 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Know to Respect Copyright Notice?
Nov 02, 2024



Prior study shows that LLMs sometimes generate content that violates copyright. In this paper, we study another important yet underexplored problem, i.e., will LLMs respect copyright information in user input, and behave accordingly? The research problem is critical, as a negative answer would imply that LLMs will become the primary facilitator and accelerator of copyright infringement behavior. We conducted a series of experiments using a diverse set of language models, user prompts, and copyrighted materials, including books, news articles, API documentation, and movie scripts. Our study offers a conservative evaluation of the extent to which language models may infringe upon copyrights when processing user input containing protected material. This research emphasizes the need for further investigation and the importance of ensuring LLMs respect copyright regulations when handling user input to prevent unauthorized use or reproduction of protected content. We also release a benchmark dataset serving as a test bed for evaluating infringement behaviors by LLMs and stress the need for future alignment.
SPINACH: SPARQL-Based Information Navigation for Challenging Real-World Questions
Jul 16, 2024

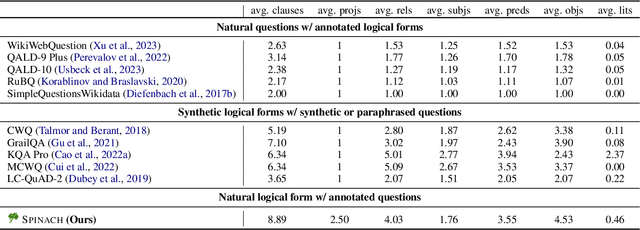
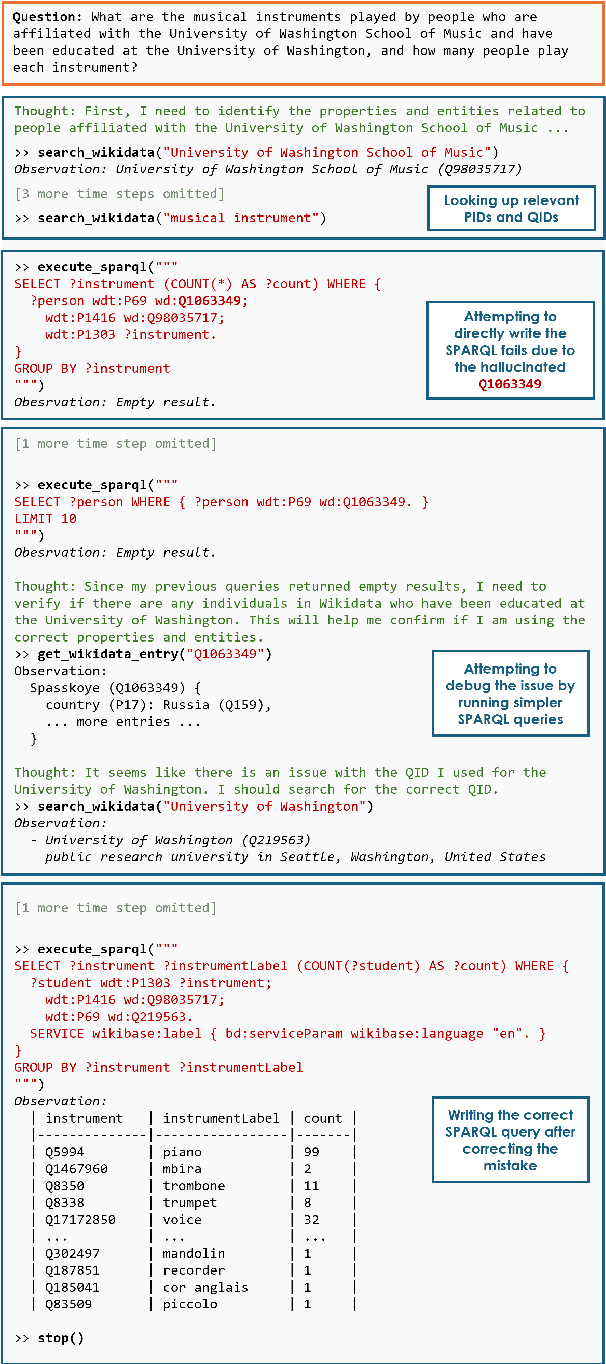
Recent work integrating Large Language Models (LLMs) has led to significant improvements in the Knowledge Base Question Answering (KBQA) task. However, we posit that existing KBQA datasets that either have simple questions, use synthetically generated logical forms, or are based on small knowledge base (KB) schemas, do not capture the true complexity of KBQA tasks. To address this, we introduce