 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Reactive Safety: Risk-Aware LLM Alignment via Long-Horizon Simulation
Jun 26, 2025Given the growing influence of language model-based agents on high-stakes societal decisions, from public policy to healthcare, ensuring their beneficial impact requires understanding the far-reaching implications of their suggestions. We propose a proof-of-concept framework that projects how model-generated advice could propagate through societal systems on a macroscopic scale over time, enabling more robust alignment. To assess the long-term safety awareness of language models, we also introduce a dataset of 100 indirect harm scenarios, testing models' ability to foresee adverse, non-obvious outcomes from seemingly harmless user prompts. Our approach achieves not only over 20% improvement on the new dataset but also an average win rate exceeding 70% against strong baselines on existing safety benchmarks (AdvBench, SafeRLHF, WildGuardMix), suggesting a promising direction for safer agents.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
Persona-DB: Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement
Feb 16, 2024The increasing demand for personalized interactions with large language models (LLMs) calls for the development of methodologies capable of accurately and efficiently identifying user opinions and preferences. Retrieval augmentation emerges as an effective strategy, as it can accommodate a vast number of users without the costs from fine-tuning. Existing research, however, has largely focused on enhancing the retrieval stage and devoted limited exploration toward optimizing the representation of the database, a crucial aspect for tasks such as personalization. In this work, we examine the problem from a novel angle, focusing on how data can be better represented for more efficient retrieval in the context of LLM customization. To tackle this challenge, we introduce Persona-DB, a simple yet effective framework consisting of a hierarchical construction process to improve generalization across task contexts and collaborative refinement to effectively bridge knowledge gaps among users. In the task of response forecasting, Persona-DB demonstrates superior efficiency in maintaining accuracy with a significantly reduced retrieval size, a critical advantage in scenarios with extensive histories or limited context windows. Our experiments also indicate a marked improvement of over 15% under cold-start scenarios, when users have extremely sparse data. Furthermore, our analysis reveals the increasing importance of collaborative knowledge as the retrieval capacity expands.
Massively Multi-Cultural Knowledge Acquisition & LM Benchmarking
Feb 14, 2024



Pretrained large language models have revolutionized many applications but still face challenges related to cultural bias and a lack of cultural commonsense knowledge crucial for guiding cross-culture communication and interactions. Recognizing the shortcomings of existing methods in capturing the diverse and rich cultures across the world, this paper introduces a novel approach for massively multicultural knowledge acquisition. Specifically, our method strategically navigates from densely informative Wikipedia documents on cultural topics to an extensive network of linked pages. Leveraging this valuable source of data collection, we construct the CultureAtlas dataset, which covers a wide range of sub-country level geographical regions and ethnolinguistic groups, with data cleaning and preprocessing to ensure textual assertion sentence self-containment, as well as fine-grained cultural profile information extraction. Our dataset not only facilitates the evaluation of language model performance in culturally diverse contexts but also serves as a foundational tool for the development of culturally sensitive and aware language models. Our work marks an important step towards deeper understanding and bridging the gaps of cultural disparities in AI, to promote a more inclusive and balanced representation of global cultures in the digital domain.
Cascade Speculative Drafting for Even Faster LLM Inference
Dec 21, 2023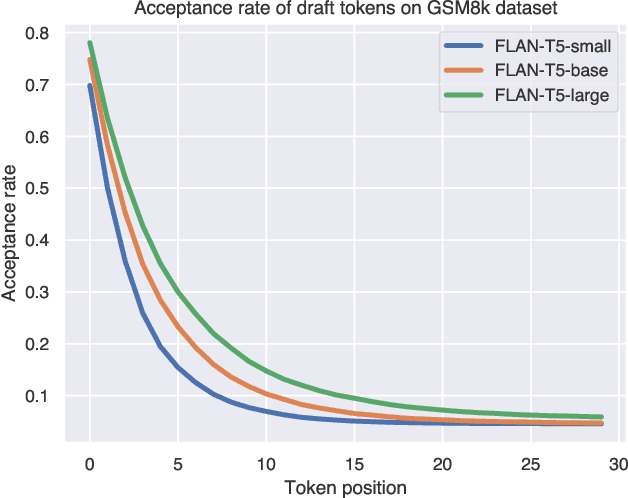

