 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network
May 07, 2024



Automatic assessment of dysarthria remains a highly challenging task due to high variability in acoustic signals and the limited data. Currently, research on the automatic assessment of dysarthria primarily focuses on two approaches: one that utilizes expert features combined with machine learning, and the other that employs data-driven deep learning methods to extract representations. Research has demonstrated that expert features are effective in representing pathological characteristics, while deep learning methods excel at uncovering latent features. Therefore, integrating the advantages of expert features and deep learning to construct a neural network architecture based on expert knowledge may be beneficial for interpretability and assessment performance. In this context, the present paper proposes a vowel graph attention network based on audio-visual information, which effectively integrates the strengths of expert knowledges and deep learning. Firstly, various features were combined as inputs, including knowledge based acoustical features and deep learning based pre-trained representations. Secondly, the graph network structure based on vowel space theory was designed, allowing for a deep exploration of spatial correlations among vowels. Finally, visual information was incorporated into the model to further enhance its robustness and generalizability. The method exhibited superior performance in regression experiments targeting Frenchay scores compared to existing approaches.
An Audio-textual Diffusion Model For Converting Speech Signals Into Ultrasound Tongue Imaging Data
Mar 12, 2024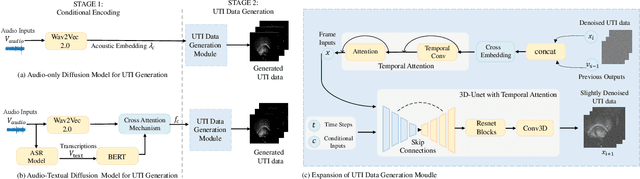
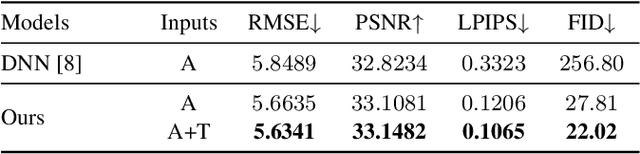

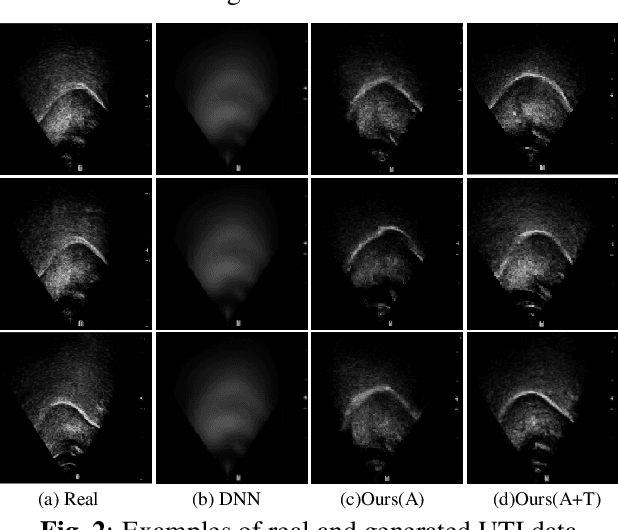
Acoustic-to-articulatory inversion (AAI) is to convert audio into articulator movements, such as ultrasound tongue imaging (UTI) data. An issue of existing AAI methods is only using the personalized acoustic information to derive the general patterns of tongue motions, and thus the quality of generated UTI data is limited. To address this issue, this paper proposes an