the SPINACH dataset, an expert-annotated KBQA dataset collected from forum discussions on Wikidata's "Request a Query" forum with 320 decontextualized question-SPARQL pairs. Much more complex than existing datasets, SPINACH calls for strong KBQA systems that do not rely on training data to learn the KB schema, but can dynamically explore large and often incomplete schemas and reason about them. Along with the dataset, we introduce the SPINACH agent, a new KBQA approach that mimics how a human expert would write SPARQLs for such challenging questions. Experiments on existing datasets show SPINACH's capability in KBQA, achieving a new state of the art on the QALD-7, QALD-9 Plus and QALD-10 datasets by 30.1%, 27.0%, and 10.0% in F1, respectively, and coming within 1.6% of the fine-tuned LLaMA SOTA model on WikiWebQuestions. On our new SPINACH dataset, SPINACH agent outperforms all baselines, including the best GPT-4-based KBQA agent, by 38.1% in F1.
SPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing
Jun 01, 2024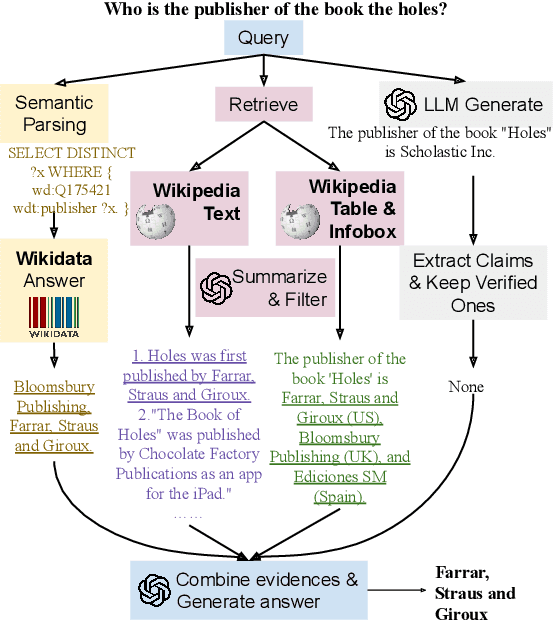
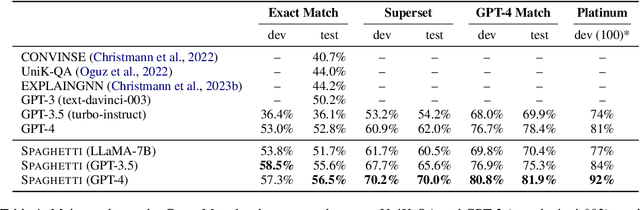


We introduce SPAGHETTI: Semantic Parsing Augmented Generation for Hybrid English information from Text Tables and Infoboxes, a hybrid question-answering (QA) pipeline that utilizes information from heterogeneous knowledge sources, including knowledge base, text, tables, and infoboxes. Our LLM-augmented approach achieves state-of-the-art performance on the Compmix dataset, the most comprehensive heterogeneous open-domain QA dataset, with 56.5% exact match (EM) rate. More importantly, manual analysis on a sample of the dataset suggests that SPAGHETTI is more than 90% accurate, indicating that EM is no longer suitable for assessing the capabilities of QA systems today.
