 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-fly Feature Based Speaker Adaptation for Dysarthric and Elderly Speech Recognition
Paper and Code
Apr 05, 2022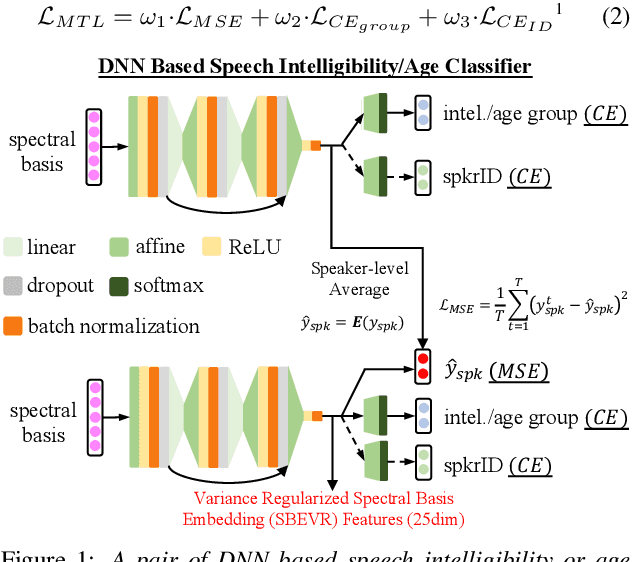
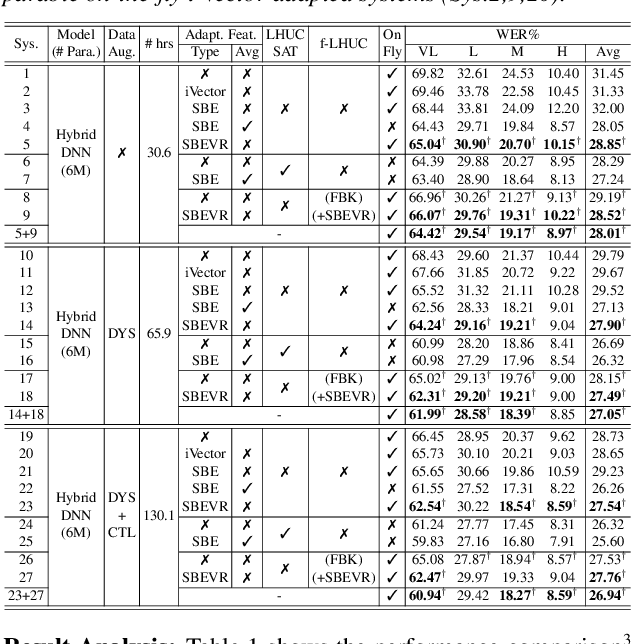
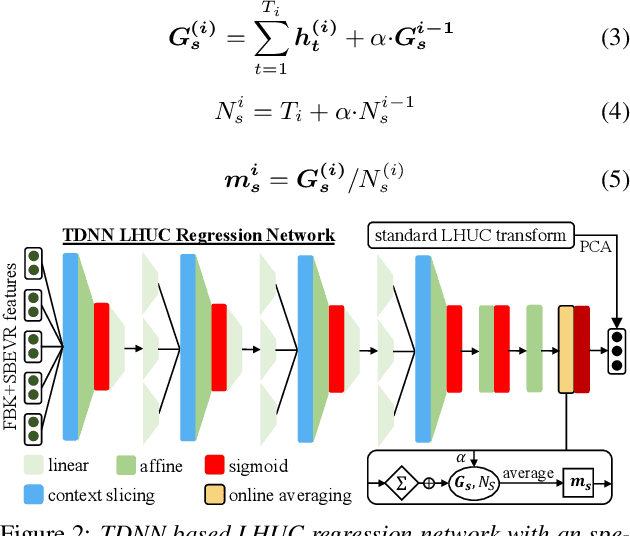
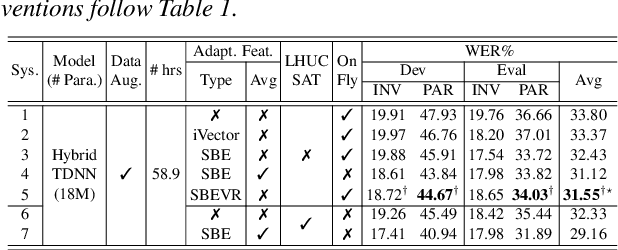
Automatic recognition of dysarthric and elderly speech highly challenging tasks to date. Speaker-level heterogeneity attributed to accent or gender commonly found in normal speech, when aggregated with age and speech impairment severity, create large diversity among speakers. Speaker adaptation techniques play a crucial role in personalization of ASR systems for such users. Their mobility issues limit the amount of speaker-level data available for model based adaptation. To this end, this paper investigates two novel forms of feature based on-the-fly rapid speaker adaptation approaches. The first is based on speaker-level variance regularized spectral basis embedding (SBEVR) features, while the other uses on-the-fly learning hidden unit contributions (LHUC) transforms conditioned on speaker-level spectral features. Experiments conducted on the UASpeech dysarthric and DimentiaBank Pitt elderly speech datasets suggest the proposed SBEVR features based adaptation statistically significantly outperform both the baseline on-the-fly i-Vector adapted hybrid TDNN/DNN systems by up to 2.48% absolute (7.92% relative) reduction in word error rate (WER), and offline batch mode model based LHUC adaptation using all speaker-level data by 0.78% absolute (2.41% relative) in WER reduction.