 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Semantic Decoupled Modulation of Global Geospatial Embeddings for High-Resolution Remote Sensing Mapping
Apr 22, 2026Fine-grained high-resolution remote sensing mapping typically relies on localized visual features, which restricts cross-domain generalizability and often leads to fragmented predictions of large-scale land covers. While global geospatial foundation models offer powerful, generalizable representations, directly fusing their high-dimensional implicit embeddings with high-resolution visual features frequently triggers feature interference and spatial structure degradation due to a severe semantic-spatial gap. To overcome these limitations, we propose a Structure-Semantic Decoupled Modulation (SSDM) framework, which decouples global geospatial representations into two complementary cross-modal injection pathways. First, the structural prior modulation branch introduces the macroscopic receptive field priors from global representations into the self-attention modules of the high-resolution encoder. By guiding local feature extraction with holistic structural constraints, it effectively suppresses prediction fragmentation caused by high-frequency detail noise and excessive intra-class variance. Second, the global semantic injection branch explicitly aligns holistic context with the deep high-resolution feature space and directly supplements global semantics via cross-modal integration, thereby significantly enhancing the semantic consistency and category-level discrimination of complex land covers. Extensive experiments demonstrate that our method achieves state-of-the-art performance compared to existing cross-modal fusion approaches. By unleashing the potential of global embeddings, SSDM consistently improves high-resolution mapping accuracy across diverse scenarios, providing a universal and effective paradigm for integrating geospatial foundation models into high-resolution vision tasks.
RS-Prune: Training-Free Data Pruning at High Ratios for Efficient Remote Sensing Diffusion Foundation Models
Dec 29, 2025Diffusion-based remote sensing (RS) generative foundation models are cruial for downstream tasks. However, these models rely on large amounts of globally representative data, which often contain redundancy, noise, and class imbalance, reducing training efficiency and preventing convergence. Existing RS diffusion foundation models typically aggregate multiple classification datasets or apply simplistic deduplication, overlooking the distributional requirements of generation modeling and the heterogeneity of RS imagery. To address these limitations, we propose a training-free, two-stage data pruning approach that quickly select a high-quality subset under high pruning ratios, enabling a preliminary foundation model to converge rapidly and serve as a versatile backbone for generation, downstream fine-tuning, and other applications. Our method jointly considers local information content with global scene-level diversity and representativeness. First, an entropy-based criterion efficiently removes low-information samples. Next, leveraging RS scene classification datasets as reference benchmarks, we perform scene-aware clustering with stratified sampling to improve clustering effectiveness while reducing computational costs on large-scale unlabeled data. Finally, by balancing cluster-level uniformity and sample representativeness, the method enables fine-grained selection under high pruning ratios while preserving overall diversity and representativeness. Experiments show that, even after pruning 85\% of the training data, our method significantly improves convergence and generation quality. Furthermore, diffusion foundation models trained with our method consistently achieve state-of-the-art performance across downstream tasks, including super-resolution and semantic image synthesis. This data pruning paradigm offers practical guidance for developing RS generative foundation models.
Task-Oriented Data Synthesis and Control-Rectify Sampling for Remote Sensing Semantic Segmentation
Dec 18, 2025With the rapid progress of controllable generation, training data synthesis has become a promising way to expand labeled datasets and alleviate manual annotation in remote sensing (RS). However, the complexity of semantic mask control and the uncertainty of sampling quality often limit the utility of synthetic data in downstream semantic segmentation tasks. To address these challenges, we propose a task-oriented data synthesis framework (TODSynth), including a Multimodal Diffusion Transformer (MM-DiT) with unified triple attention and a plug-and-play sampling strategy guided by task feedback. Built upon the powerful DiT-based generative foundation model, we systematically evaluate different control schemes, showing that a text-image-mask joint attention scheme combined with full fine-tuning of the image and mask branches significantly enhances the effectiveness of RS semantic segmentation data synthesis, particularly in few-shot and complex-scene scenarios. Furthermore, we propose a control-rectify flow matching (CRFM) method, which dynamically adjusts sampling directions guided by semantic loss during the early high-plasticity stage, mitigating the instability of generated images and bridging the gap between synthetic data and downstream segmentation tasks. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art controllable generation methods, producing more stable and task-oriented synthetic data for RS semantic segmentation.
