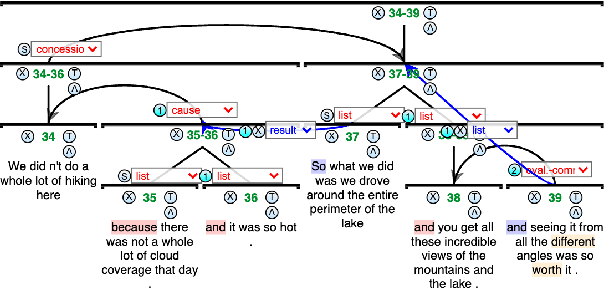
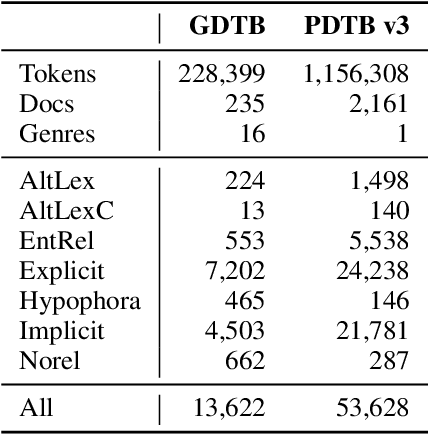
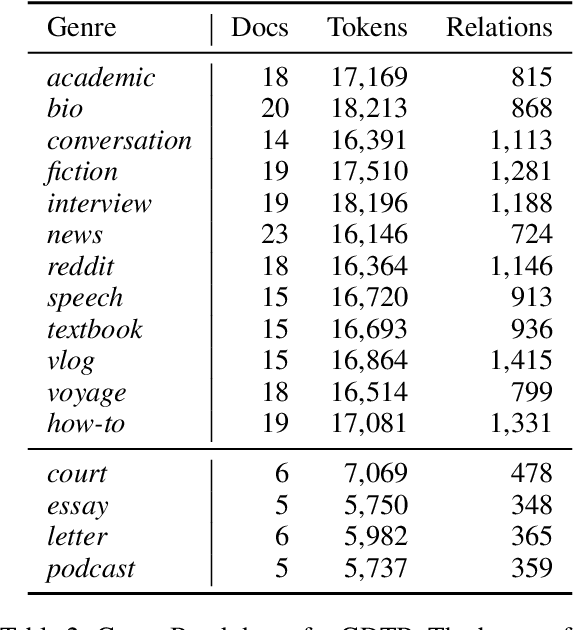
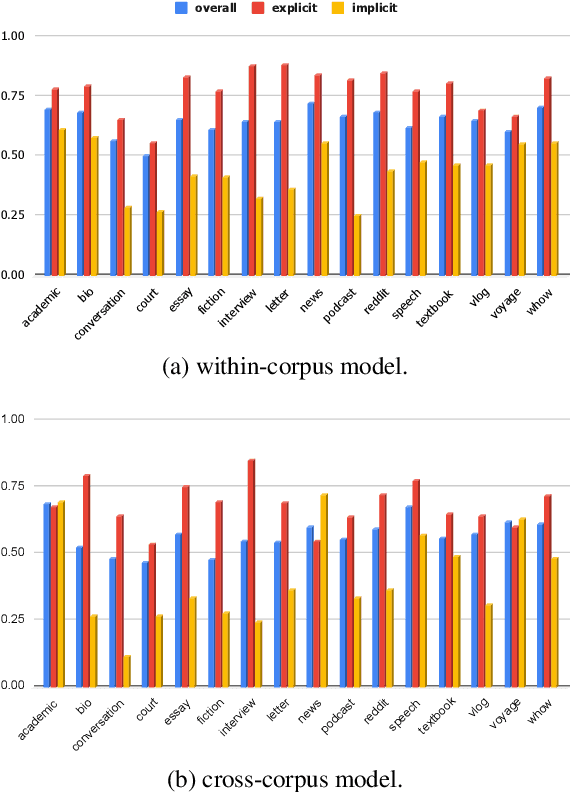
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
Data Checklist: On Unit-Testing Datasets with Usable Information
Aug 06, 2024



Model checklists (Ribeiro et al., 2020) have emerged as a useful tool for understanding the behavior of LLMs, analogous to unit-testing in software engineering. However, despite datasets being a key determinant of model behavior, evaluating datasets, e.g., for the existence of annotation artifacts, is largely done ad hoc, once a problem in model behavior has already been found downstream. In this work, we take a more principled approach to unit-testing datasets by proposing a taxonomy based on the V-information literature. We call a collection of such unit tests a data checklist. Using a checklist, not only are we able to recover known artifacts in well-known datasets such as SNLI, but we also discover previously unknown artifacts in preference datasets for LLM alignment. Data checklists further enable a new kind of data filtering, which we use to improve the efficacy and data efficiency of preference alignment.
