 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining a New NLP Playground
Oct 31, 2023The recent explosion of performance of large language models (LLMs) has changed the field of Natural Language Processing (NLP) more abruptly and seismically than any other shift in the field's 80-year history. This has resulted in concerns that the field will become homogenized and resource-intensive. The new status quo has put many academic researchers, especially PhD students, at a disadvantage. This paper aims to define a new NLP playground by proposing 20+ PhD-dissertation-worthy research directions, covering theoretical analysis, new and challenging problems, learning paradigms, and interdisciplinary applications.
Logical Entity Representation in Knowledge-Graphs for Differentiable Rule Learning
May 22, 2023
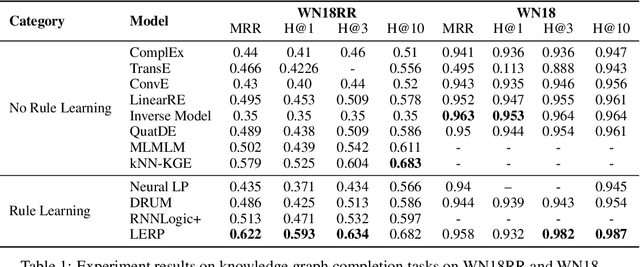
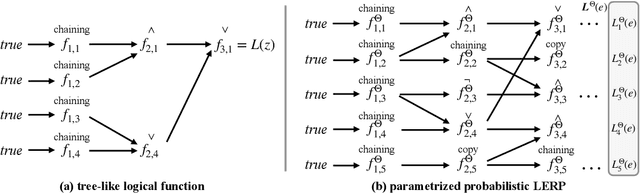
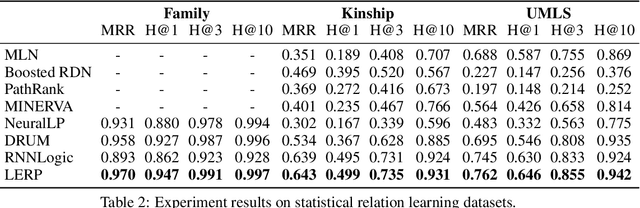
Probabilistic logical rule learning has shown great strength in logical rule mining and knowledge graph completion. It learns logical rules to predict missing edges by reasoning on existing edges in the knowledge graph. However, previous efforts have largely been limited to only modeling chain-like Horn clauses such as $R_1(x,z)\land R_2(z,y)\Rightarrow H(x,y)$. This formulation overlooks additional contextual information from neighboring sub-graphs of entity variables $x$, $y$ and $z$. Intuitively, there is a large gap here, as local sub-graphs have been found to provide important information for knowledge graph completion. Inspired by these observations, we propose Logical Entity RePresentation (LERP) to encode contextual information of entities in the knowledge graph. A LERP is designed as a vector of probabilistic logical functions on the entity's neighboring sub-graph. It is an interpretable representation while allowing for differentiable optimization. We can then incorporate LERP into probabilistic logical rule learning to learn more expressive rules. Empirical results demonstrate that with LERP, our model outperforms other rule learning methods in knowledge graph completion and is comparable or even superior to state-of-the-art black-box methods. Moreover, we find that our model can discover a more expressive family of logical rules. LERP can also be further combined with embedding learning methods like TransE to make it more interpretable.
ADEPT: A DEbiasing PrompT Framework
Nov 10, 2022
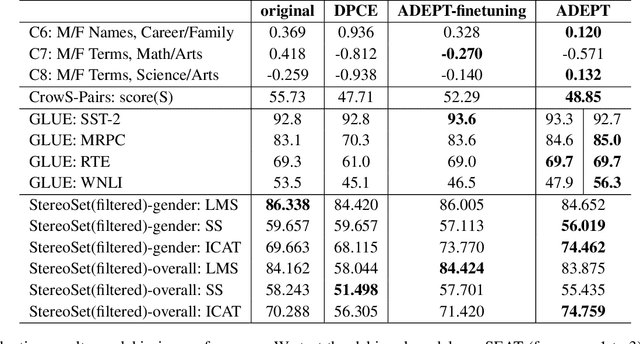
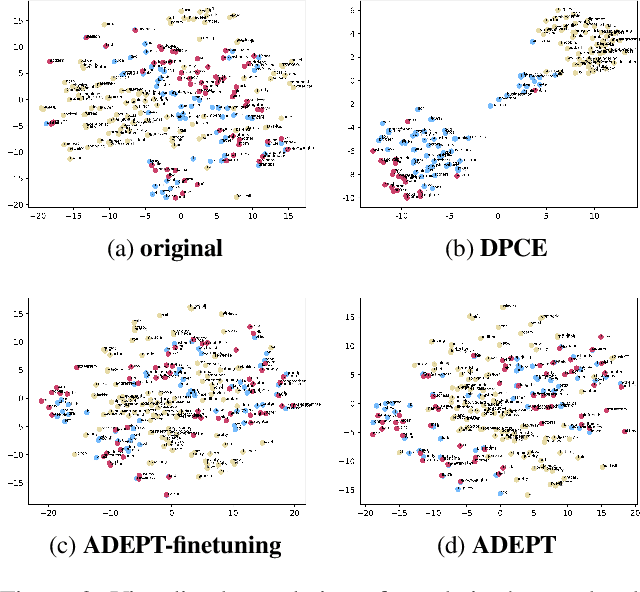

