 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMA: Adaptive Memory via Multi-Agent Collaboration
Jan 28, 2026The rapid evolution of Large Language Model (LLM) agents has necessitated robust memory systems to support cohesive long-term interaction and complex reasoning. Benefiting from the strong capabilities of LLMs, recent research focus has shifted from simple context extension to the development of dedicated agentic memory systems. However, existing approaches typically rely on rigid retrieval granularity, accumulation-heavy maintenance strategies, and coarse-grained update mechanisms. These design choices create a persistent mismatch between stored information and task-specific reasoning demands, while leading to the unchecked accumulation of logical inconsistencies over time. To address these challenges, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), a novel framework that leverages coordinated agents to manage memory across multiple granularities. AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity. Specifically, the Constructor and Retriever jointly enable multi-granularity memory construction and adaptive query routing. The Judge verifies the relevance and consistency of retrieved content, triggering iterative retrieval when evidence is insufficient or invoking the Refresher upon detecting logical conflicts. The Refresher then enforces memory consistency by performing targeted updates or removing outdated entries. Extensive experiments on challenging long-context benchmarks show that AMA significantly outperforms state-of-the-art baselines while reducing token consumption by approximately 80% compared to full-context methods, demonstrating its effectiveness in maintaining retrieval precision and long-term memory consistency.
Unveiling Modality Bias: Automated Sample-Specific Analysis for Multimodal Misinformation Benchmarks
Nov 08, 2025Numerous multimodal misinformation benchmarks exhibit bias toward specific modalities, allowing detectors to make predictions based solely on one modality. While previous research has quantified bias at the dataset level or manually identified spurious correlations between modalities and labels, these approaches lack meaningful insights at the sample level and struggle to scale to the vast amount of online information. In this paper, we investigate the design for automated recognition of modality bias at the sample level. Specifically, we propose three bias quantification methods based on theories/views of different levels of granularity: 1) a coarse-grained evaluation of modality benefit; 2) a medium-grained quantification of information flow; and 3) a fine-grained causality analysis. To verify the effectiveness, we conduct a human evaluation on two popular benchmarks. Experimental results reveal three interesting findings that provide potential direction toward future research: 1)~Ensembling multiple views is crucial for reliable automated analysis; 2)~Automated analysis is prone to detector-induced fluctuations; and 3)~Different views produce a higher agreement on modality-balanced samples but diverge on biased ones.
Task-Adaptive Parameter-Efficient Fine-Tuning for Weather Foundation Models
Sep 26, 2025While recent advances in machine learning have equipped Weather Foundation Models (WFMs) with substantial generalization capabilities across diverse downstream tasks, the escalating computational requirements associated with their expanding scale increasingly hinder practical deployment. Current Parameter-Efficient Fine-Tuning (PEFT) methods, designed for vision or language tasks, fail to address the unique challenges of weather downstream tasks, such as variable heterogeneity, resolution diversity, and spatiotemporal coverage variations, leading to suboptimal performance when applied to WFMs. To bridge this gap, we introduce WeatherPEFT, a novel PEFT framework for WFMs incorporating two synergistic innovations. First, during the forward pass, Task-Adaptive Dynamic Prompting (TADP) dynamically injects the embedding weights within the encoder to the input tokens of the pre-trained backbone via internal and external pattern extraction, enabling context-aware feature recalibration for specific downstream tasks. Furthermore, during backpropagation, Stochastic Fisher-Guided Adaptive Selection (SFAS) not only leverages Fisher information to identify and update the most task-critical parameters, thereby preserving invariant pre-trained knowledge, but also introduces randomness to stabilize the selection. We demonstrate the effectiveness and efficiency of WeatherPEFT on three downstream tasks, where existing PEFT methods show significant gaps versus Full-Tuning, and WeatherPEFT achieves performance parity with Full-Tuning using fewer trainable parameters. The code of this work will be released.
Self-Correction is More than Refinement: A Learning Framework for Visual and Language Reasoning Tasks
Oct 05, 2024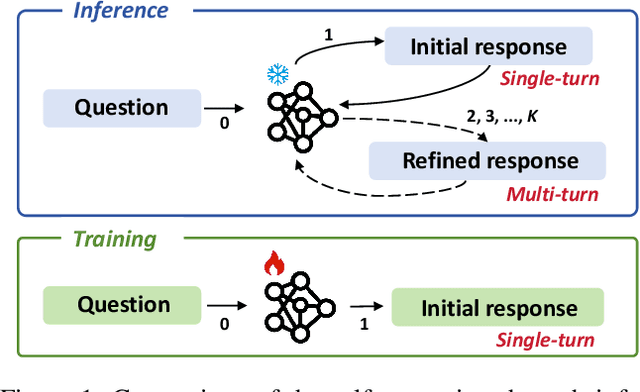
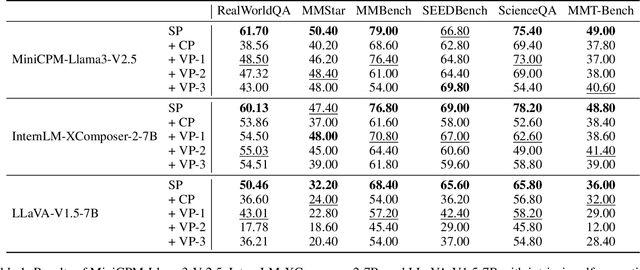
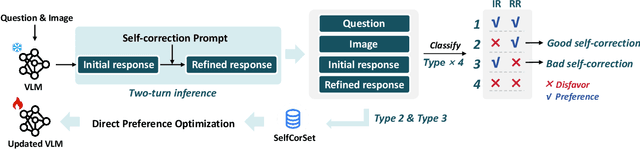
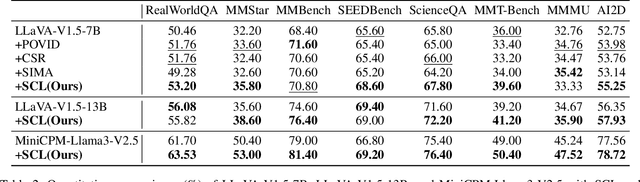
While Vision-Language Models (VLMs) have shown remarkable abilities in visual and language reasoning tasks, they invariably generate flawed responses. Self-correction that instructs models to refine their outputs presents a promising solution to this issue. Previous studies have mainly concentrated on Large Language Models (LLMs), while the self-correction abilities of VLMs, particularly concerning both visual and linguistic information, remain largely unexamined. This study investigates the self-correction capabilities of VLMs during both inference and fine-tuning stages. We introduce a Self-Correction Learning (SCL) approach that enables VLMs to learn from their self-generated self-correction data through Direct Preference Optimization (DPO) without relying on external feedback, facilitating self-improvement. Specifically, we collect preferred and disfavored samples based on the correctness of initial and refined responses, which are obtained by two-turn self-correction with VLMs during the inference stage. Experimental results demonstrate that although VLMs struggle to self-correct effectively during iterative inference without additional fine-tuning and external feedback, they can enhance their performance and avoid previous mistakes through preference fine-tuning when their self-generated self-correction data are categorized into preferred and disfavored samples. This study emphasizes that self-correction is not merely a refinement process; rather, it should enhance the reasoning abilities of models through additional training, enabling them to generate high-quality responses directly without further refinement.