MultiMUC: Multilingual Template Filling on MUC-4
Jan 29, 2024
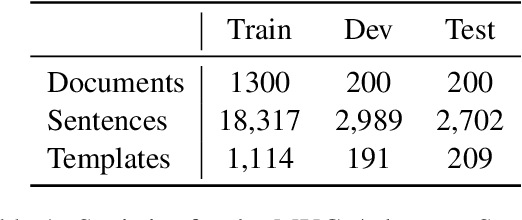

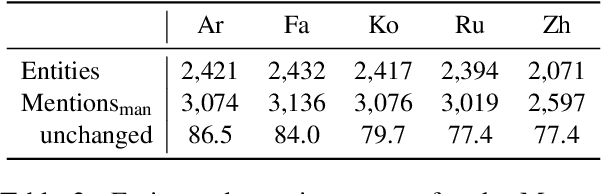
We introduce MultiMUC, the first multilingual parallel corpus for template filling, comprising translations of the classic MUC-4 template filling benchmark into five languages: Arabic, Chinese, Farsi, Korean, and Russian. We obtain automatic translations from a strong multilingual machine translation system and manually project the original English annotations into each target language. For all languages, we also provide human translations for sentences in the dev and test splits that contain annotated template arguments. Finally, we present baselines on MultiMUC both with state-of-the-art template filling models and with ChatGPT.
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation
Jun 03, 2023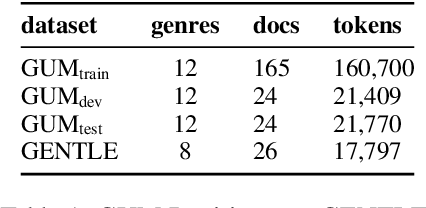
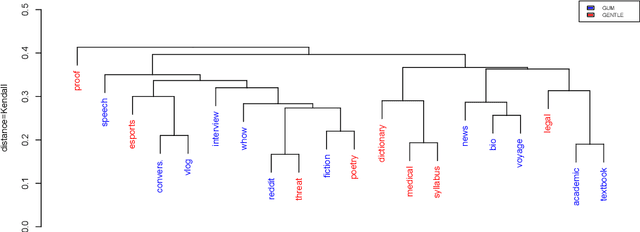
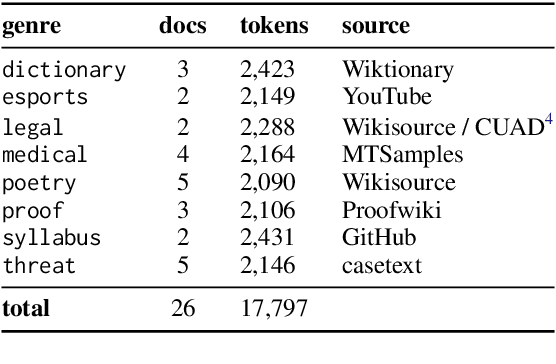
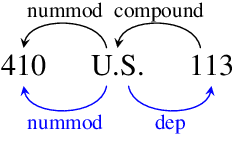
We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE's utility as an evaluation dataset for NLP systems.
