 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024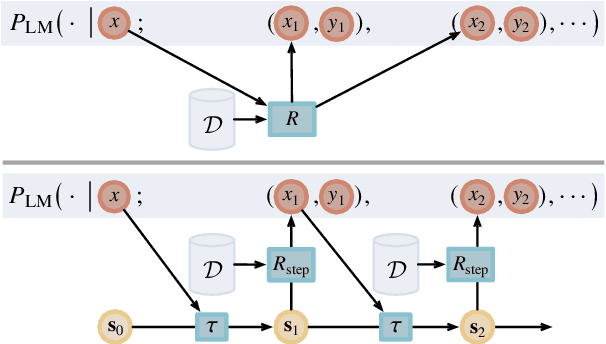
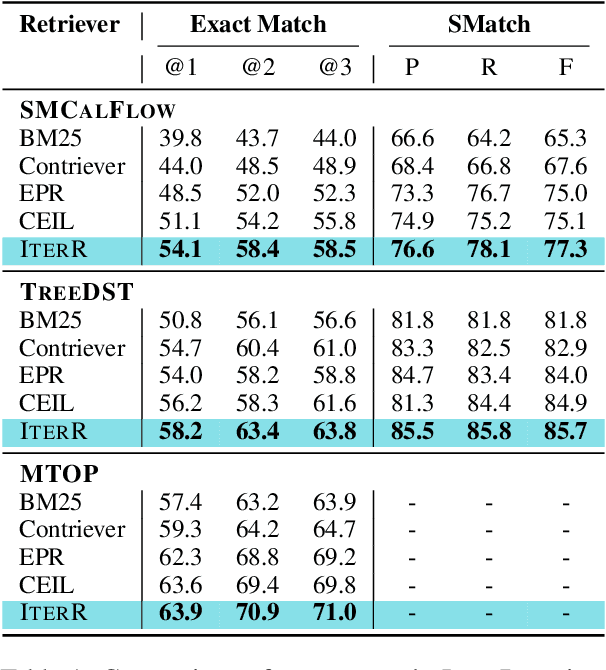
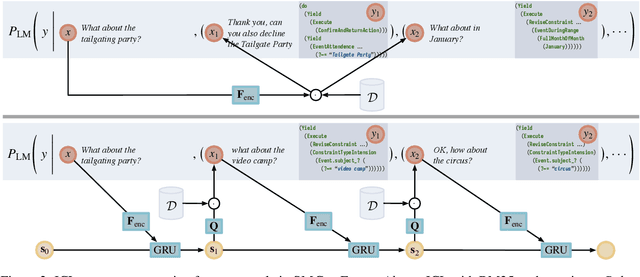
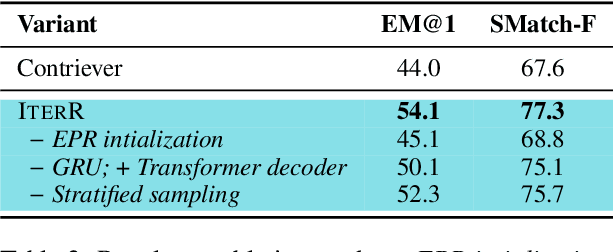
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
Streaming Sequence Transduction through Dynamic Compression
Feb 02, 2024We introduce STAR (Stream Transduction with Anchor Representations), a novel Transformer-based model designed for efficient sequence-to-sequence transduction over streams. STAR dynamically segments input streams to create compressed anchor representations, achieving nearly lossless compression (12x) in Automatic Speech Recognition (ASR) and outperforming existing methods. Moreover, STAR demonstrates superior segmentation and latency-quality trade-offs in simultaneous speech-to-text tasks, optimizing latency, memory footprint, and quality.
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation
Feb 02, 2024



Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, does not match the performance of state-of-the-art conventional encoder-decoder translation models or larger-scale LLMs such as GPT-4. In this study, we bridge this performance gap. We first assess the shortcomings of supervised fine-tuning for LLMs in the MT task, emphasizing the quality issues present in the reference data, despite being human-generated. Then, in contrast to SFT which mimics reference translations, we introduce Contrastive Preference Optimization (CPO), a novel approach that trains models to avoid generating adequate but not perfect translations. Applying CPO to ALMA models with only 22K parallel sentences and 12M parameters yields significant improvements. The resulting model, called ALMA-R, can match or exceed the performance of the WMT competition winners and GPT-4 on WMT'21, WMT'22 and WMT'23 test datasets.
MultiMUC: Multilingual Template Filling on MUC-4
Jan 29, 2024
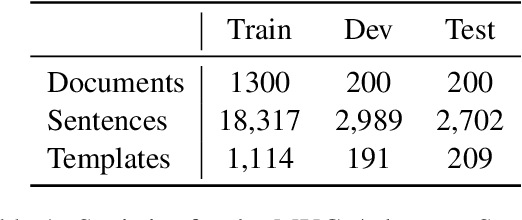

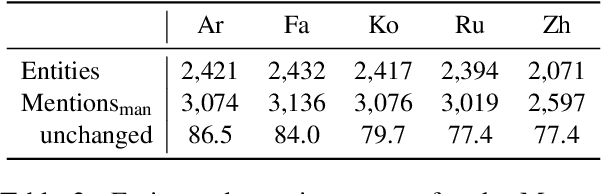
We introduce MultiMUC, the first multilingual parallel corpus for template filling, comprising translations of the classic MUC-4 template filling benchmark into five languages: Arabic, Chinese, Farsi, Korean, and Russian. We obtain automatic translations from a strong multilingual machine translation system and manually project the original English annotations into each target language. For all languages, we also provide human translations for sentences in the dev and test splits that contain annotated template arguments. Finally, we present baselines on MultiMUC both with state-of-the-art template filling models and with ChatGPT.
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts
Jan 23, 2024