Several works have proven that finetuning is an applicable approach for debiasing contextualized word embeddings. Similarly, discrete prompts with semantic meanings have shown to be effective in debiasing tasks. With unfixed mathematical representation at the token level, continuous prompts usually surpass discrete ones at providing a pre-trained language model (PLM) with additional task-specific information. Despite this, relatively few efforts have been made to debias PLMs by prompt tuning with continuous prompts compared to its discrete counterpart. Furthermore, for most debiasing methods that alter a PLM's original parameters, a major problem is the need to not only decrease the bias in the PLM but also to ensure that the PLM does not lose its representation ability. Finetuning methods typically have a hard time maintaining this balance, as they tend to violently remove meanings of attribute words. In this paper, we propose ADEPT, a method to debias PLMs using prompt tuning while maintaining the delicate balance between removing biases and ensuring representation ability. To achieve this, we propose a new training criterion inspired by manifold learning and equip it with an explicit debiasing term to optimize prompt tuning. In addition, we conduct several experiments with regard to the reliability, quality, and quantity of a previously proposed attribute training corpus in order to obtain a clearer prototype of a certain attribute, which indicates the attribute's position and relative distances to other words on the manifold. We evaluate ADEPT on several widely acknowledged debiasing benchmarks and downstream tasks, and find that it achieves competitive results while maintaining (and in some cases even improving) the PLM's representation ability. We further visualize words' correlation before and after debiasing a PLM, and give some possible explanations for the visible effects.
Word Frequency Does Not Predict Grammatical Knowledge in Language Models
Oct 26, 2020
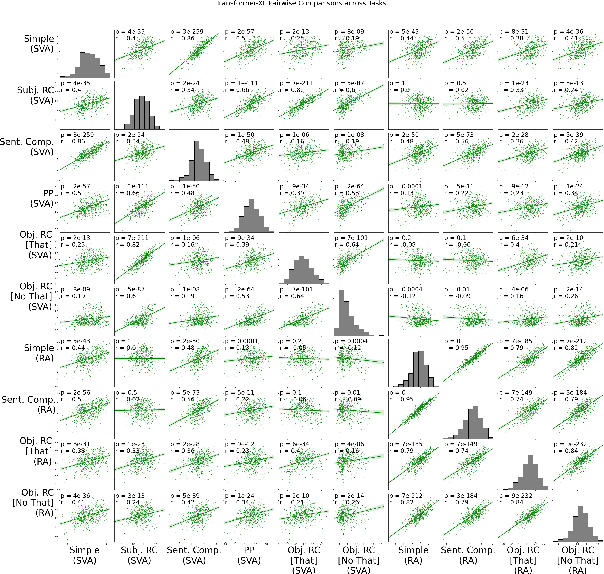
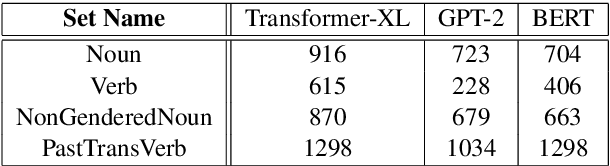
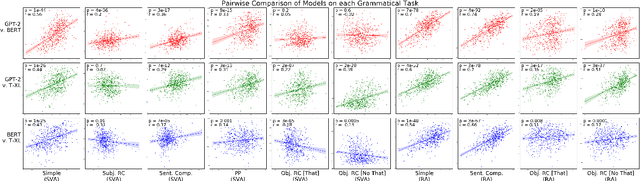
Neural language models learn, to varying degrees of accuracy, the grammatical properties of natural languages. In this work, we investigate whether there are systematic sources of variation in the language models' accuracy. Focusing on subject-verb agreement and reflexive anaphora, we find that certain nouns are systematically understood better than others, an effect which is robust across grammatical tasks and different language models. Surprisingly, we find that across four orders of magnitude, corpus frequency is unrelated to a noun's performance on grammatical tasks. Finally, we find that a novel noun's grammatical properties can be few-shot learned from various types of training data. The results present a paradox: there should be less variation in grammatical performance than is actually observed.