 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correction is More than Refinement: A Learning Framework for Visual and Language Reasoning Tasks
Paper and Code
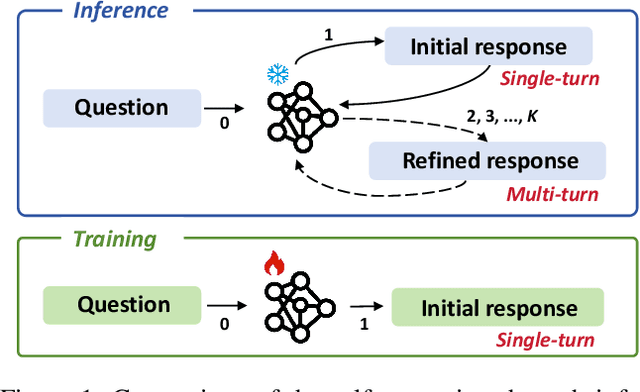
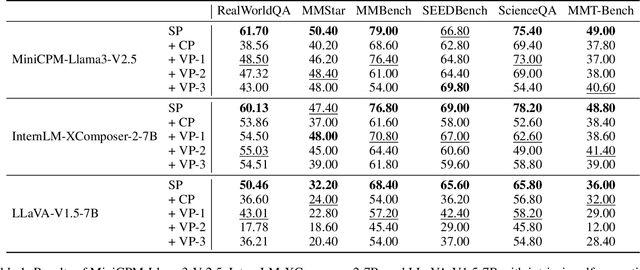
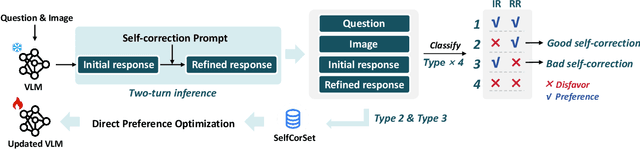
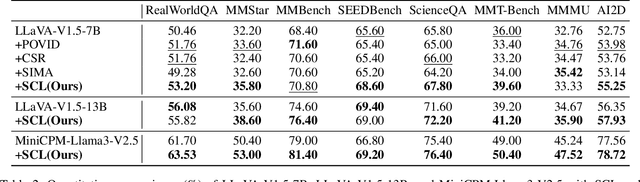
While Vision-Language Models (VLMs) have shown remarkable abilities in visual and language reasoning tasks, they invariably generate flawed responses. Self-correction that instructs models to refine their outputs presents a promising solution to this issue. Previous studies have mainly concentrated on Large Language Models (LLMs), while the self-correction abilities of VLMs, particularly concerning both visual and linguistic information, remain largely unexamined. This study investigates the self-correction capabilities of VLMs during both inference and fine-tuning stages. We introduce a Self-Correction Learning (SCL) approach that enables VLMs to learn from their self-generated self-correction data through Direct Preference Optimization (DPO) without relying on external feedback, facilitating self-improvement. Specifically, we collect preferred and disfavored samples based on the correctness of initial and refined responses, which are obtained by two-turn self-correction with VLMs during the inference stage. Experimental results demonstrate that although VLMs struggle to self-correct effectively during iterative inference without additional fine-tuning and external feedback, they can enhance their performance and avoid previous mistakes through preference fine-tuning when their self-generated self-correction data are categorized into preferred and disfavored samples. This study emphasizes that self-correction is not merely a refinement process; rather, it should enhance the reasoning abilities of models through additional training, enabling them to generate high-quality responses directly without further refinement.