 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpsample or Upweight? Balanced Training on Heavily Imbalanced Datasets
Oct 06, 2024



Data availability across domains often follows a long-tail distribution: a few domains have abundant data, while most face data scarcity. This imbalance poses challenges in training language models uniformly across all domains. In our study, we focus on multilingual settings, where data sizes vary significantly between high- and low-resource languages. Common strategies to address this include upsampling low-resource languages (Temperature Sampling) or upweighting their loss (Scalarization). Although often considered equivalent, this assumption has not been proven, which motivates our study. Through both theoretical and empirical analysis, we identify the conditions under which these approaches are equivalent and when they diverge. Specifically, we demonstrate that these two methods are equivalent under full gradient descent, but this equivalence breaks down with stochastic gradient descent. Empirically, we observe that Temperature Sampling converges more quickly but is prone to overfitting. We argue that this faster convergence is likely due to the lower variance in gradient estimations, as shown theoretically. Based on these insights, we propose Cooldown, a strategy that reduces sampling temperature during training, accelerating convergence without overfitting to low-resource languages. Our method is competitive with existing data re-weighting and offers computational efficiency.
It Takes Two: On the Seamlessness between Reward and Policy Model in RLHF
Jun 12, 2024Reinforcement Learning from Human Feedback (RLHF) involves training policy models (PMs) and reward models (RMs) to align language models with human preferences. Instead of focusing solely on PMs and RMs independently, we propose to examine their interactions during fine-tuning, introducing the concept of seamlessness. Our study starts with observing the saturation phenomenon, where continual improvements in RM and PM do not translate into RLHF progress. Our analysis shows that RMs fail to assign proper scores to PM responses, resulting in a 35% mismatch rate with human preferences, highlighting a significant discrepancy between PM and RM. To measure seamlessness between PM and RM without human effort, we propose an automatic metric, SEAM. SEAM quantifies the discrepancies between PM and RM judgments induced by data samples. We validate the effectiveness of SEAM in data selection and model augmentation. Our experiments demonstrate that (1) using SEAM-filtered data for RL training improves RLHF performance by 4.5%, and (2) SEAM-guided model augmentation results in a 4% performance improvement over standard augmentation methods.
DiffNorm: Self-Supervised Normalization for Non-autoregressive Speech-to-speech Translation
May 22, 2024



Non-autoregressive Transformers (NATs) are recently applied in direct speech-to-speech translation systems, which convert speech across different languages without intermediate text data. Although NATs generate high-quality outputs and offer faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to complex data distribution (e.g., acoustic and linguistic variations in speech). In this work, we introduce DiffNorm, a diffusion-based normalization strategy that simplifies data distributions for training NAT models. After training with a self-supervised noise estimation objective, DiffNorm constructs normalized target data by denoising synthetically corrupted speech features. Additionally, we propose to regularize NATs with classifier-free guidance, improving model robustness and translation quality by randomly dropping out source information during training. Our strategies result in a notable improvement of about +7 ASR-BLEU for English-Spanish (En-Es) and +2 ASR-BLEU for English-French (En-Fr) translations on the CVSS benchmark, while attaining over 14x speedup for En-Es and 5x speedup for En-Fr translations compared to autoregressive baselines.
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation
Feb 02, 2024



Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, does not match the performance of state-of-the-art conventional encoder-decoder translation models or larger-scale LLMs such as GPT-4. In this study, we bridge this performance gap. We first assess the shortcomings of supervised fine-tuning for LLMs in the MT task, emphasizing the quality issues present in the reference data, despite being human-generated. Then, in contrast to SFT which mimics reference translations, we introduce Contrastive Preference Optimization (CPO), a novel approach that trains models to avoid generating adequate but not perfect translations. Applying CPO to ALMA models with only 22K parallel sentences and 12M parameters yields significant improvements. The resulting model, called ALMA-R, can match or exceed the performance of the WMT competition winners and GPT-4 on WMT'21, WMT'22 and WMT'23 test datasets.
Streaming Sequence Transduction through Dynamic Compression
Feb 02, 2024



We introduce STAR (Stream Transduction with Anchor Representations), a novel Transformer-based model designed for efficient sequence-to-sequence transduction over streams. STAR dynamically segments input streams to create compressed anchor representations, achieving nearly lossless compression (12x) in Automatic Speech Recognition (ASR) and outperforming existing methods. Moreover, STAR demonstrates superior segmentation and latency-quality trade-offs in simultaneous speech-to-text tasks, optimizing latency, memory footprint, and quality.
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts
Jan 23, 2024



