 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correction is More than Refinement: A Learning Framework for Visual and Language Reasoning Tasks
Oct 05, 2024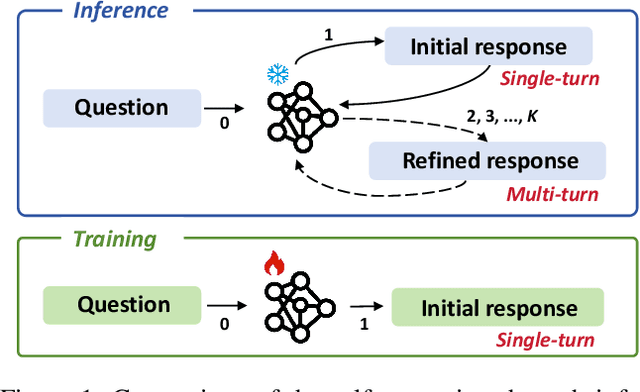
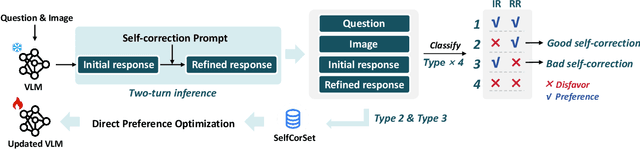
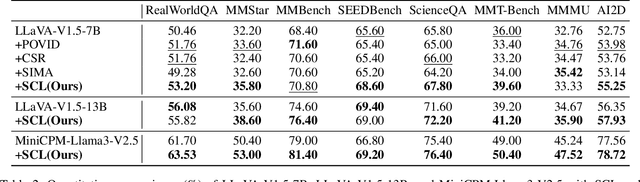
While Vision-Language Models (VLMs) have shown remarkable abilities in visual and language reasoning tasks, they invariably generate flawed responses. Self-correction that instructs models to refine their outputs presents a promising solution to this issue. Previous studies have mainly concentrated on Large Language Models (LLMs), while the self-correction abilities of VLMs, particularly concerning both visual and linguistic information, remain largely unexamined. This study investigates the self-correction capabilities of VLMs during both inference and fine-tuning stages. We introduce a Self-Correction Learning (SCL) approach that enables VLMs to learn from their self-generated self-correction data through Direct Preference Optimization (DPO) without relying on external feedback, facilitating self-improvement. Specifically, we collect preferred and disfavored samples based on the correctness of initial and refined responses, which are obtained by two-turn self-correction with VLMs during the inference stage. Experimental results demonstrate that although VLMs struggle to self-correct effectively during iterative inference without additional fine-tuning and external feedback, they can enhance their performance and avoid previous mistakes through preference fine-tuning when their self-generated self-correction data are categorized into preferred and disfavored samples. This study emphasizes that self-correction is not merely a refinement process; rather, it should enhance the reasoning abilities of models through additional training, enabling them to generate high-quality responses directly without further refinement.
Massively Multi-Cultural Knowledge Acquisition & LM Benchmarking
Feb 14, 2024



Pretrained large language models have revolutionized many applications but still face challenges related to cultural bias and a lack of cultural commonsense knowledge crucial for guiding cross-culture communication and interactions. Recognizing the shortcomings of existing methods in capturing the diverse and rich cultures across the world, this paper introduces a novel approach for massively multicultural knowledge acquisition. Specifically, our method strategically navigates from densely informative Wikipedia documents on cultural topics to an extensive network of linked pages. Leveraging this valuable source of data collection, we construct the CultureAtlas dataset, which covers a wide range of sub-country level geographical regions and ethnolinguistic groups, with data cleaning and preprocessing to ensure textual assertion sentence self-containment, as well as fine-grained cultural profile information extraction. Our dataset not only facilitates the evaluation of language model performance in culturally diverse contexts but also serves as a foundational tool for the development of culturally sensitive and aware language models. Our work marks an important step towards deeper understanding and bridging the gaps of cultural disparities in AI, to promote a more inclusive and balanced representation of global cultures in the digital domain.
LM-Switch: Lightweight Language Model Conditioning in Word Embedding Space
May 22, 2023
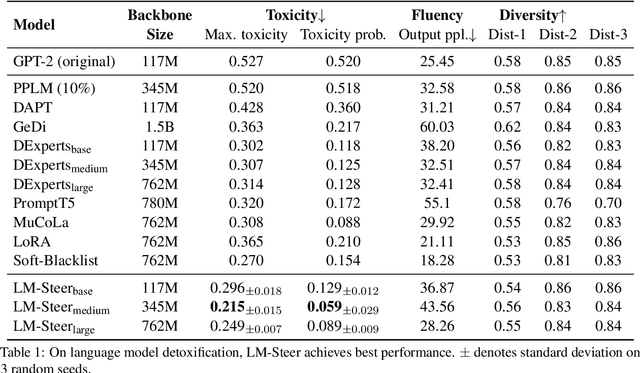


