 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Tier Instruction Hierarchy in LLM Agents
Apr 14, 2026Large language model agents receive instructions from many sources-system messages, user prompts, tool outputs, other agents, and more-each carrying different levels of trust and authority. When these instructions conflict, agents must reliably follow the highest-privilege instruction to remain safe and effective. The dominant paradigm, instruction hierarchy (IH), assumes a fixed, small set of privilege levels (typically fewer than five) defined by rigid role labels (e.g., system > user). This is inadequate for real-world agentic settings, where conflicts can arise across far more sources and contexts. In this work, we propose Many-Tier Instruction Hierarchy (ManyIH), a paradigm for resolving instruction conflicts among instructions with arbitrarily many privilege levels. We introduce ManyIH-Bench, the first benchmark for ManyIH. ManyIH-Bench requires models to navigate up to 12 levels of conflicting instructions with varying privileges, comprising 853 agentic tasks (427 coding and 426 instruction-following). ManyIH-Bench composes constraints developed by LLMs and verified by humans to create realistic and difficult test cases spanning 46 real-world agents. Our experiments show that even the current frontier models perform poorly (~40% accuracy) when instruction conflict scales. This work underscores the urgent need for methods that explicitly target fine-grained, scalable instruction conflict resolution in agentic settings.
Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
Feb 05, 2026High-quality kernel is critical for scalable AI systems, and enabling LLMs to generate such code would advance AI development. However, training LLMs for this task requires sufficient data, a robust environment, and the process is often vulnerable to reward hacking and lazy optimization. In these cases, models may hack training rewards and prioritize trivial correctness over meaningful speedup. In this paper, we systematically study reinforcement learning (RL) for kernel generation. We first design KernelGYM, a robust distributed GPU environment that supports reward hacking check, data collection from multi-turn interactions and long-term RL training. Building on KernelGYM, we investigate effective multi-turn RL methods and identify a biased policy gradient issue caused by self-inclusion in GRPO. To solve this, we propose Turn-level Reinforce-Leave-One-Out (TRLOO) to provide unbiased advantage estimation for multi-turn RL. To alleviate lazy optimization, we incorporate mismatch correction for training stability and introduce Profiling-based Rewards (PR) and Profiling-based Rejection Sampling (PRS) to overcome the issue. The trained model, Dr.Kernel-14B, reaches performance competitive with Claude-4.5-Sonnet in Kernelbench. Finally, we study sequential test-time scaling for Dr.Kernel-14B. On the KernelBench Level-2 subset, 31.6% of the generated kernels achieve at least a 1.2x speedup over the Torch reference, surpassing Claude-4.5-Sonnet (26.7%) and GPT-5 (28.6%). When selecting the best candidate across all turns, this 1.2x speedup rate further increases to 47.8%. All resources, including environment, training code, models, and dataset, are included in https://www.github.com/hkust-nlp/KernelGYM.
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Sep 09, 2025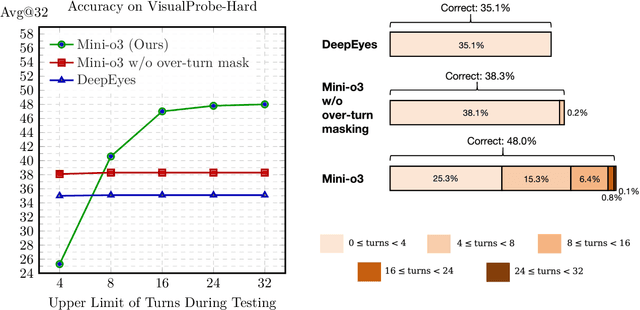
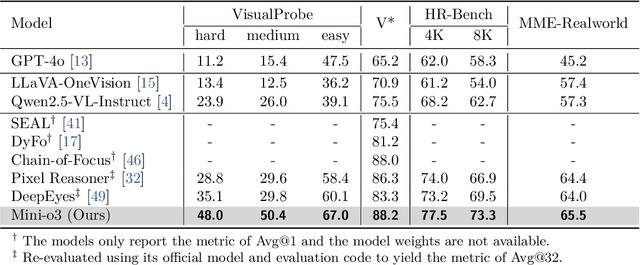


