 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Checklist: On Unit-Testing Datasets with Usable Information
Aug 06, 2024



Model checklists (Ribeiro et al., 2020) have emerged as a useful tool for understanding the behavior of LLMs, analogous to unit-testing in software engineering. However, despite datasets being a key determinant of model behavior, evaluating datasets, e.g., for the existence of annotation artifacts, is largely done ad hoc, once a problem in model behavior has already been found downstream. In this work, we take a more principled approach to unit-testing datasets by proposing a taxonomy based on the V-information literature. We call a collection of such unit tests a data checklist. Using a checklist, not only are we able to recover known artifacts in well-known datasets such as SNLI, but we also discover previously unknown artifacts in preference datasets for LLM alignment. Data checklists further enable a new kind of data filtering, which we use to improve the efficacy and data efficiency of preference alignment.
SPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing
Jun 01, 2024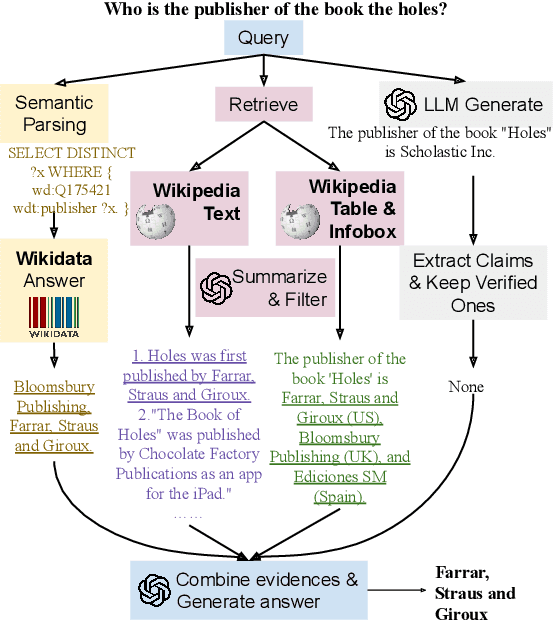
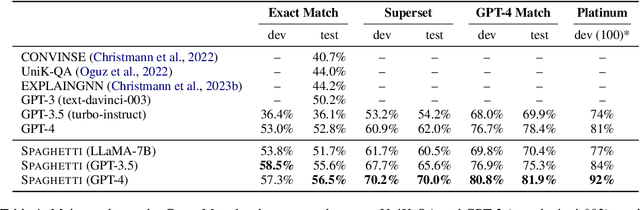


We introduce SPAGHETTI: Semantic Parsing Augmented Generation for Hybrid English information from Text Tables and Infoboxes, a hybrid question-answering (QA) pipeline that utilizes information from heterogeneous knowledge sources, including knowledge base, text, tables, and infoboxes. Our LLM-augmented approach achieves state-of-the-art performance on the Compmix dataset, the most comprehensive heterogeneous open-domain QA dataset, with 56.5% exact match (EM) rate. More importantly, manual analysis on a sample of the dataset suggests that SPAGHETTI is more than 90% accurate, indicating that EM is no longer suitable for assessing the capabilities of QA systems today.
Streaming Sequence Transduction through Dynamic Compression
Feb 02, 2024We introduce STAR (Stream Transduction with Anchor Representations), a novel Transformer-based model designed for efficient sequence-to-sequence transduction over streams. STAR dynamically segments input streams to create compressed anchor representations, achieving nearly lossless compression (12x) in Automatic Speech Recognition (ASR) and outperforming existing methods. Moreover, STAR demonstrates superior segmentation and latency-quality trade-offs in simultaneous speech-to-text tasks, optimizing latency, memory footprint, and quality.
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023



Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.