Evidential Graph Contrastive Alignment for Source-Free Blending-Target Domain Adaptation
Aug 14, 2024In this paper, we firstly tackle a more realistic Domain Adaptation (DA) setting: Source-Free Blending-Target Domain Adaptation (SF-BTDA), where we can not access to source domain data while facing mixed multiple target domains without any domain labels in prior. Compared to existing DA scenarios, SF-BTDA generally faces the co-existence of different label shifts in different targets, along with noisy target pseudo labels generated from the source model. In this paper, we propose a new method called Evidential Contrastive Alignment (ECA) to decouple the blending target domain and alleviate the effect from noisy target pseudo labels. First, to improve the quality of pseudo target labels, we propose a calibrated evidential learning module to iteratively improve both the accuracy and certainty of the resulting model and adaptively generate high-quality pseudo target labels. Second, we design a graph contrastive learning with the domain distance matrix and confidence-uncertainty criterion, to minimize the distribution gap of samples of a same class in the blended target domains, which alleviates the co-existence of different label shifts in blended targets. We conduct a new benchmark based on three standard DA datasets and ECA outperforms other methods with considerable gains and achieves comparable results compared with those that have domain labels or source data in prior.
Exploring Test-Time Adaptation for Object Detection in Continually Changing Environments
Jun 25, 2024For real-world applications, neural network models are commonly deployed in dynamic environments, where the distribution of the target domain undergoes temporal changes. Continual Test-Time Adaptation (CTTA) has recently emerged as a promising technique to gradually adapt a source-trained model to test data drawn from a continually changing target domain. Despite recent advancements in addressing CTTA, two critical issues remain: 1) The use of a fixed threshold for pseudo-labeling in existing methodologies leads to the generation of low-quality pseudo-labels, as model confidence varies across categories and domains; 2) While current solutions utilize stochastic parameter restoration to mitigate catastrophic forgetting, their capacity to preserve critical information is undermined by its intrinsic randomness. To tackle these challenges, we present CTAOD, aiming to enhance the performance of detection models in CTTA scenarios. Inspired by prior CTTA works for effective adaptation, CTAOD is founded on the mean-teacher framework, characterized by three core components. Firstly, the object-level contrastive learning module tailored for object detection extracts object-level features using the teacher's region of interest features and optimizes them through contrastive learning. Secondly, the dynamic threshold strategy updates the category-specific threshold based on predicted confidence scores to improve the quality of pseudo-labels. Lastly, we design a data-driven stochastic restoration mechanism to selectively reset inactive parameters using the gradients as weights for a random mask matrix, thereby ensuring the retention of essential knowledge. We demonstrate the effectiveness of our approach on four CTTA tasks for object detection, where CTAOD outperforms existing methods, especially achieving a 3.0 mAP improvement on the Cityscapes-to-Cityscapes-C CTTA task.
