Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELQA: A Corpus of Questions and Answers about the English Language
Paper and Code
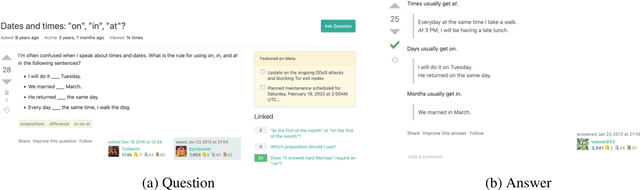
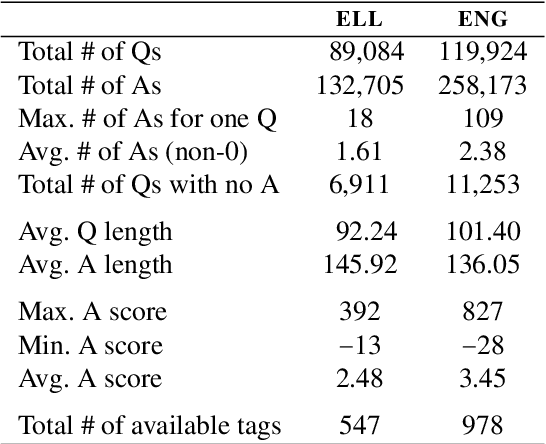
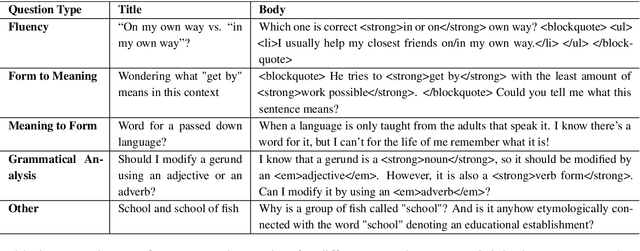
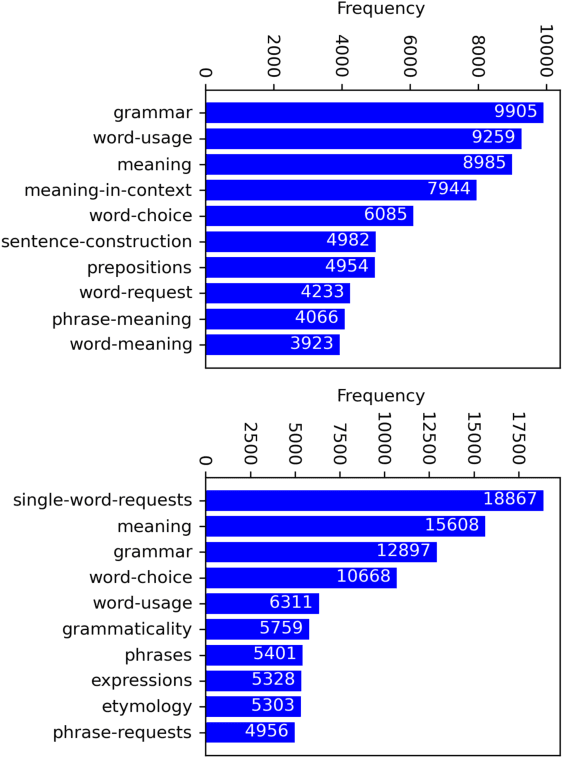
We introduce a community-sourced dataset for English Language Question Answering (ELQA), which consists of more than 180k questions and answers on numerous topics about English language such as grammar, meaning, fluency, and etymology. The ELQA corpus will enable new NLP applications for language learners. We introduce three tasks based on the ELQA corpus: 1) answer quality classification, 2) semantic search for finding similar questions, and 3) answer generation. We present baselines for each task along with analysis, showing the strengths and weaknesses of current transformer-based models. The ELQA corpus and scripts are publicly available for future studies.
View paper on