 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgroTools: A Benchmark for Tool-Augmented Multimodal Agents in Agriculture
May 21, 2026Agricultural decision-making increasingly requires multimodal systems that can transform visual observations into reliable, executable actions. However, existing agricultural multimodal benchmarks mainly evaluate final-answer correctness and provide limited support for assessing whether models can use external tools to complete precision-sensitive workflows. In this paper, we introduce AgroTools, a benchmark for evaluating tool-augmented multimodal agents in agriculture. AgroTools contains 539 question-answer instances paired with 1,097 heterogeneous agricultural images, spanning five task families and an executable environment of 14 agricultural tools. Each query is annotated with structured tool-use traces, enabling a dual-view evaluation of both process-level execution quality and outcome-level task success. We benchmark 9 open-source and 4 closed-source multimodal large language models on AgroTools. Results show that current models remain far from reliable in agricultural tool-use settings, with clear bottlenecks in tool planning, argument generation, execution recovery, and final-answer synthesis. We hope AgroTools will support future research on multimodal agents for high-precision agricultural applications. The benchmark and evaluation are available at https://huggingface.co/datasets/AgroTools/AgroTools.
RoboSurg-VQA: A Multimodal Benchmark for Surgical Segmentation-Aware Visual Question Answering
May 21, 2026Reliable visual understanding in robot-assisted and minimally invasive surgery (RMIS/MIS) demands more than accurate masks: in clinical practice, clinicians pose language-like questions about procedural context, visibility, artefacts, and the presence of anatomical structures and surgical instruments, often under degraded views caused by occlusion, smoke, bleeding, and specular highlights. We present \textbf{RoboSurg-VQA}, a segmentation-aware visual question answering (VQA) benchmark built by repurposing public surgical segmentation datasets under a shared schema. Each frame is paired with a fixed set of clinically motivated questions spanning procedure context, anatomy (including region), imaging modality/view, surgical artefacts, image quality, and basic visibility and spatial attributes, with closed answer sets to enable consistent evaluation. To scale annotation, we generate candidate answers via constrained prompting with automatic validity and consistency checks, followed by human auditing to improve plausibility and label consistency. We report benchmark statistics, sanity baselines, and common evaluation challenges under challenging surgical conditions. The code will be available on https://github.com/ziyangwang007/Robosurg-VQA.
LPM 1.0: Video-based Character Performance Model
Apr 09, 2026Performance, the externalization of intent, emotion, and personality through visual, vocal, and temporal behavior, is what makes a character alive. Learning such performance from video is a promising alternative to traditional 3D pipelines. However, existing video models struggle to jointly achieve high expressiveness, real-time inference, and long-horizon identity stability, a tension we call the performance trilemma. Conversation is the most comprehensive performance scenario, as characters simultaneously speak, listen, react, and emote while maintaining identity over time. To address this, we present LPM 1.0 (Large Performance Model), focusing on single-person full-duplex audio-visual conversational performance. Concretely, we build a multimodal human-centric dataset through strict filtering, speaking-listening audio-video pairing, performance understanding, and identity-aware multi-reference extraction; train a 17B-parameter Diffusion Transformer (Base LPM) for highly controllable, identity-consistent performance through multimodal conditioning; and distill it into a causal streaming generator (Online LPM) for low-latency, infinite-length interaction. At inference, given a character image with identity-aware references, LPM 1.0 generates listening videos from user audio and speaking videos from synthesized audio, with text prompts for motion control, all at real-time speed with identity-stable, infinite-length generation. LPM 1.0 thus serves as a visual engine for conversational agents, live streaming characters, and game NPCs. To systematically evaluate this setting, we propose LPM-Bench, the first benchmark for interactive character performance. LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference.