A$^{2}$-MAE: A spatial-temporal-spectral unified remote sensing pre-training method based on anchor-aware masked autoencoder
Jun 12, 2024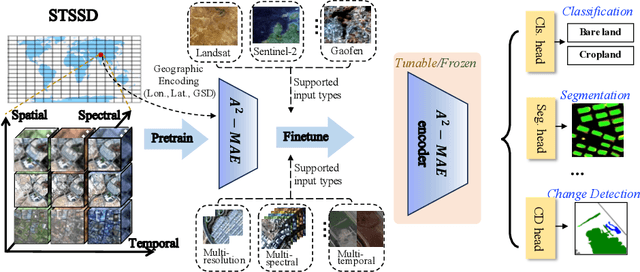
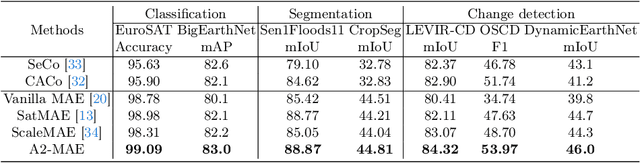
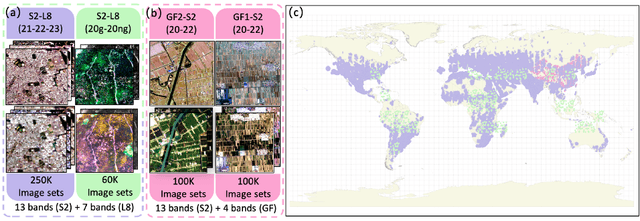

Vast amounts of remote sensing (RS) data provide Earth observations across multiple dimensions, encompassing critical spatial, temporal, and spectral information which is essential for addressing global-scale challenges such as land use monitoring, disaster prevention, and environmental change mitigation. Despite various pre-training methods tailored to the characteristics of RS data, a key limitation persists: the inability to effectively integrate spatial, temporal, and spectral information within a single unified model. To unlock the potential of RS data, we construct a Spatial-Temporal-Spectral Structured Dataset (STSSD) characterized by the incorporation of multiple RS sources, diverse coverage, unified locations within image sets, and heterogeneity within images. Building upon this structured dataset, we propose an Anchor-Aware Masked AutoEncoder method (A$^{2}$-MAE), leveraging intrinsic complementary information from the different kinds of images and geo-information to reconstruct the masked patches during the pre-training phase. A$^{2}$-MAE integrates an anchor-aware masking strategy and a geographic encoding module to comprehensively exploit the properties of RS images. Specifically, the proposed anchor-aware masking strategy dynamically adapts the masking process based on the meta-information of a pre-selected anchor image, thereby facilitating the training on images captured by diverse types of RS sources within one model. Furthermore, we propose a geographic encoding method to leverage accurate spatial patterns, enhancing the model generalization capabilities for downstream applications that are generally location-related. Extensive experiments demonstrate our method achieves comprehensive improvements across various downstream tasks compared with existing RS pre-training methods, including image classification, semantic segmentation, and change detection tasks.
Global High Categorical Resolution Land Cover Mapping via Weak Supervision
Jun 02, 2024


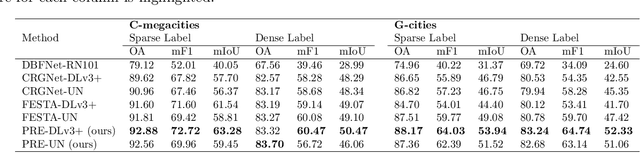
Land cover information is indispensable for advancing the United Nations' sustainable development goals, and land cover mapping under a more detailed category system would significantly contribute to economic livelihood tracking and environmental degradation measurement. However, the substantial difficulty in acquiring fine-grained training data makes the implementation of this task particularly challenging. Here, we propose to combine fully labeled source domain and weakly labeled target domain for weakly supervised domain adaptation (WSDA). This is beneficial as the utilization of sparse and coarse weak labels can considerably alleviate the labor required for precise and detailed land cover annotation. Specifically, we introduce the Prototype-based pseudo-label Rectification and Expansion (PRE) approach, which leverages the prototypes (i.e., the class-wise feature centroids) as the bridge to connect sparse labels and global feature distributions. According to the feature distances to the prototypes, the confidence of pseudo-labels predicted in the unlabeled regions of the target domain is assessed. This confidence is then utilized to guide the dynamic expansion and rectification of pseudo-labels. Based on PRE, we carry out high categorical resolution land cover mapping for 10 cities in different regions around the world, severally using PlanetScope, Gaofen-1, and Sentinel-2 satellite images. In the study areas, we achieve cross-sensor, cross-category, and cross-continent WSDA, with the overall accuracy exceeding 80%. The promising results indicate that PRE is capable of reducing the dependency of land cover classification on high-quality annotations, thereby improving label efficiency. We expect our work to enable global fine-grained land cover mapping, which in turn promote Earth observation to provide more precise and thorough information for environmental monitoring.