Reverse Image Retrieval Cues Parametric Memory in Multimodal LLMs
May 29, 2024



Despite impressive advances in recent multimodal large language models (MLLMs), state-of-the-art models such as from the GPT-4 suite still struggle with knowledge-intensive tasks. To address this, we consider Reverse Image Retrieval (RIR) augmented generation, a simple yet effective strategy to augment MLLMs with web-scale reverse image search results. RIR robustly improves knowledge-intensive visual question answering (VQA) of GPT-4V by 37-43%, GPT-4 Turbo by 25-27%, and GPT-4o by 18-20% in terms of open-ended VQA evaluation metrics. To our surprise, we discover that RIR helps the model to better access its own world knowledge. Concretely, our experiments suggest that RIR augmentation helps by providing further visual and textual cues without necessarily containing the direct answer to a query. In addition, we elucidate cases in which RIR can hurt performance and conduct a human evaluation. Finally, we find that the overall advantage of using RIR makes it difficult for an agent that can choose to use RIR to perform better than an approach where RIR is the default setting.
InfoPattern: Unveiling Information Propagation Patterns in Social Media
Nov 27, 2023



Social media play a significant role in shaping public opinion and influencing ideological communities through information propagation. Our demo InfoPattern centers on the interplay between language and human ideology. The demo (Code: https://github.com/blender-nlp/InfoPattern ) is capable of: (1) red teaming to simulate adversary responses from opposite ideology communities; (2) stance detection to identify the underlying political sentiments in each message; (3) information propagation graph discovery to reveal the evolution of claims across various communities over time. (Live Demo: https://incas.csl.illinois.edu/blender/About )
SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models
Nov 16, 2023



Many knowledge sources consist of both structured information such as relational databases as well as unstructured free text. Building a conversational interface to such data sources is challenging. This paper introduces SUQL, Structured and Unstructured Query Language, the first formal executable representation that naturally covers compositions of structured and unstructured data queries. Specifically, it augments SQL with several free-text primitives to form a precise, succinct, and expressive representation. This paper also presents a conversational search agent based on large language models, including a few-shot contextual semantic parser for SUQL. To validate our approach, we introduce a dataset consisting of crowdsourced questions and conversations about real restaurants. Over 51% of the questions in the dataset require both structured and unstructured data, suggesting that it is a common phenomenon. We show that our few-shot conversational agent based on SUQL finds an entity satisfying all user requirements 89.3% of the time, compared to just 65.0% for a strong and commonly used baseline.
LM-Switch: Lightweight Language Model Conditioning in Word Embedding Space
May 22, 2023
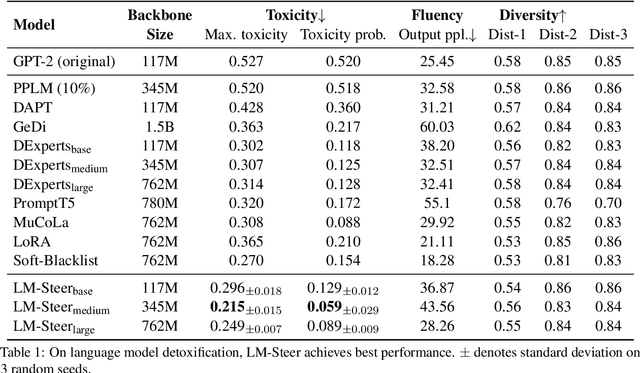


In recent years, large language models (LMs) have achieved remarkable progress across various natural language processing tasks. As pre-training and fine-tuning are costly and might negatively impact model performance, it is desired to efficiently adapt an existing model to different conditions such as styles, sentiments or narratives, when facing different audiences or scenarios. However, efficient adaptation of a language model to diverse conditions remains an open challenge. This work is inspired by the observation that text conditions are often associated with selection of certain words in a context. Therefore we introduce LM-Switch, a theoretically grounded, lightweight and simple method for generative language model conditioning. We begin by investigating the effect of conditions in Hidden Markov Models (HMMs), and establish a theoretical connection with language model. Our finding suggests that condition shifts in HMMs are associated with linear transformations in word embeddings. LM-Switch is then designed to deploy a learnable linear factor in the word embedding space for language model conditioning. We show that LM-Switch can model diverse tasks, and achieves comparable or better performance compared with state-of-the-art baselines in LM detoxification and generation control, despite requiring no more than 1% of parameters compared with baselines and little extra time overhead compared with base LMs. It is also able to learn from as few as a few sentences or one document. Moreover, a learned LM-Switch can be transferred to other LMs of different sizes, achieving a detoxification performance similar to the best baseline. We will make our code available to the research community following publication.