As the influence of large language models (LLMs) spans across global communities, their safety challenges in multilingual settings become paramount for alignment research. This paper examines the variations in safety challenges faced by LLMs across different languages and discusses approaches to alleviating such concerns. By comparing how state-of-the-art LLMs respond to the same set of malicious prompts written in higher- vs. lower-resource languages, we observe that (1) LLMs tend to generate unsafe responses much more often when a malicious prompt is written in a lower-resource language, and (2) LLMs tend to generate more irrelevant responses to malicious prompts in lower-resource languages. To understand where the discrepancy can be attributed, we study the effect of instruction tuning with reinforcement learning from human feedback (RLHF) or supervised finetuning (SFT) on the HH-RLHF dataset. Surprisingly, while training with high-resource languages improves model alignment, training in lower-resource languages yields minimal improvement. This suggests that the bottleneck of cross-lingual alignment is rooted in the pretraining stage. Our findings highlight the challenges in cross-lingual LLM safety, and we hope they inform future research in this direction.
Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles
Nov 04, 2023



Large language models trained primarily in a monolingual setting have demonstrated their ability to generalize to machine translation using zero- and few-shot examples with in-context learning. However, even though zero-shot translations are relatively good, there remains a discernible gap comparing their performance with the few-shot setting. In this paper, we investigate the factors contributing to this gap and find that this gap can largely be closed (for about 70%) by matching the writing styles of the target corpus. Additionally, we explore potential approaches to enhance zero-shot baselines without the need for parallel demonstration examples, providing valuable insights into how these methods contribute to improving translation metrics.
FAITHSCORE: Evaluating Hallucinations in Large Vision-Language Models
Nov 02, 2023We introduce FAITHSCORE (Faithfulness to Atomic Image Facts Score), a reference-free and fine-grained evaluation metric that measures the faithfulness of the generated free-form answers from large vision-language models (LVLMs). The FAITHSCORE evaluation first identifies sub-sentences containing descriptive statements that need to be verified, then extracts a comprehensive list of atomic facts from these sub-sentences, and finally conducts consistency verification between fine-grained atomic facts and the input image. Meta-evaluation demonstrates that our metric highly correlates with human judgments of faithfulness. We collect two benchmark datasets (i.e. LLaVA-1k and MSCOCO-Cap) for evaluating LVLMs instruction-following hallucinations. We measure hallucinations in state-of-the-art LVLMs with FAITHSCORE on the datasets. Results reveal that current systems are prone to generate hallucinated content unfaithful to the image, which leaves room for future improvements. Further, we find that current LVLMs despite doing well on color and counting, still struggle with long answers, relations, and multiple objects.
A Unified View of Evaluation Metrics for Structured Prediction
Oct 20, 2023We present a conceptual framework that unifies a variety of evaluation metrics for different structured prediction tasks (e.g. event and relation extraction, syntactic and semantic parsing). Our framework requires representing the outputs of these tasks as objects of certain data types, and derives metrics through matching of common substructures, possibly followed by normalization. We demonstrate how commonly used metrics for a number of tasks can be succinctly expressed by this framework, and show that new metrics can be naturally derived in a bottom-up way based on an output structure. We release a library that enables this derivation to create new metrics. Finally, we consider how specific characteristics of tasks motivate metric design decisions, and suggest possible modifications to existing metrics in line with those motivations.
Differentiable Tree Operations Promote Compositional Generalization
Jun 01, 2023In the context of structure-to-structure transformation tasks, learning sequences of discrete symbolic operations poses significant challenges due to their non-differentiability. To facilitate the learning of these symbolic sequences, we introduce a differentiable tree interpreter that compiles high-level symbolic tree operations into subsymbolic matrix operations on tensors. We present a novel Differentiable Tree Machine (DTM) architecture that integrates our interpreter with an external memory and an agent that learns to sequentially select tree operations to execute the target transformation in an end-to-end manner. With respect to out-of-distribution compositional generalization on synthetic semantic parsing and language generation tasks, DTM achieves 100% while existing baselines such as Transformer, Tree Transformer, LSTM, and Tree2Tree LSTM achieve less than 30%. DTM remains highly interpretable in addition to its perfect performance.
Condensing Multilingual Knowledge with Lightweight Language-Specific Modules
May 23, 2023Incorporating language-specific (LS) modules is a proven method to boost performance in multilingual machine translation. This approach bears similarity to Mixture-of-Experts (MoE) because it does not inflate FLOPs. However, the scalability of this approach to hundreds of languages (experts) tends to be unmanageable due to the prohibitive number of parameters introduced by full-rank matrices in fully-connected layers. In this work, we introduce the Language-Specific Matrix Synthesis (LMS) method. This approach constructs LS modules by generating low-rank matrices from two significantly smaller matrices to approximate the full-rank matrix. Furthermore, we condense multilingual knowledge from multiple LS modules into a single shared module with the Fuse Distillation (FD) technique to improve the efficiency of inference and model serialization. We show that our LMS method significantly outperforms previous LS methods and MoE methods with the same amount of extra parameters, e.g., 1.73 BLEU points over the Switch Transformer on many-to-many multilingual machine translation. Importantly, LMS is able to have comparable translation performance with much fewer parameters.