Sentence-level Feedback Generation for English Language Learners: Does Data Augmentation Help?
Dec 18, 2022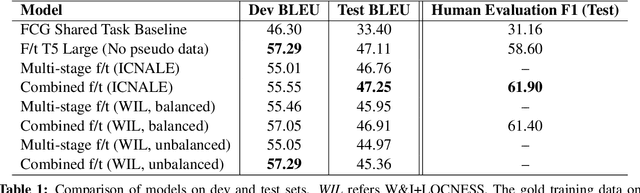

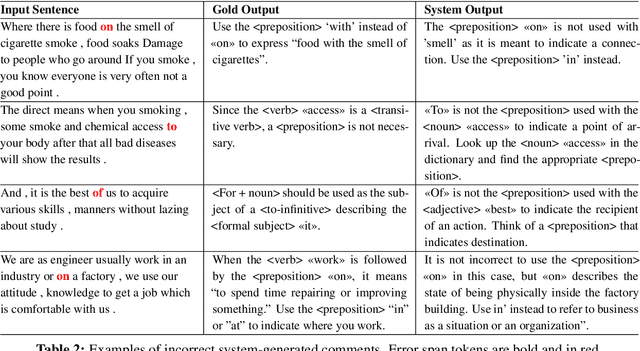

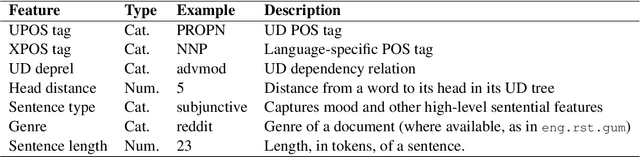
In this paper, we present strong baselines for the task of Feedback Comment Generation for Writing Learning. Given a sentence and an error span, the task is to generate a feedback comment explaining the error. Sentences and feedback comments are both in English. We experiment with LLMs and also create multiple pseudo datasets for the task, investigating how it affects the performance of our system. We present our results for the task along with extensive analysis of the generated comments with the aim of aiding future studies in feedback comment generation for English language learners.
ELQA: A Corpus of Questions and Answers about the English Language
May 01, 2022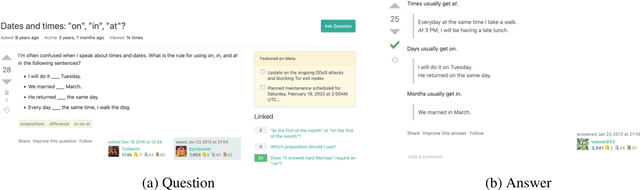
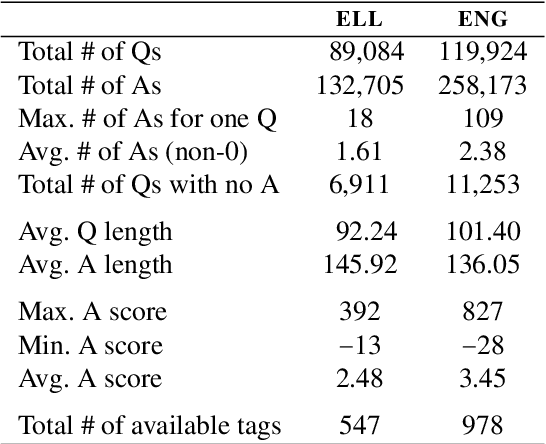
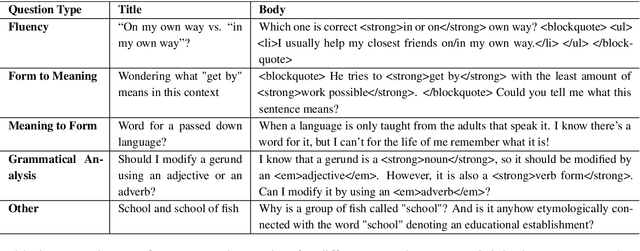
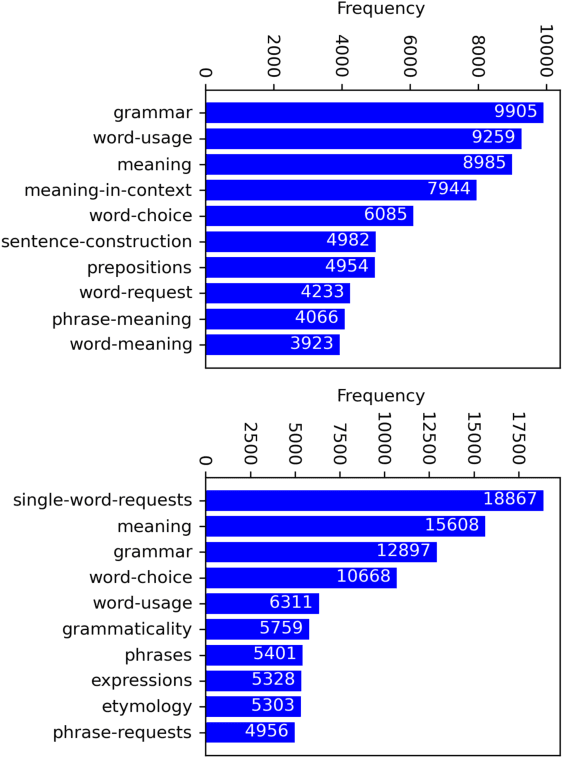
We introduce a community-sourced dataset for English Language Question Answering (ELQA), which consists of more than 180k questions and answers on numerous topics about English language such as grammar, meaning, fluency, and etymology. The ELQA corpus will enable new NLP applications for language learners. We introduce three tasks based on the ELQA corpus: 1) answer