 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlyCo: Foundation Model-Empowered Drones for Autonomous 3D Structure Scanning in Open-World Environments
Jan 12, 2026Autonomous 3D scanning of open-world target structures via drones remains challenging despite broad applications. Existing paradigms rely on restrictive assumptions or effortful human priors, limiting practicality, efficiency, and adaptability. Recent foundation models (FMs) offer great potential to bridge this gap. This paper investigates a critical research problem: What system architecture can effectively integrate FM knowledge for this task? We answer it with FlyCo, a principled FM-empowered perception-prediction-planning loop enabling fully autonomous, prompt-driven 3D target scanning in diverse unknown open-world environments. FlyCo directly translates low-effort human prompts (text, visual annotations) into precise adaptive scanning flights via three coordinated stages: (1) perception fuses streaming sensor data with vision-language FMs for robust target grounding and tracking; (2) prediction distills FM knowledge and combines multi-modal cues to infer the partially observed target's complete geometry; (3) planning leverages predictive foresight to generate efficient and safe paths with comprehensive target coverage. Building on this, we further design key components to boost open-world target grounding efficiency and robustness, enhance prediction quality in terms of shape accuracy, zero-shot generalization, and temporal stability, and balance long-horizon flight efficiency with real-time computability and online collision avoidance. Extensive challenging real-world and simulation experiments show FlyCo delivers precise scene understanding, high efficiency, and real-time safety, outperforming existing paradigms with lower human effort and verifying the proposed architecture's practicality. Comprehensive ablations validate each component's contribution. FlyCo also serves as a flexible, extensible blueprint, readily leveraging future FM and robotics advances. Code will be released.
Task-Adaptive Parameter-Efficient Fine-Tuning for Weather Foundation Models
Sep 26, 2025While recent advances in machine learning have equipped Weather Foundation Models (WFMs) with substantial generalization capabilities across diverse downstream tasks, the escalating computational requirements associated with their expanding scale increasingly hinder practical deployment. Current Parameter-Efficient Fine-Tuning (PEFT) methods, designed for vision or language tasks, fail to address the unique challenges of weather downstream tasks, such as variable heterogeneity, resolution diversity, and spatiotemporal coverage variations, leading to suboptimal performance when applied to WFMs. To bridge this gap, we introduce WeatherPEFT, a novel PEFT framework for WFMs incorporating two synergistic innovations. First, during the forward pass, Task-Adaptive Dynamic Prompting (TADP) dynamically injects the embedding weights within the encoder to the input tokens of the pre-trained backbone via internal and external pattern extraction, enabling context-aware feature recalibration for specific downstream tasks. Furthermore, during backpropagation, Stochastic Fisher-Guided Adaptive Selection (SFAS) not only leverages Fisher information to identify and update the most task-critical parameters, thereby preserving invariant pre-trained knowledge, but also introduces randomness to stabilize the selection. We demonstrate the effectiveness and efficiency of WeatherPEFT on three downstream tasks, where existing PEFT methods show significant gaps versus Full-Tuning, and WeatherPEFT achieves performance parity with Full-Tuning using fewer trainable parameters. The code of this work will be released.
A Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025
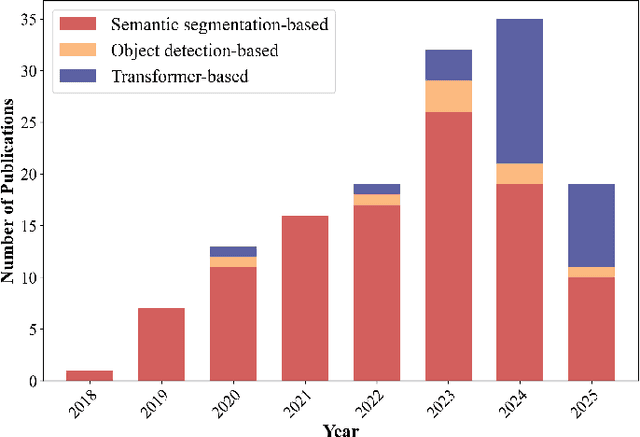


Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
May 18, 2025Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 25,026 QA pairs and 15,556 images. The pipeline begins with multi-source data preprocessing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 18 open-source LMMs and 3 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at https://rssysu.github.io/AgroMind/.