AGCD: Agent-Guided Cross-Modal Decoding for Weather Forecasting
Mar 16, 2026Accurate weather forecasting is more than grid-wise regression: it must preserve coherent synoptic structures and physical consistency of meteorological fields, especially under autoregressive rollouts where small one-step errors can amplify into structural bias. Existing physics-priors approaches typically impose global, once-for-all constraints via architectures, regularization, or NWP coupling, offering limited state-adaptive and sample-specific controllability at deployment. To bridge this gap, we propose Agent-Guided Cross-modal Decoding (AGCD), a plug-and-play decoding-time prior-injection paradigm that derives state-conditioned physics-priors from the current multivariate atmosphere and injects them into forecasters in a controllable and reusable way. Specifically, We design a multi-agent meteorological narration pipeline to generate state-conditioned physics-priors, utilizing MLLMs to extract various meteorological elements effectively. To effectively apply the priors, AGCD further introduce cross-modal region interaction decoding that performs region-aware multi-scale tokenization and efficient physics-priors injection to refine visual features without changing the backbone interface. Experiments on WeatherBench demonstrate consistent gains for 6-hour forecasting across two resolutions (5.625 degree and 1.40625 degree) and diverse backbones (generic and weather-specialized), including strictly causal 48-hour autoregressive rollouts that reduce early-stage error accumulation and improve long-horizon stability.
Radiomics-Integrated Deep Learning with Hierarchical Loss for Osteosarcoma Histology Classification
Jan 14, 2026Osteosarcoma (OS) is an aggressive primary bone malignancy. Accurate histopathological assessment of viable versus non-viable tumor regions after neoadjuvant chemotherapy is critical for prognosis and treatment planning, yet manual evaluation remains labor-intensive, subjective, and prone to inter-observer variability. Recent advances in digital pathology have enabled automated necrosis quantification. Evaluating on test data, independently sampled on patient-level, revealed that the deep learning model performance dropped significantly from the tile-level generalization ability reported in previous studies. First, this work proposes the use of radiomic features as additional input in model training. We show that, despite that they are derived from the images, such a multimodal input effectively improved the classification performance, in addition to its added benefits in interpretability. Second, this work proposes to optimize two binary classification tasks with hierarchical classes (i.e. tumor-vs-non-tumor and viable-vs-non-viable), as opposed to the alternative ``flat'' three-class classification task (i.e. non-tumor, non-viable tumor, viable tumor), thereby enabling a hierarchical loss. We show that such a hierarchical loss, with trainable weightings between the two tasks, the per-class performance can be improved significantly. Using the TCIA OS Tumor Assessment dataset, we experimentally demonstrate the benefits from each of the proposed new approaches and their combination, setting a what we consider new state-of-the-art performance on this open dataset for this application. Code and trained models: https://github.com/YaxiiC/RadiomicsOS.git.
A Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025
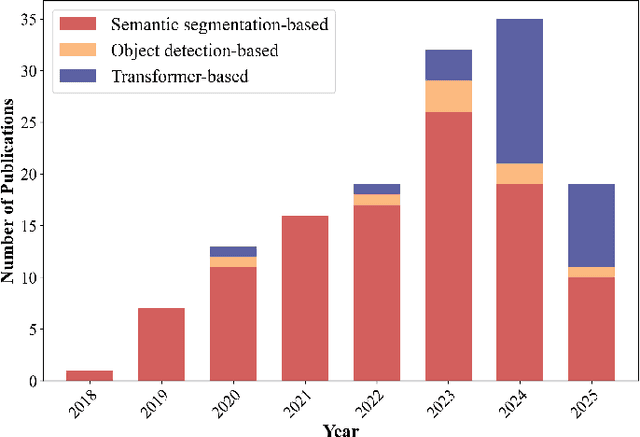


Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
OPT-Tree: Speculative Decoding with Adaptive Draft Tree Structure
Jun 25, 2024



Autoregressive language models demonstrate excellent performance in various scenarios. However, the inference efficiency is limited by its one-step-one-word generation mode, which has become a pressing problem recently as the models become increasingly larger. Speculative decoding employs a "draft and then verify" mechanism to allow multiple tokens to be generated in one step, realizing lossless acceleration. Existing methods mainly adopt fixed heuristic draft structures, which fail to adapt to different situations to maximize the acceptance length during verification. To alleviate this dilemma, we proposed OPT-Tree, an algorithm to construct adaptive and scalable draft trees. It searches the optimal tree structure that maximizes the mathematical expectation of the acceptance length in each decoding step. Experimental results reveal that OPT-Tree outperforms the existing draft structures and achieves a speed-up ratio of up to 3.2 compared with autoregressive decoding. If the draft model is powerful enough and the node budget is sufficient, it can generate more than ten tokens in a single step. Our code is available at https://github.com/Jikai0Wang/OPT-Tree.
