 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Frequency Does Not Predict Grammatical Knowledge in Language Models
Paper and Code

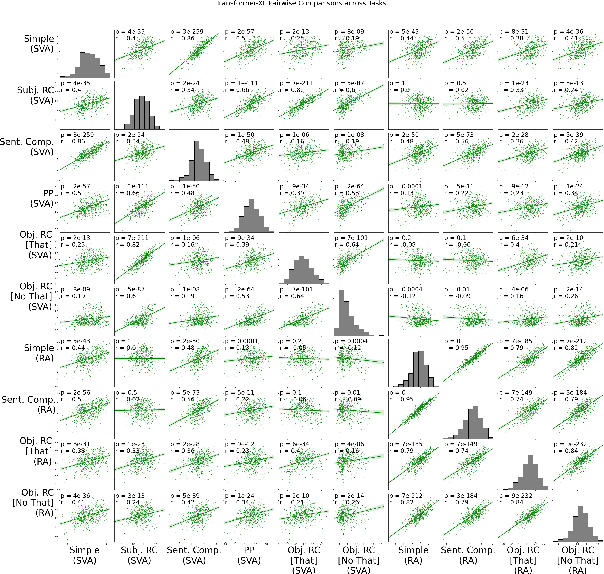
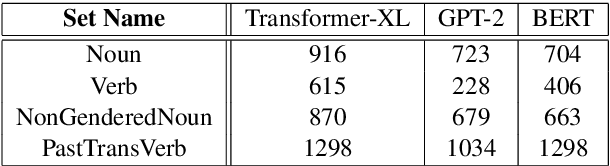
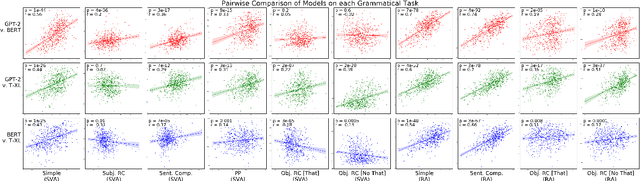
Neural language models learn, to varying degrees of accuracy, the grammatical properties of natural languages. In this work, we investigate whether there are systematic sources of variation in the language models' accuracy. Focusing on subject-verb agreement and reflexive anaphora, we find that certain nouns are systematically understood better than others, an effect which is robust across grammatical tasks and different language models. Surprisingly, we find that across four orders of magnitude, corpus frequency is unrelated to a noun's performance on grammatical tasks. Finally, we find that a novel noun's grammatical properties can be few-shot learned from various types of training data. The results present a paradox: there should be less variation in grammatical performance than is actually observed.