quality classification, 2) semantic search for finding similar questions, and 3) answer generation. We present baselines for each task along with analysis, showing the strengths and weaknesses of current transformer-based models. The ELQA corpus and scripts are publicly available for future studies.
DisCoDisCo at the DISRPT2021 Shared Task: A System for Discourse Segmentation, Classification, and Connective Detection
Sep 20, 2021
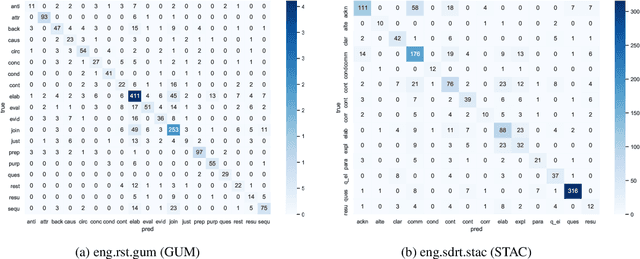

This paper describes our submission to the DISRPT2021 Shared Task on Discourse Unit Segmentation, Connective Detection, and Relation Classification. Our system, called DisCoDisCo, is a Transformer-based neural classifier which enhances contextualized word embeddings (CWEs) with hand-crafted features, relying on tokenwise sequence tagging for discourse segmentation and connective detection, and a feature-rich, encoder-less sentence pair classifier for relation classification. Our results for the first two tasks outperform SOTA scores from the previous 2019 shared task, and results on relation classification suggest strong performance on the new 2021 benchmark. Ablation tests show that including features beyond CWEs are helpful for both tasks, and a partial evaluation of multiple pre-trained Transformer-based language models indicates that models pre-trained on the Next Sentence Prediction (NSP) task are optimal for relation classification.