As the influence of large language models (LLMs) spans across global communities, their safety challenges in multilingual settings become paramount for alignment research. This paper examines the variations in safety challenges faced by LLMs across different languages and discusses approaches to alleviating such concerns. By comparing how state-of-the-art LLMs respond to the same set of malicious prompts written in higher- vs. lower-resource languages, we observe that (1) LLMs tend to generate unsafe responses much more often when a malicious prompt is written in a lower-resource language, and (2) LLMs tend to generate more irrelevant responses to malicious prompts in lower-resource languages. To understand where the discrepancy can be attributed, we study the effect of instruction tuning with reinforcement learning from human feedback (RLHF) or supervised finetuning (SFT) on the HH-RLHF dataset. Surprisingly, while training with high-resource languages improves model alignment, training in lower-resource languages yields minimal improvement. This suggests that the bottleneck of cross-lingual alignment is rooted in the pretraining stage. Our findings highlight the challenges in cross-lingual LLM safety, and we hope they inform future research in this direction.
Structure-Aware Path Inference for Neural Finite State Transducers
Dec 21, 2023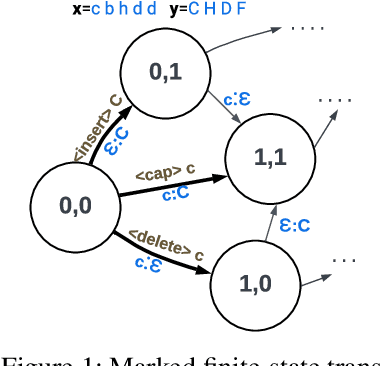


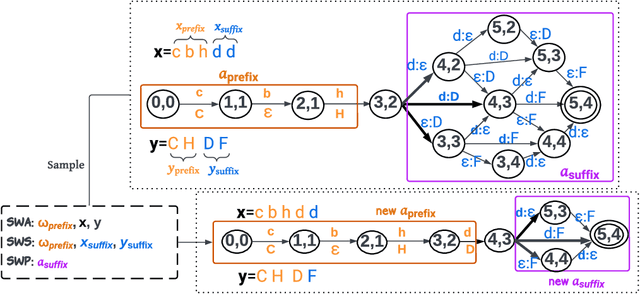
Neural finite-state transducers (NFSTs) form an expressive family of neurosymbolic sequence transduction models. An NFST models each string pair as having been generated by a latent path in a finite-state transducer. As they are deep generative models, both training and inference of NFSTs require inference networks that approximate posterior distributions over such latent variables. In this paper, we focus on the resulting challenge of imputing the latent alignment path that explains a given pair of input and output strings (e.g., during training). We train three autoregressive approximate models for amortized inference of the path, which can then be used as proposal distributions for importance sampling. All three models perform lookahead. Our most sophisticated (and novel) model leverages the FST structure to consider the graph of future paths; unfortunately, we find that it loses out to the simpler approaches -- except on an artificial task that we concocted to confuse the simpler approaches.
Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles
Nov 04, 2023



Large language models trained primarily in a monolingual setting have demonstrated their ability to generalize to machine translation using zero- and few-shot examples with in-context learning. However, even though zero-shot translations are relatively good, there remains a discernible gap comparing their performance with the few-shot setting. In this paper, we investigate the factors contributing to this gap and find that this gap can largely be closed (for about 70%) by matching the writing styles of the target corpus. Additionally, we explore potential approaches to enhance zero-shot baselines without the need for parallel demonstration examples, providing valuable insights into how these methods contribute to improving translation metrics.
Condensing Multilingual Knowledge with Lightweight Language-Specific Modules
May 23, 2023Incorporating language-specific (LS) modules is a proven method to boost performance in multilingual machine translation. This approach bears similarity to Mixture-of-Experts (MoE) because it does not inflate FLOPs. However, the scalability of this approach to hundreds of languages (experts) tends to be unmanageable due to the prohibitive number of parameters introduced by full-rank matrices in fully-connected layers. In this work, we introduce the Language-Specific Matrix Synthesis (LMS) method. This approach constructs LS modules by generating low-rank matrices from two significantly smaller matrices to approximate the full-rank matrix. Furthermore, we condense multilingual knowledge from multiple LS modules into a single shared module with the Fuse Distillation (FD) technique to improve the efficiency of inference and model serialization. We show that our LMS method significantly outperforms previous LS methods and MoE methods with the same amount of extra parameters, e.g., 1.73 BLEU points over the Switch Transformer on many-to-many multilingual machine translation. Importantly, LMS is able to have comparable translation performance with much fewer parameters.
Flatness-Aware Prompt Selection Improves Accuracy and Sample Efficiency
May 18, 2023



With growing capabilities of large language models, prompting them has become the dominant way to access them. This has motivated the development of strategies for automatically selecting effective language prompts. In this paper, we introduce prompt flatness, a new metric to quantify the expected utility of a language prompt. This metric is inspired by flatness regularization in statistical learning that quantifies the robustness of the model towards its parameter perturbations. We provide theoretical foundations for this metric and its relationship with other prompt selection metrics, providing a comprehensive understanding of existing methods. Empirically, we show that combining prompt flatness with existing metrics improves both performance and sample efficiency. Our metric outperforms the previous prompt selection metrics with an average increase of 5% in accuracy and 10% in Pearson correlation across 6 classification benchmarks.