audio-textual diffusion model for the UTI data generation task. In this model, the inherent acoustic characteristics of individuals related to the tongue motion details are encoded by using wav2vec 2.0, while the ASR transcriptions related to the universality of tongue motions are encoded by using BERT. UTI data are then generated by using a diffusion module. Experimental results showed that the proposed diffusion model could generate high-quality UTI data with clear tongue contour that is crucial for the linguistic analysis and clinical assessment. The project can be found on the website\footnote{https://yangyudong2020.github.io/wav2uti/
On-the-fly Feature Based Speaker Adaptation for Dysarthric and Elderly Speech Recognition
Apr 05, 2022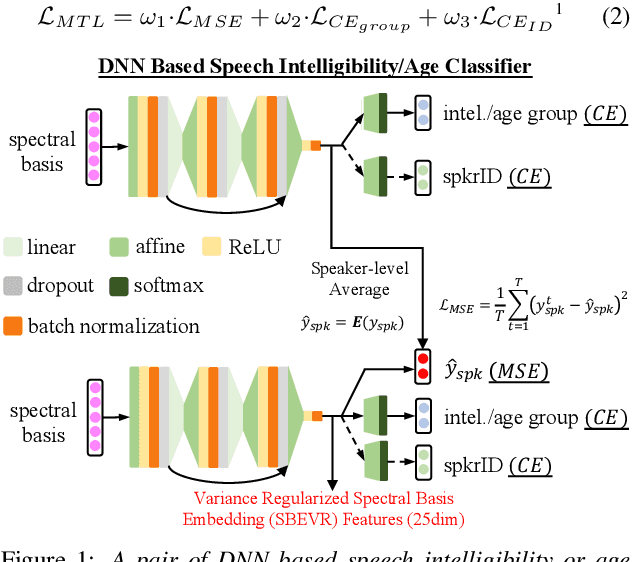
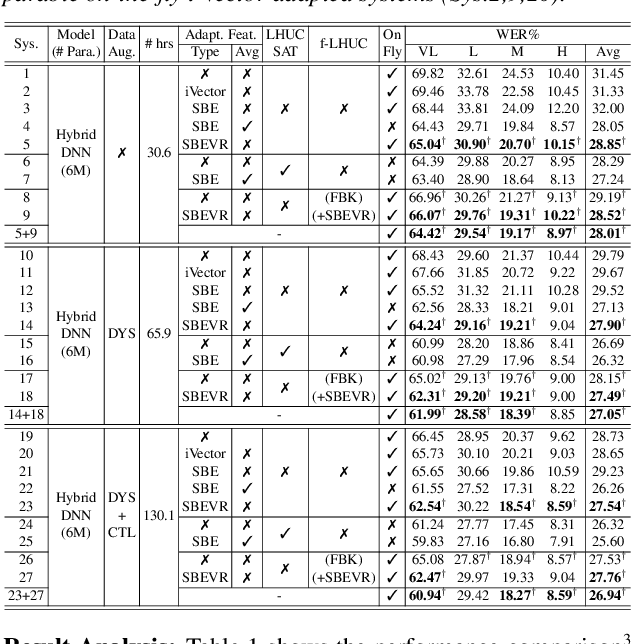
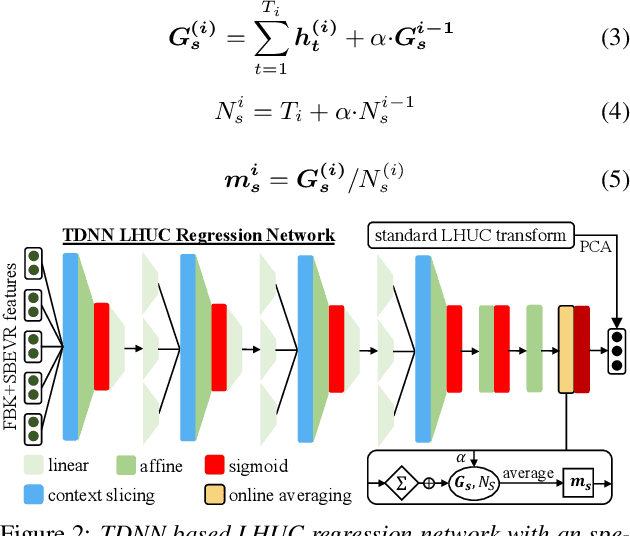
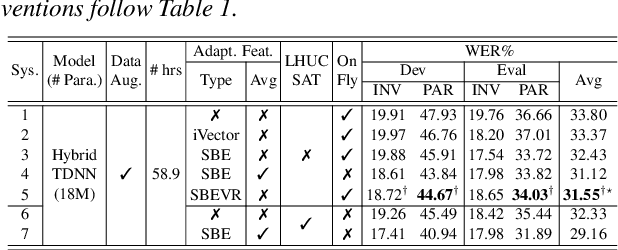
Automatic recognition of dysarthric and elderly speech highly challenging tasks to date. Speaker-level heterogeneity attributed to accent or gender commonly found in normal speech, when aggregated with age and speech impairment severity, create large diversity among speakers. Speaker adaptation techniques play a crucial role in personalization of ASR systems for such users. Their mobility issues limit the amount of speaker-level data available for model based adaptation. To this end, this paper investigates two novel forms of feature based on-the-fly rapid speaker adaptation approaches. The first is based on speaker-level variance regularized spectral basis embedding (SBEVR) features, while the other uses on-the-fly learning hidden unit contributions (LHUC) transforms conditioned on speaker-level spectral features. Experiments conducted on the UASpeech dysarthric and DimentiaBank Pitt elderly speech datasets suggest the proposed SBEVR features based adaptation statistically significantly outperform both the baseline on-the-fly i-Vector adapted hybrid TDNN/DNN systems by up to 2.48% absolute (7.92% relative) reduction in word error rate (WER), and offline batch mode model based LHUC adaptation using all speaker-level data by 0.78% absolute (2.41% relative) in WER reduction.