A Survey on Visual Mamba
Apr 26, 2024State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
Joint Communication and Sensing for 6G -- A Cross-Layer Perspective
Feb 14, 2024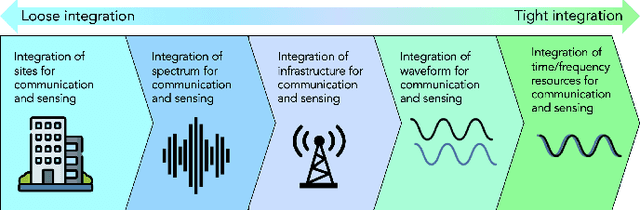
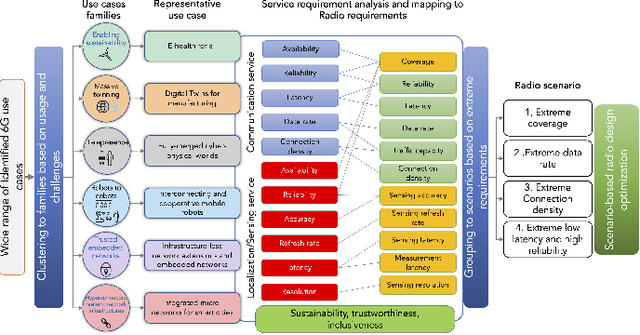
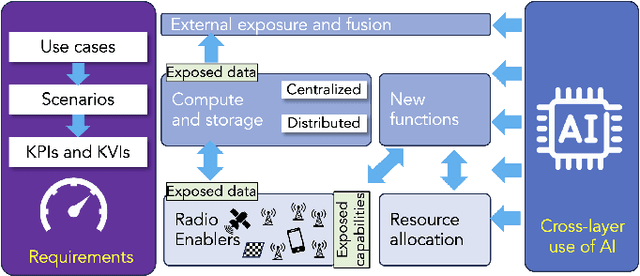
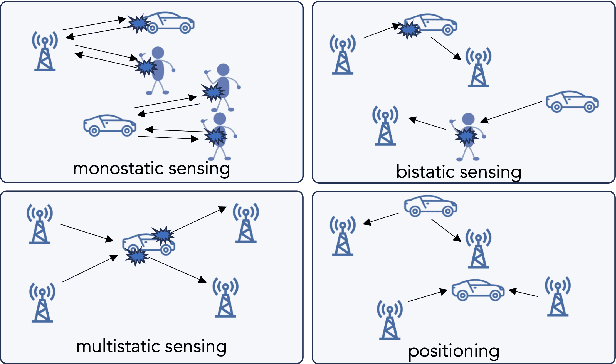
As 6G emerges, cellular systems are envisioned to integrate sensing with communication capabilities, leading to multi-faceted communication and sensing (JCAS). This paper presents a comprehensive cross-layer overview of the Hexa-X-II project's endeavors in JCAS, aligning 6G use cases with service requirements and pinpointing distinct scenarios that bridge communication and sensing. This work relates to these scenarios through the lens of the cross-layer physical and networking domains, covering models, deployments, resource allocation, storage challenges, computational constraints, interfaces, and innovative functions.
P-Mamba: Marrying Perona Malik Diffusion with Mamba for Efficient Pediatric Echocardiographic Left Ventricular Segmentation
Feb 13, 2024In pediatric cardiology, the accurate and immediate assessment of cardiac function through echocardiography is important since it can determine whether urgent intervention is required in many emergencies. However, echocardiography is characterized by ambiguity and heavy background noise interference, bringing more difficulty to accurate segmentation. Present methods lack efficiency and are also prone to mistakenly segmenting some background noise areas as the left ventricular area due to noise disturbance. To relieve the two issues, we introduce P-Mamba for efficient pediatric echocardiographic left ventricular segmentation. Specifically, we turn to the recently proposed vision mamba layers in our vision mamba encoder branch to improve the computing and memory efficiency of our model while modeling global dependencies. In the other DWT-based PMD encoder branch, we devise DWT-based Perona-Malik Diffusion (PMD) Blocks that utilize PMD for noise suppression, while simultaneously preserving the local shape cues of the left ventricle. Leveraging the strengths of both the two encoder branches, P-Mamba achieves superior accuracy and efficiency to established models, such as vision transformers with quadratic and linear computational complexity. This innovative approach promises significant advancements in pediatric cardiac imaging and beyond.