 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Tabular Analysis Metadata by Infusing Distribution and Knowledge Information
Paper and Code
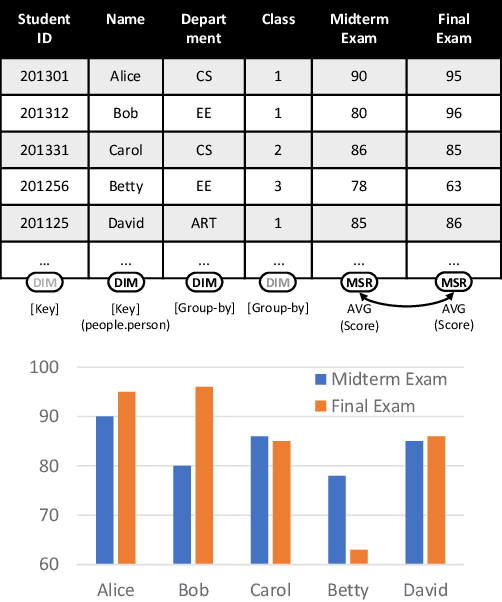
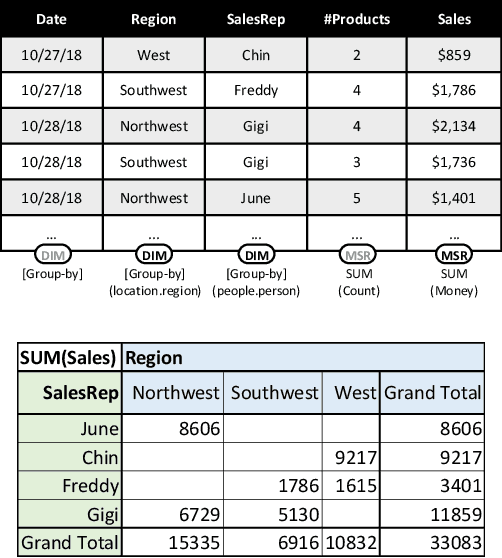
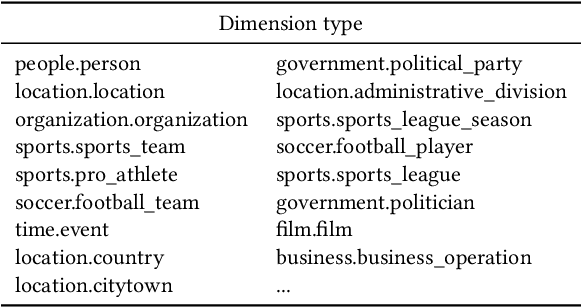
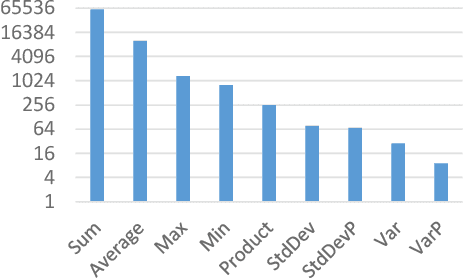
Many data analysis tasks heavily rely on a deep understanding of tables (multi-dimensional data). Across the tasks, there exist comonly used metadata attributes of table fields / columns. In this paper, we identify four such analysis metadata: Measure/dimension dichotomy, common field roles, semantic field type, and default aggregation function. While those metadata face challenges of insufficient supervision signals, utilizing existing knowledge and understanding distribution. To inference these metadata for a raw table, we propose our multi-tasking Metadata model which fuses field distribution and knowledge graph information into pre-trained tabular models. For model training and evaluation, we collect a large corpus (~582k tables from private spreadsheet and public tabular datasets) of analysis metadata by using diverse smart supervisions from downstream tasks. Our best model has accuracy = 98%, hit rate at top-1 > 67%, accuracy > 80%, and accuracy = 88% for the four analysis metadata inference tasks, respectively. It outperforms a series of baselines that are based on rules, traditional machine learning methods, and pre-trained tabular models. Analysis metadata models are deployed in a popular data analysis product, helping downstream intelligent features such as insights mining, chart / pivot table recommendation, and natural language QA...