In recent years, large language models (LMs) have achieved remarkable progress across various natural language processing tasks. As pre-training and fine-tuning are costly and might negatively impact model performance, it is desired to efficiently adapt an existing model to different conditions such as styles, sentiments or narratives, when facing different audiences or scenarios. However, efficient adaptation of a language model to diverse conditions remains an open challenge. This work is inspired by the observation that text conditions are often associated with selection of certain words in a context. Therefore we introduce LM-Switch, a theoretically grounded, lightweight and simple method for generative language model conditioning. We begin by investigating the effect of conditions in Hidden Markov Models (HMMs), and establish a theoretical connection with language model. Our finding suggests that condition shifts in HMMs are associated with linear transformations in word embeddings. LM-Switch is then designed to deploy a learnable linear factor in the word embedding space for language model conditioning. We show that LM-Switch can model diverse tasks, and achieves comparable or better performance compared with state-of-the-art baselines in LM detoxification and generation control, despite requiring no more than 1% of parameters compared with baselines and little extra time overhead compared with base LMs. It is also able to learn from as few as a few sentences or one document. Moreover, a learned LM-Switch can be transferred to other LMs of different sizes, achieving a detoxification performance similar to the best baseline. We will make our code available to the research community following publication.
ADEPT: A DEbiasing PrompT Framework
Nov 10, 2022
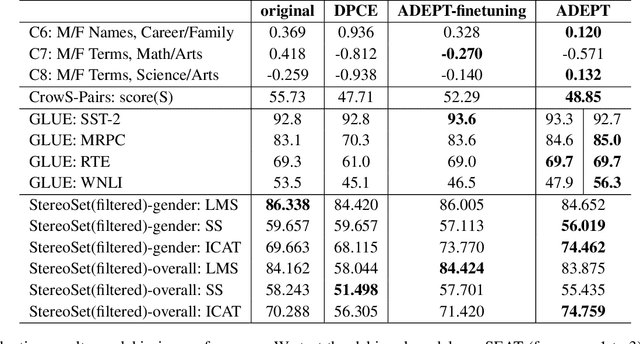
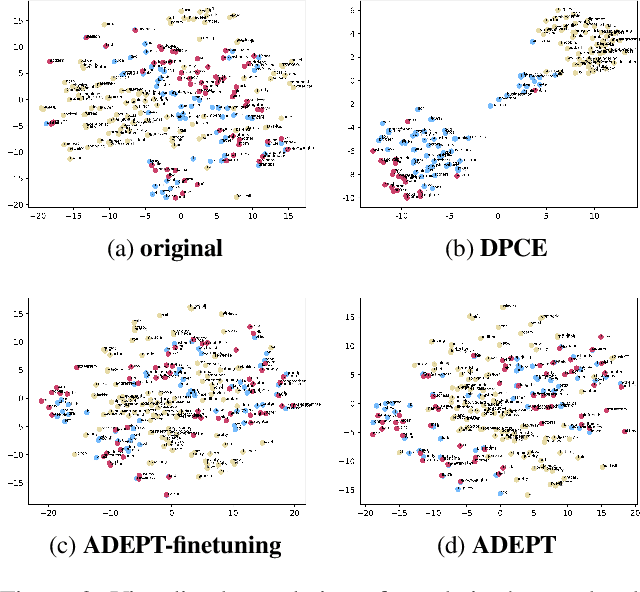

Several works have proven that finetuning is an applicable approach for debiasing contextualized word embeddings. Similarly, discrete prompts with semantic meanings have shown to be effective in debiasing tasks. With unfixed mathematical representation at the token level, continuous prompts usually surpass discrete ones at providing a pre-trained language model (PLM) with additional task-specific information. Despite this, relatively few efforts have been made to debias PLMs by prompt tuning with continuous prompts compared to its discrete counterpart. Furthermore, for most debiasing methods that alter a PLM's original parameters, a major problem is the need to not only decrease the bias in the PLM but also to ensure that the PLM does not lose its representation ability. Finetuning methods typically have a hard time maintaining this balance, as they tend to violently remove meanings of attribute words. In this paper, we propose ADEPT, a method to debias PLMs using prompt tuning while maintaining the delicate balance between removing biases and ensuring representation ability. To achieve this, we propose a new training criterion inspired by manifold learning and equip it with an explicit debiasing term to optimize prompt tuning. In addition, we conduct several experiments with regard to the reliability, quality, and quantity of a previously proposed attribute training corpus in order to obtain a clearer prototype of a certain attribute, which indicates the attribute's position and relative distances to other words on the manifold. We evaluate ADEPT on several widely acknowledged debiasing benchmarks and downstream tasks, and find that it achieves competitive results while maintaining (and in some cases even improving) the PLM's representation ability. We further visualize words' correlation before and after debiasing a PLM, and give some possible explanations for the visible effects.