LUNA: Language Understanding with Number Augmentations on Transformers via Number Plugins and Pre-training
Dec 06, 2022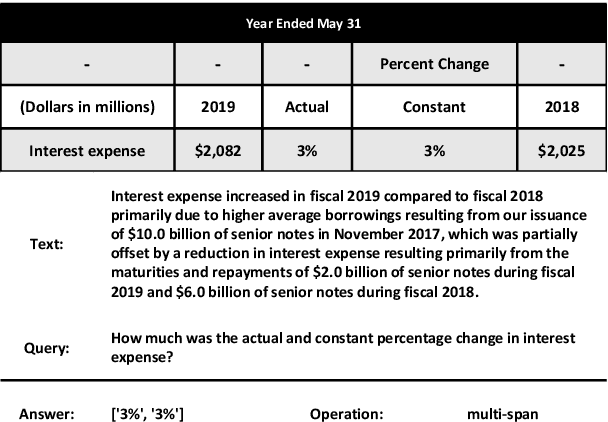
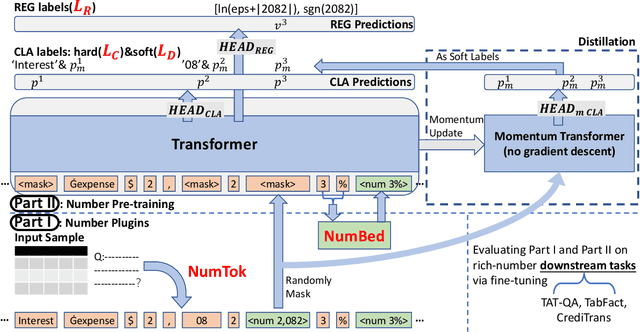

Transformers are widely used in NLP tasks. However, current approaches to leveraging transformers to understand language expose one weak spot: Number understanding. In some scenarios, numbers frequently occur, especially in semi-structured data like tables. But current approaches to rich-number tasks with transformer-based language models abandon or lose some of the numeracy information - e.g., breaking numbers into sub-word tokens - which leads to many number-related errors. In this paper, we propose the LUNA framework which improves the numerical reasoning and calculation capabilities of transformer-based language models. With the number plugin of NumTok and NumBed, LUNA represents each number as a whole to model input. With number pre-training, including regression loss and model distillation, LUNA bridges the gap between number and vocabulary embeddings. To the best of our knowledge, this is the first work that explicitly injects numeracy capability into language models using Number Plugins. Besides evaluating toy models on toy tasks, we evaluate LUNA on three large-scale transformer models (RoBERTa, BERT, TabBERT) over three different downstream tasks (TATQA, TabFact, CrediTrans), and observe the performances of language models are constantly improved by LUNA. The augmented models also improve the official baseline of TAT-QA (EM: 50.15 -> 59.58) and achieve SOTA performance on CrediTrans (F1 = 86.17).