Recent advances in large multimodal models have leveraged image-based tools with reinforcement learning to tackle visual problems. However, existing open-source approaches often exhibit monotonous reasoning patterns and allow only a limited number of interaction turns, making them inadequate for difficult tasks that require trial-and-error exploration. In this work, we address this limitation by scaling up tool-based interactions and introduce Mini-o3, a system that executes deep, multi-turn reasoning -- spanning tens of steps -- and achieves state-of-the-art performance on challenging visual search tasks. Our recipe for reproducing OpenAI o3-style behaviors comprises three key components. First, we construct the Visual Probe Dataset, a collection of thousands of challenging visual search problems designed for exploratory reasoning. Second, we develop an iterative data collection pipeline to obtain cold-start trajectories that exhibit diverse reasoning patterns, including depth-first search, trial-and-error, and goal maintenance. Third, we propose an over-turn masking strategy that prevents penalization of over-turn responses (those that hit the maximum number of turns) during reinforcement learning, thereby balancing training-time efficiency with test-time scalability. Despite training with an upper bound of only six interaction turns, our model generates trajectories that naturally scale to tens of turns at inference time, with accuracy improving as the number of turns increases. Extensive experiments demonstrate that Mini-o3 produces rich reasoning patterns and deep thinking paths, effectively solving challenging visual search problems.
ZeCO: Zero Communication Overhead Sequence Parallelism for Linear Attention
Jul 02, 2025Linear attention mechanisms deliver significant advantages for Large Language Models (LLMs) by providing linear computational complexity, enabling efficient processing of ultra-long sequences (e.g., 1M context). However, existing Sequence Parallelism (SP) methods, essential for distributing these workloads across devices, become the primary bottleneck due to substantial communication overhead. In this paper, we introduce ZeCO (Zero Communication Overhead) sequence parallelism for linear attention models, a new SP method designed to overcome these limitations and achieve end-to-end near-linear scalability for long sequence training. For example, training a model with a 1M sequence length across 64 devices using ZeCO takes roughly the same time as training with an 16k sequence on a single device. At the heart of ZeCO lies All-Scan, a new collective communication primitive. All-Scan provides each SP rank with precisely the initial operator state it requires while maintaining a minimal communication footprint, effectively eliminating communication overhead. Theoretically, we prove the optimaity of ZeCO, showing that it introduces only negligible time and space overhead. Empirically, we compare the communication costs of different sequence parallelism strategies and demonstrate that All-Scan achieves the fastest communication in SP scenarios. Specifically, on 256 GPUs with an 8M sequence length, ZeCO achieves a 60\% speedup compared to the current state-of-the-art (SOTA) SP method. We believe ZeCO establishes a clear path toward efficiently training next-generation LLMs on previously intractable sequence lengths.
SIMPLEMIX: Frustratingly Simple Mixing of Off- and On-policy Data in Language Model Preference Learning
May 05, 2025Aligning language models with human preferences relies on pairwise preference datasets. While some studies suggest that on-policy data consistently outperforms off -policy data for preference learning, others indicate that the advantages of on-policy data may be task-dependent, highlighting the need for a systematic exploration of their interplay. In this work, we show that on-policy and off-policy data offer complementary strengths in preference optimization: on-policy data is particularly effective for reasoning tasks like math and coding, while off-policy data performs better on open-ended tasks such as creative writing and making personal recommendations. Guided by these findings, we introduce SIMPLEMIX, an approach to combine the complementary strengths of on-policy and off-policy preference learning by simply mixing these two data sources. Our empirical results across diverse tasks and benchmarks demonstrate that SIMPLEMIX substantially improves language model alignment. Specifically, SIMPLEMIX improves upon on-policy DPO and off-policy DPO by an average of 6.03% on Alpaca Eval 2.0. Moreover, it outperforms prior approaches that are much more complex in combining on- and off-policy data, such as HyPO and DPO-Mix-P, by an average of 3.05%.
Upsample or Upweight? Balanced Training on Heavily Imbalanced Datasets
Oct 06, 2024



Data availability across domains often follows a long-tail distribution: a few domains have abundant data, while most face data scarcity. This imbalance poses challenges in training language models uniformly across all domains. In our study, we focus on multilingual settings, where data sizes vary significantly between high- and low-resource languages. Common strategies to address this include upsampling low-resource languages (Temperature Sampling) or upweighting their loss (Scalarization). Although often considered equivalent, this assumption has not been proven, which motivates our study. Through both theoretical and empirical analysis, we identify the conditions under which these approaches are equivalent and when they diverge. Specifically, we demonstrate that these two methods are equivalent under full gradient descent, but this equivalence breaks down with stochastic gradient descent. Empirically, we observe that Temperature Sampling converges more quickly but is prone to overfitting. We argue that this faster convergence is likely due to the lower variance in gradient estimations, as shown theoretically. Based on these insights, we propose Cooldown, a strategy that reduces sampling temperature during training, accelerating convergence without overfitting to low-resource languages. Our method is competitive with existing data re-weighting and offers computational efficiency.
Benchmarking Language Model Creativity: A Case Study on Code Generation
Jul 12, 2024



As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: \emph{convergent} thinking (purposefulness to achieve a given goal) and \emph{divergent} thinking (adaptability to new environments or constraints) \citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data
Apr 05, 2024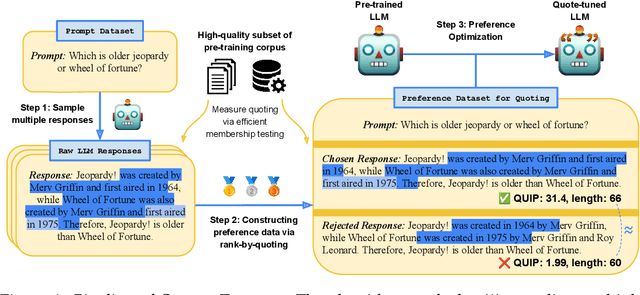