TianQuan-Climate: A Subseasonal-to-Seasonal Global Weather Model via Incorporate Climatology State
Apr 14, 2025Subseasonal forecasting serves as an important support for Sustainable Development Goals (SDGs), such as climate challenges, agricultural yield and sustainable energy production. However, subseasonal forecasting is a complex task in meteorology due to dissipating initial conditions and delayed external forces. Although AI models are increasingly pushing the boundaries of this forecasting limit, they face two major challenges: error accumulation and Smoothness. To address these two challenges, we propose Climate Furnace Subseasonal-to-Seasonal (TianQuan-Climate), a novel machine learning model designed to provide global daily mean forecasts up to 45 days, covering five upper-air atmospheric variables at 13 pressure levels and two surface variables. Our proposed TianQuan-Climate has two advantages: 1) it utilizes a multi-model prediction strategy to reduce system error impacts in long-term subseasonal forecasts; 2) it incorporates a Content Fusion Module for climatological integration and extends ViT with uncertainty blocks (UD-ViT) to improve generalization by learning from uncertainty. We demonstrate the effectiveness of TianQuan-Climate on benchmarks for weather forecasting and climate projections within the 15 to 45-day range, where TianQuan-Climate outperforms existing numerical and AI methods.
Low Saturation Confidence Distribution-based Test-Time Adaptation for Cross-Domain Remote Sensing Image Classification
Aug 29, 2024Although the Unsupervised Domain Adaptation (UDA) method has improved the effect of remote sensing image classification tasks, most of them are still limited by access to the source domain (SD) data. Designs such as Source-free Domain Adaptation (SFDA) solve the challenge of a lack of SD data, however, they still rely on a large amount of target domain data and thus cannot achieve fast adaptations, which seriously hinders their further application in broader scenarios. The real-world applications of cross-domain remote sensing image classification require a balance of speed and accuracy at the same time. Therefore, we propose a novel and comprehensive test time adaptation (TTA) method -- Low Saturation Confidence Distribution Test Time Adaptation (LSCD-TTA), which is the first attempt to solve such scenarios through the idea of TTA. LSCD-TTA specifically considers the distribution characteristics of remote sensing images, including three main parts that concentrate on different optimization directions: First, low saturation distribution (LSD) considers the dominance of low-confidence samples during the later TTA stage. Second, weak-category cross-entropy (WCCE) increases the weight of categories that are more difficult to classify with less prior knowledge. Finally, diverse categories confidence (DIV) comprehensively considers the category diversity to alleviate the deviation of the sample distribution. By weighting the abovementioned three modules, the model can widely, quickly and accurately adapt to the target domain without much prior target distributions, repeated data access, and manual annotation. We evaluate LSCD-TTA on three remote-sensing image datasets. The experimental results show that LSCD-TTA achieves a significant gain of 4.96%-10.51% with Resnet-50 and 5.33%-12.49% with Resnet-101 in average accuracy compared to other state-of-the-art DA and TTA methods.
Evidential Graph Contrastive Alignment for Source-Free Blending-Target Domain Adaptation
Aug 14, 2024In this paper, we firstly tackle a more realistic Domain Adaptation (DA) setting: Source-Free Blending-Target Domain Adaptation (SF-BTDA), where we can not access to source domain data while facing mixed multiple target domains without any domain labels in prior. Compared to existing DA scenarios, SF-BTDA generally faces the co-existence of different label shifts in different targets, along with noisy target pseudo labels generated from the source model. In this paper, we propose a new method called Evidential Contrastive Alignment (ECA) to decouple the blending target domain and alleviate the effect from noisy target pseudo labels. First, to improve the quality of pseudo target labels, we propose a calibrated evidential learning module to iteratively improve both the accuracy and certainty of the resulting model and adaptively generate high-quality pseudo target labels. Second, we design a graph contrastive learning with the domain distance matrix and confidence-uncertainty criterion, to minimize the distribution gap of samples of a same class in the blended target domains, which alleviates the co-existence of different label shifts in blended targets. We conduct a new benchmark based on three standard DA datasets and ECA outperforms other methods with considerable gains and achieves comparable results compared with those that have domain labels or source data in prior.
Exploring Test-Time Adaptation for Object Detection in Continually Changing Environments
Jun 25, 2024For real-world applications, neural network models are commonly deployed in dynamic environments, where the distribution of the target domain undergoes temporal changes. Continual Test-Time Adaptation (CTTA) has recently emerged as a promising technique to gradually adapt a source-trained model to test data drawn from a continually changing target domain. Despite recent advancements in addressing CTTA, two critical issues remain: 1) The use of a fixed threshold for pseudo-labeling in existing methodologies leads to the generation of low-quality pseudo-labels, as model confidence varies across categories and domains; 2) While current solutions utilize stochastic parameter restoration to mitigate catastrophic forgetting, their capacity to preserve critical information is undermined by its intrinsic randomness. To tackle these challenges, we present CTAOD, aiming to enhance the performance of detection models in CTTA scenarios. Inspired by prior CTTA works for effective adaptation, CTAOD is founded on the mean-teacher framework, characterized by three core components. Firstly, the object-level contrastive learning module tailored for object detection extracts object-level features using the teacher's region of interest features and optimizes them through contrastive learning. Secondly, the dynamic threshold strategy updates the category-specific threshold based on predicted confidence scores to improve the quality of pseudo-labels. Lastly, we design a data-driven stochastic restoration mechanism to selectively reset inactive parameters using the gradients as weights for a random mask matrix, thereby ensuring the retention of essential knowledge. We demonstrate the effectiveness of our approach on four CTTA tasks for object detection, where CTAOD outperforms existing methods, especially achieving a 3.0 mAP improvement on the Cityscapes-to-Cityscapes-C CTTA task.