Team DoNotDistribute at SemEval-2020 Task 11: Features, Finetuning, and Data Augmentation in Neural Models for Propaganda Detection in News Articles
Aug 21, 2020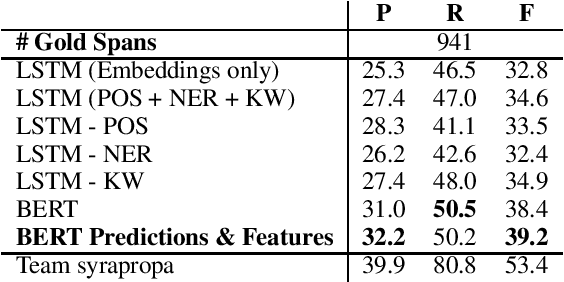
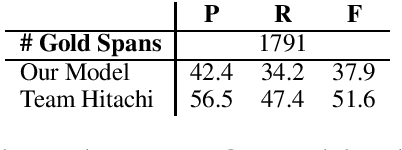
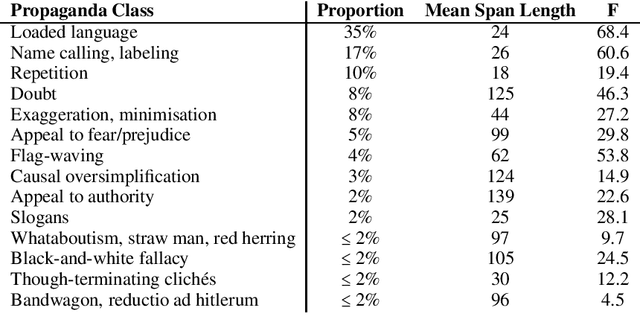

This paper presents our systems for SemEval 2020 Shared Task 11: Detection of Propaganda Techniques in News Articles. We participate in both the span identification and technique classification subtasks and report on experiments using different BERT-based models along with handcrafted features. Our models perform well above the baselines for both tasks, and we contribute ablation studies and discussion of our results to dissect the effectiveness of different features and techniques with the goal of aiding future studies in propaganda detection.
AMALGUM -- A Free, Balanced, Multilayer English Web Corpus
Jun 18, 2020

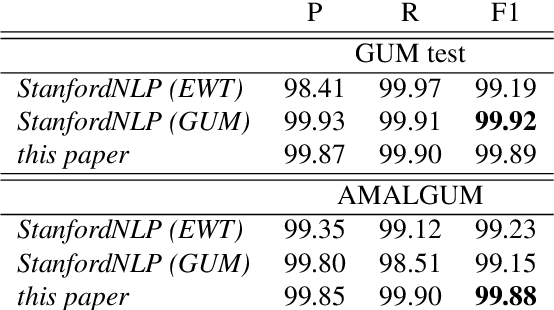
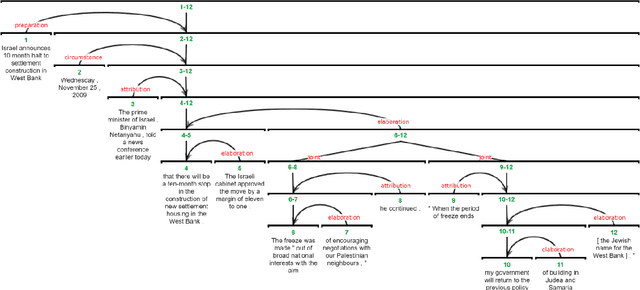
We present a freely available, genre-balanced English web corpus totaling 4M tokens and featuring a large number of high-quality automatic annotation layers, including dependency trees, non-named entity annotations, coreference resolution, and discourse trees in Rhetorical Structure Theory. By tapping open online data sources the corpus is meant to offer a more sizable alternative to smaller manually created annotated data sets, while avoiding pitfalls such as imbalanced or unknown composition, licensing problems, and low-quality natural language processing. We harness knowledge from multiple annotation layers in order to achieve a "better than NLP" benchmark and evaluate the accuracy of the resulting resource.