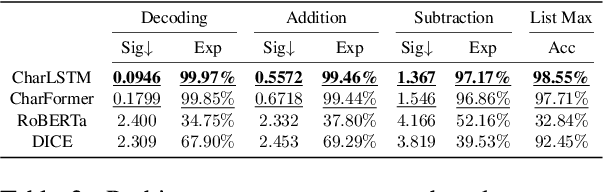
Towards Robust Numerical Question Answering: Diagnosing Numerical Capabilities of NLP Systems
Nov 14, 2022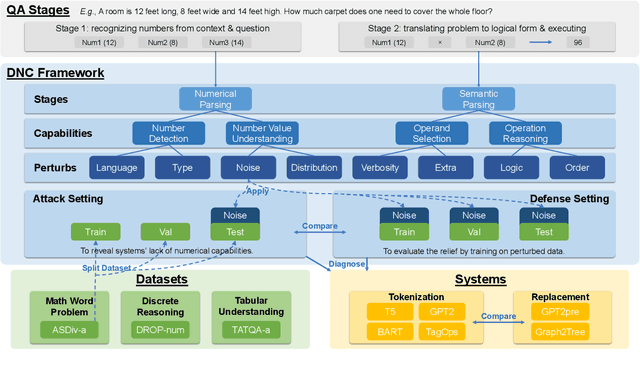
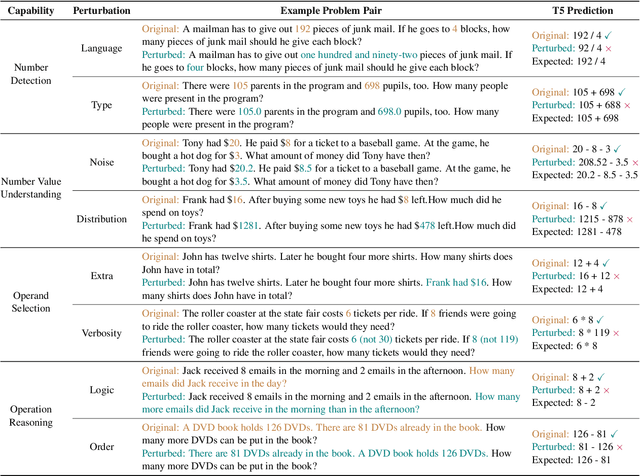
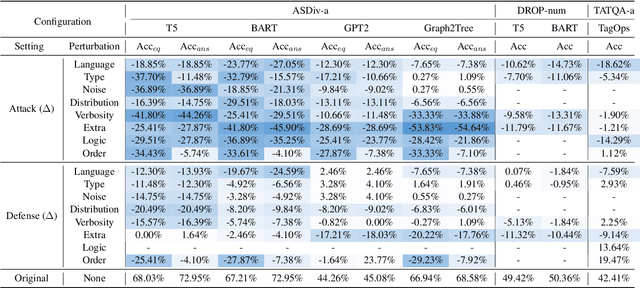
Numerical Question Answering is the task of answering questions that require numerical capabilities. Previous works introduce general adversarial attacks to Numerical Question Answering, while not systematically exploring numerical capabilities specific to the topic. In this paper, we propose to conduct numerical capability diagnosis on a series of Numerical Question Answering systems and datasets. A series of numerical capabilities are highlighted, and corresponding dataset perturbations are designed. Empirical results indicate that existing systems are severely challenged by these perturbations. E.g., Graph2Tree experienced a 53.83% absolute accuracy drop against the ``Extra'' perturbation on ASDiv-a, and BART experienced 13.80% accuracy drop against the ``Language'' perturbation on the numerical subset of DROP. As a counteracting approach, we also investigate the effectiveness of applying perturbations as data augmentation to relieve systems' lack of robust numerical capabilities. With experiment analysis and empirical studies, it is demonstrated that Numerical Question Answering with robust numerical capabilities is still to a large extent an open question. We discuss future directions of Numerical Question Answering and summarize guidelines on future dataset collection and system design.