A$^{2}$-MAE: A spatial-temporal-spectral unified remote sensing pre-training method based on anchor-aware masked autoencoder
Jun 12, 2024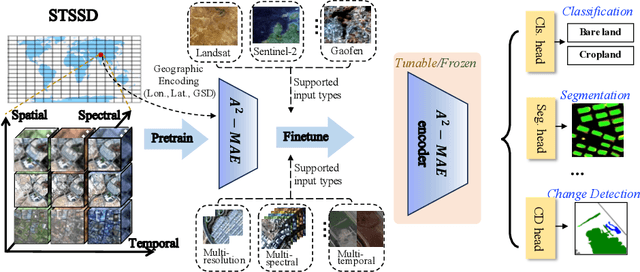
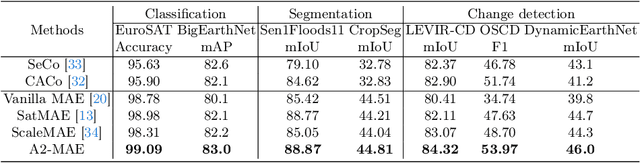
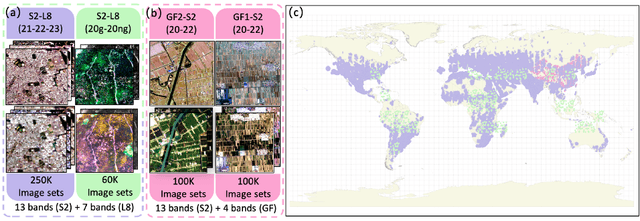

Vast amounts of remote sensing (RS) data provide Earth observations across multiple dimensions, encompassing critical spatial, temporal, and spectral information which is essential for addressing global-scale challenges such as land use monitoring, disaster prevention, and environmental change mitigation. Despite various pre-training methods tailored to the characteristics of RS data, a key limitation persists: the inability to effectively integrate spatial, temporal, and spectral information within a single unified model. To unlock the potential of RS data, we construct a Spatial-Temporal-Spectral Structured Dataset (STSSD) characterized by the incorporation of multiple RS sources, diverse coverage, unified locations within image sets, and heterogeneity within images. Building upon this structured dataset, we propose an Anchor-Aware Masked AutoEncoder method (A$^{2}$-MAE), leveraging intrinsic complementary information from the different kinds of images and geo-information to reconstruct the masked patches during the pre-training phase. A$^{2}$-MAE integrates an anchor-aware masking strategy and a geographic encoding module to comprehensively exploit the properties of RS images. Specifically, the proposed anchor-aware masking strategy dynamically adapts the masking process based on the meta-information of a pre-selected anchor image, thereby facilitating the training on images captured by diverse types of RS sources within one model. Furthermore, we propose a geographic encoding method to leverage accurate spatial patterns, enhancing the model generalization capabilities for downstream applications that are generally location-related. Extensive experiments demonstrate our method achieves comprehensive improvements across various downstream tasks compared with existing RS pre-training methods, including image classification, semantic segmentation, and change detection tasks.
FUSU: A Multi-temporal-source Land Use Change Segmentation Dataset for Fine-grained Urban Semantic Understanding
May 29, 2024Fine urban change segmentation using multi-temporal remote sensing images is essential for understanding human-environment interactions. Despite advances in remote sensing data for urban monitoring, coarse-grained classification systems and the lack of continuous temporal observations hinder the application of deep learning to urban change analysis. To address this, we introduce FUSU, a multi-source, multi-temporal change segmentation dataset for fine-grained urban semantic understanding. FUSU features the most detailed land use classification system to date, with 17 classes and 30 billion pixels of annotations. It includes bi-temporal high-resolution satellite images with 20-50 cm ground sample distance and monthly optical and radar satellite time series, covering 847 km2 across five urban areas in China. The fine-grained pixel-wise annotations and high spatial-temporal resolution data provide a robust foundation for deep learning models to understand urbanization and land use changes. To fully leverage FUSU, we propose a unified time-series architecture for both change detection and segmentation and benchmark FUSU on various methods for several tasks. Dataset and code will be available at: https://github.com/yuanshuai0914/FUSU.