* Accepted at LREC 2020. See https://www.aclweb.org/anthology/2020.lrec-1.648/ (note: ACL Anthology's title is currently out of date)
A Cross-Genre Ensemble Approach to Robust Reddit Part of Speech Tagging
Apr 29, 2020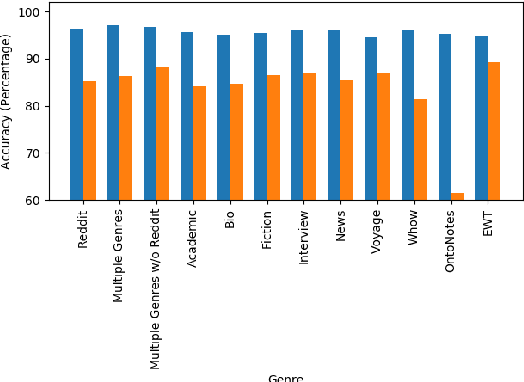

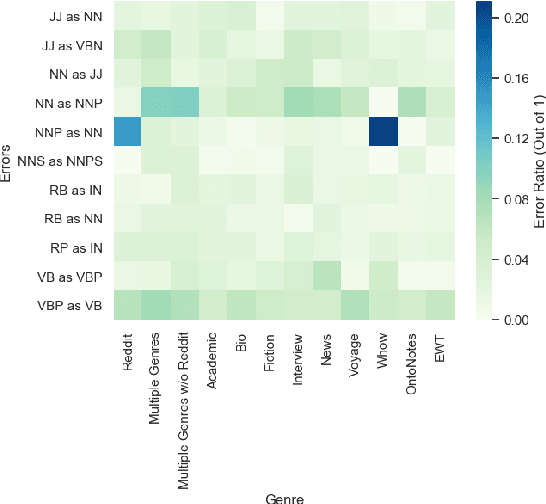
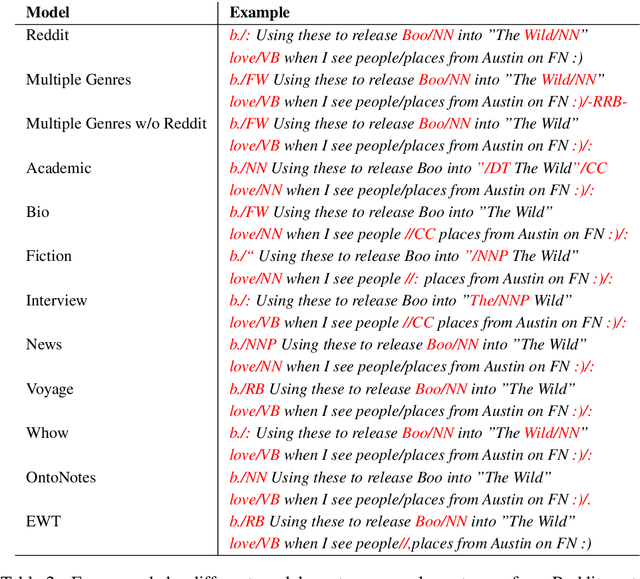
Part of speech tagging is a fundamental NLP task often regarded as solved for high-resource languages such as English. Current state-of-the-art models have achieved high accuracy, especially on the news domain. However, when these models are applied to other corpora with different genres, and especially user-generated data from the Web, we see substantial drops in performance. In this work, we study how a state-of-the-art tagging model trained on different genres performs on Web content from unfiltered Reddit forum discussions. More specifically, we use data from multiple sources: OntoNotes, a large benchmark corpus with 'well-edited' text, the English Web Treebank with 5 Web genres, and GUM, with 7 further genres other than Reddit. We report the results when training on different splits of the data, tested on Reddit. Our results show that even small amounts of in-domain data can outperform the contribution of data an order of magnitude larger coming from other Web domains. To make progress on out-of-domain tagging, we also evaluate an ensemble approach using multiple single-genre taggers as input features to a meta-classifier. We present state of the art performance on tagging Reddit data, as well as error analysis of the results of these models, and offer a typology of the most common error types among them, broken down by training corpus.