Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMALGUM -- A Free, Balanced, Multilayer English Web Corpus
Paper and Code


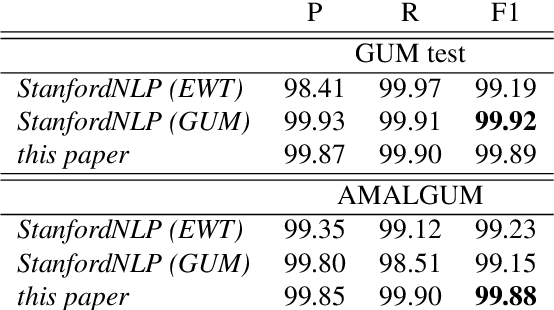
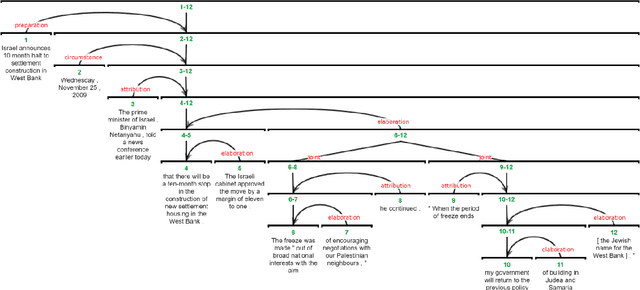
We present a freely available, genre-balanced English web corpus totaling 4M tokens and featuring a large number of high-quality automatic annotation layers, including dependency trees, non-named entity annotations, coreference resolution, and discourse trees in Rhetorical Structure Theory. By tapping open online data sources the corpus is meant to offer a more sizable alternative to smaller manually created annotated data sets, while avoiding pitfalls such as imbalanced or unknown composition, licensing problems, and low-quality natural language processing. We harness knowledge from multiple annotation layers in order to achieve a "better than NLP" benchmark and evaluate the accuracy of the resulting resource.
* In Proceedings of The 12th Language Resources and Evaluation
Conference (pp. 5267-5275), 2020 * Accepted at LREC 2020. See
https://www.aclweb.org/anthology/2020.lrec-1.648/ (note: ACL Anthology's
title is currently out of date)
View paper on