 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: A DEbiasing PrompT Framework
Paper and Code
Nov 10, 2022
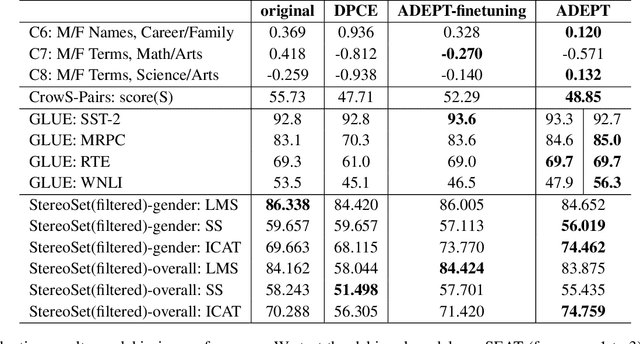
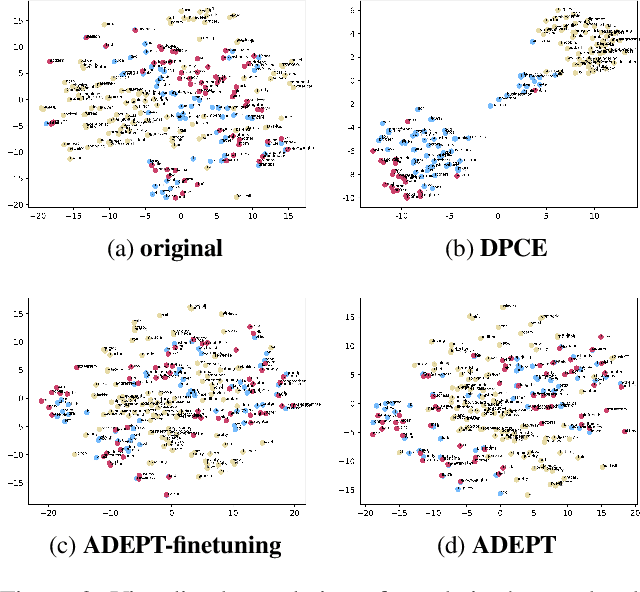

Several works have proven that finetuning is an applicable approach for debiasing contextualized word embeddings. Similarly, discrete prompts with semantic meanings have shown to be effective in debiasing tasks. With unfixed mathematical representation at the token level, continuous prompts usually surpass discrete ones at providing a pre-trained language model (PLM) with additional task-specific information. Despite this, relatively few efforts have been made to debias PLMs by prompt tuning with continuous prompts compared to its discrete counterpart. Furthermore, for most debiasing methods that alter a PLM's original parameters, a major problem is the need to not only decrease the bias in the PLM but also to ensure that the PLM does not lose its representation ability. Finetuning methods typically have a hard time maintaining this balance, as they tend to violently remove meanings of attribute words. In this paper, we propose ADEPT, a method to debias PLMs using prompt tuning while maintaining the delicate balance between removing biases and ensuring representation ability. To achieve this, we propose a new training criterion inspired by manifold learning and equip it with an explicit debiasing term to optimize prompt tuning. In addition, we conduct several experiments with regard to the reliability, quality, and quantity of a previously proposed attribute training corpus in order to obtain a clearer prototype of a certain attribute, which indicates the attribute's position and relative distances to other words on the manifold. We evaluate ADEPT on several widely acknowledged debiasing benchmarks and downstream tasks, and find that it achieves competitive results while maintaining (and in some cases even improving) the PLM's representation ability. We further visualize words' correlation before and after debiasing a PLM, and give some possible explanations for the visible effects.