FUSU: A Multi-temporal-source Land Use Change Segmentation Dataset for Fine-grained Urban Semantic Understanding
May 29, 2024Fine urban change segmentation using multi-temporal remote sensing images is essential for understanding human-environment interactions. Despite advances in remote sensing data for urban monitoring, coarse-grained classification systems and the lack of continuous temporal observations hinder the application of deep learning to urban change analysis. To address this, we introduce FUSU, a multi-source, multi-temporal change segmentation dataset for fine-grained urban semantic understanding. FUSU features the most detailed land use classification system to date, with 17 classes and 30 billion pixels of annotations. It includes bi-temporal high-resolution satellite images with 20-50 cm ground sample distance and monthly optical and radar satellite time series, covering 847 km2 across five urban areas in China. The fine-grained pixel-wise annotations and high spatial-temporal resolution data provide a robust foundation for deep learning models to understand urbanization and land use changes. To fully leverage FUSU, we propose a unified time-series architecture for both change detection and segmentation and benchmark FUSU on various methods for several tasks. Dataset and code will be available at: https://github.com/yuanshuai0914/FUSU.
Decomposing weather forecasting into advection and convection with neural networks
May 10, 2024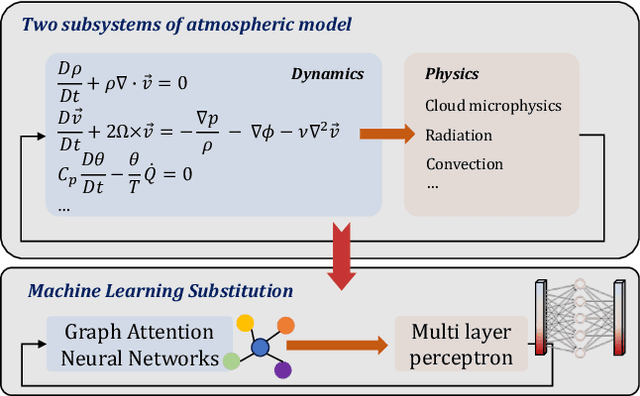


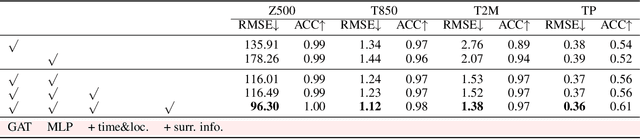
Operational weather forecasting models have advanced for decades on both the explicit numerical solvers and the empirical physical parameterization schemes. However, the involved high computational costs and uncertainties in these existing schemes are requiring potential improvements through alternative machine learning methods. Previous works use a unified model to learn the dynamics and physics of the atmospheric model. Contrarily, we propose a simple yet effective machine learning model that learns the horizontal movement in the dynamical core and vertical movement in the physical parameterization separately. By replacing the advection with a graph attention network and the convection with a multi-layer perceptron, our model provides a new and efficient perspective to simulate the transition of variables in atmospheric models. We also assess the model's performance over a 5-day iterative forecasting. Under the same input variables and training methods, our model outperforms existing data-driven methods with a significantly-reduced number of parameters with a resolution of 5.625 deg. Overall, this work aims to contribute to the ongoing efforts that leverage machine learning techniques for improving both the accuracy and efficiency of global weather forecasting.
Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model
Mar 26, 2024



Reference-based super-resolution (RefSR) has the potential to build bridges across spatial and temporal resolutions of remote sensing images. However, existing RefSR methods are limited by the faithfulness of content reconstruction and the effectiveness of texture transfer in large scaling factors. Conditional diffusion models have opened up new opportunities for generating realistic high-resolution images, but effectively utilizing reference images within these models remains an area for further exploration. Furthermore, content fidelity is difficult to guarantee in areas without relevant reference information. To solve these issues, we propose a change-aware diffusion model named Ref-Diff for RefSR, using the land cover change priors to guide the denoising process explicitly. Specifically, we inject the priors into the denoising model to improve the utilization of reference information in unchanged areas and regulate the reconstruction of semantically relevant content in changed areas. With this powerful guidance, we decouple the semantics-guided denoising and reference texture-guided denoising processes to improve the model performance. Extensive experiments demonstrate the superior effectiveness and robustness of the proposed method compared with state-of-the-art RefSR methods in both quantitative and qualitative evaluations. The code and data are available at https://github.com/dongrunmin/RefDiff.