Inferring Tabular Analysis Metadata by Infusing Distribution and Knowledge Information
Sep 02, 2022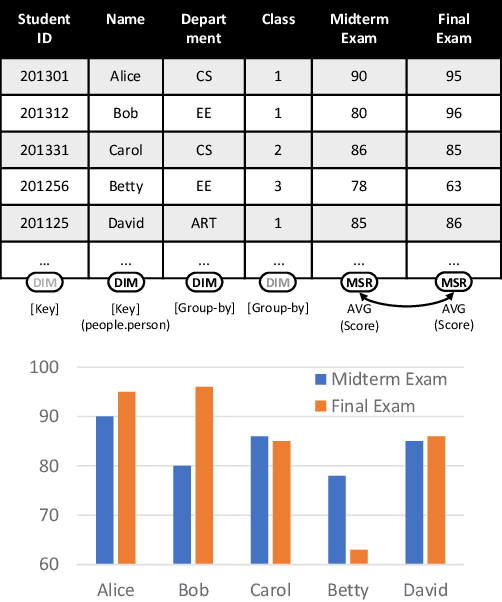
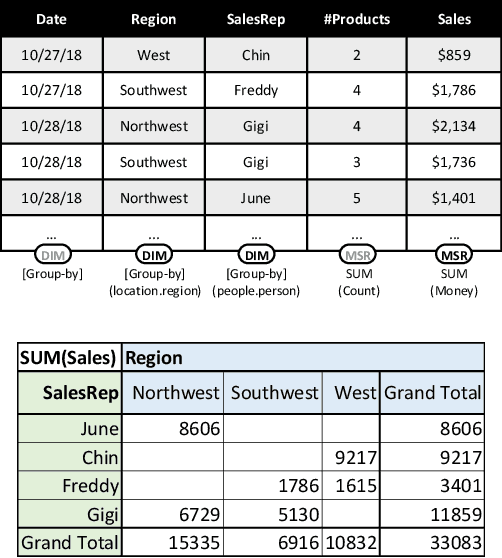
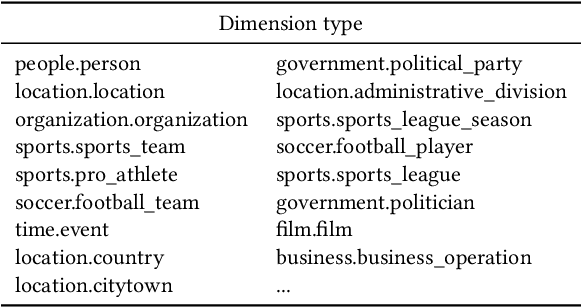
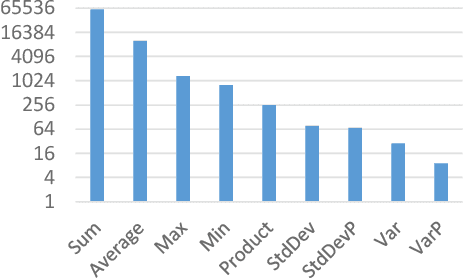
Many data analysis tasks heavily rely on a deep understanding of tables (multi-dimensional data). Across the tasks, there exist comonly used metadata attributes of table fields / columns. In this paper, we identify four such analysis metadata: Measure/dimension dichotomy, common field roles, semantic field type, and default aggregation function. While those metadata face challenges of insufficient supervision signals, utilizing existing knowledge and understanding distribution. To inference these metadata for a raw table, we propose our multi-tasking Metadata model which fuses field distribution and knowledge graph information into pre-trained tabular models. For model training and evaluation, we collect a large corpus (~582k tables from private spreadsheet and public tabular datasets) of analysis metadata by using diverse smart supervisions from downstream tasks. Our best model has accuracy = 98%, hit rate at top-1 > 67%, accuracy > 80%, and accuracy = 88% for the four analysis metadata inference tasks, respectively. It outperforms a series of baselines that are based on rules, traditional machine learning methods, and pre-trained tabular models. Analysis metadata models are deployed in a popular data analysis product, helping downstream intelligent features such as insights mining, chart / pivot table recommendation, and natural language QA...