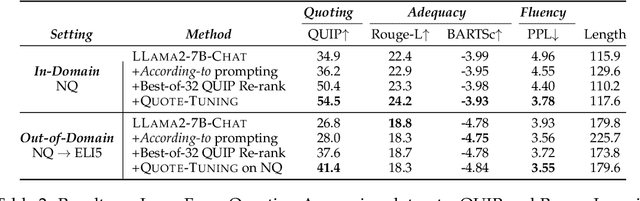
For humans to trust the fluent generations of large language models (LLMs), they must be able to verify their correctness against trusted, external sources. Recent efforts aim to increase verifiability through citations of retrieved documents or post-hoc provenance. However, such citations are prone to mistakes that further complicate their verifiability. To address these limitations, we tackle the verifiability goal with a different philosophy: we trivialize the verification process by developing models that quote verbatim statements from trusted sources in pre-training data. We propose Quote-Tuning, which demonstrates the feasibility of aligning LLMs to leverage memorized information and quote from pre-training data. Quote-Tuning quantifies quoting against large corpora with efficient membership inference tools, and uses the amount of quotes as an implicit reward signal to construct a synthetic preference dataset for quoting, without any human annotation. Next, the target model is aligned to quote using preference optimization algorithms. Experimental results show that Quote-Tuning significantly increases the percentage of LLM generation quoted verbatim from high-quality pre-training documents by 55% to 130% relative to untuned models while maintaining response quality. Further experiments demonstrate that Quote-Tuning generalizes quoting to out-of-domain data, is applicable in different tasks, and provides additional benefits to truthfulness. Quote-Tuning not only serves as a hassle-free method to increase quoting but also opens up avenues for improving LLM trustworthiness through better verifiability.
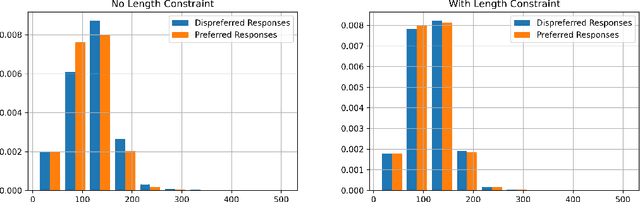
Error Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models
Oct 02, 2023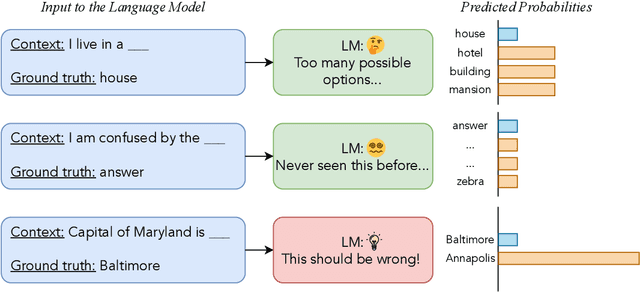
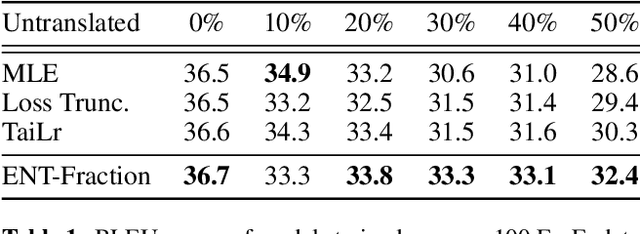

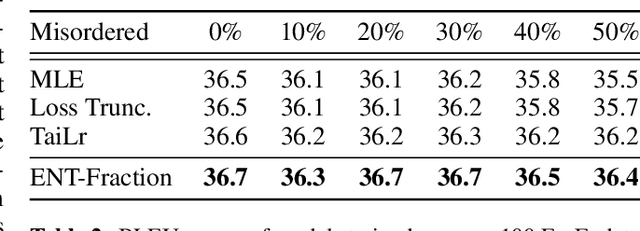
Text generation models are notoriously vulnerable to errors in the training data. With the wide-spread availability of massive amounts of web-crawled data becoming more commonplace, how can we enhance the robustness of models trained on a massive amount of noisy web-crawled text? In our work, we propose Error Norm Truncation (ENT), a robust enhancement method to the standard training objective that truncates noisy data. Compared to methods that only uses the negative log-likelihood loss to estimate data quality, our method provides a more accurate estimation by considering the distribution of non-target tokens, which is often overlooked by previous work. Through comprehensive experiments across language modeling, machine translation, and text summarization, we show that equipping text generation models with ENT improves generation quality over standard training and previous soft and hard truncation methods. Furthermore, we show that our method improves the robustness of models against two of the most detrimental types of noise in machine translation, resulting in an increase of more than 2 BLEU points over the MLE baseline when up to 50% of noise is added to the data.