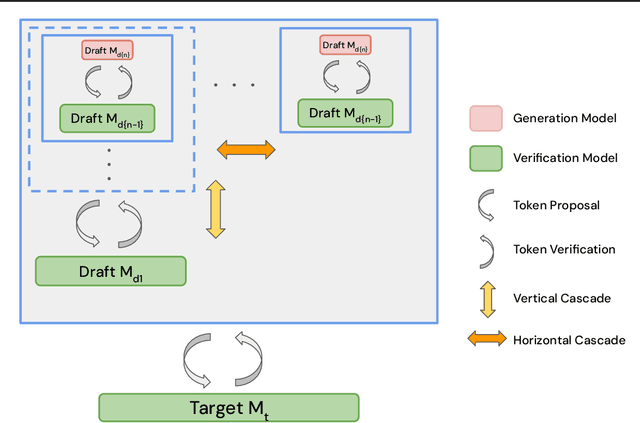
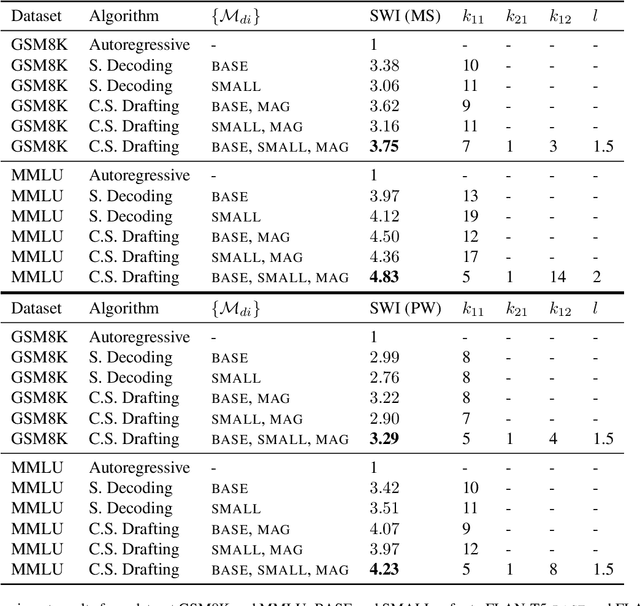
Speculative decoding enhances the efficiency of large language models (LLMs) by leveraging a draft model to draft for a larger target model to review. However, drafting in speculative decoding involves slow autoregressive generation and generating tokens of different importance with the same time allocation. These two inefficiencies lead to its suboptimal performance. To address this issue, we introduce Cascade Speculative Drafting (CS. Drafting), a novel approach that employs two types of cascades. The Vertical Cascade eliminates autoregressive generation from neural models. The Horizontal Cascade constitutes efficient time allocation in drafting with its optimality supported by our theoretical analysis. Combining both cascades, our CS. Drafting algorithm has achieved up to 72 percent additional speedup over speculative decoding in our experiments while keeping the same output distribution.
Decoding the Silent Majority: Inducing Belief Augmented Social Graph with Large Language Model for Response Forecasting
Oct 20, 2023



Automatic response forecasting for news media plays a crucial role in enabling content producers to efficiently predict the impact of news releases and prevent unexpected negative outcomes such as social conflict and moral injury. To effectively forecast responses, it is essential to develop measures that leverage the social dynamics and contextual information surrounding individuals, especially in cases where explicit profiles or historical actions of the users are limited (referred to as lurkers). As shown in a previous study, 97% of all tweets are produced by only the most active 25% of users. However, existing approaches have limited exploration of how to best process and utilize these important features. To address this gap, we propose a novel framework, named SocialSense, that leverages a large language model to induce a belief-centered graph on top of an existent social network, along with graph-based propagation to capture social dynamics. We hypothesize that the induced graph that bridges the gap between distant users who share similar beliefs allows the model to effectively capture the response patterns. Our method surpasses existing state-of-the-art in experimental evaluations for both zero-shot and supervised settings, demonstrating its effectiveness in response forecasting. Moreover, the analysis reveals the framework's capability to effectively handle unseen user and lurker scenarios, further highlighting its robustness and practical applicability.
Measuring the Effect of Influential Messages on Varying Personas
May 25, 2023Predicting how a user responds to news events enables important applications such as allowing intelligent agents or content producers to estimate the effect on different communities and revise unreleased messages to prevent unexpected bad outcomes such as social conflict and moral injury. We present a new task, Response Forecasting on Personas for News Media, to estimate the response a persona (characterizing an individual or a group) might have upon seeing a news message. Compared to the previous efforts which only predict generic comments to news, the proposed task not only introduces personalization in the modeling but also predicts the sentiment polarity and intensity of each response. This enables more accurate and comprehensive inference on the mental state of the persona. Meanwhile, the generated sentiment dimensions make the evaluation and application more reliable. We create the first benchmark dataset, which consists of 13,357 responses to 3,847 news headlines from Twitter. We further evaluate the SOTA neural language models with our dataset. The empirical results suggest that the included persona attributes are helpful for the performance of all response dimensions. Our analysis shows that the best-performing models are capable of predicting responses that are consistent with the personas, and as a byproduct, the task formulation also enables many interesting applications in the analysis of social network groups and their opinions, such as the discovery of extreme opinion groups.
LM-Switch: Lightweight Language Model Conditioning in Word Embedding Space
May 22, 2023
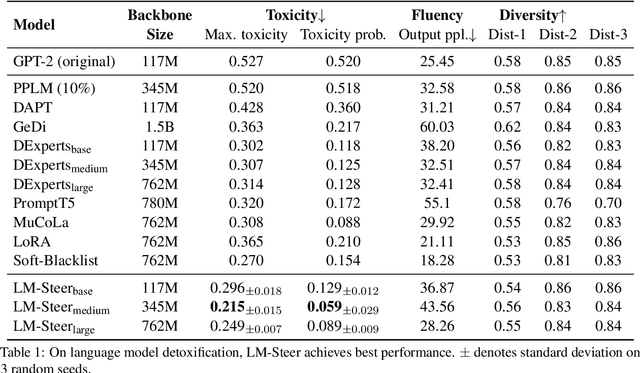


In recent years, large language models (LMs) have achieved remarkable progress across various natural language processing tasks. As pre-training and fine-tuning are costly and might negatively impact model performance, it is desired to efficiently adapt an existing model to different conditions such as styles, sentiments or narratives, when facing different audiences or scenarios. However, efficient adaptation of a language model to diverse conditions remains an open challenge. This work is inspired by the observation that text conditions are often associated with selection of certain words in a context. Therefore we introduce LM-Switch, a theoretically grounded, lightweight and simple method for generative language model conditioning. We begin by investigating the effect of conditions in Hidden Markov Models (HMMs), and establish a theoretical connection with language model. Our finding suggests that condition shifts in HMMs are associated with linear transformations in word embeddings. LM-Switch is then designed to deploy a learnable linear factor in the word embedding space for language model conditioning. We show that LM-Switch can model diverse tasks, and achieves comparable or better performance compared with state-of-the-art baselines in LM detoxification and generation control, despite requiring no more than 1% of parameters compared with baselines and little extra time overhead compared with base LMs. It is also able to learn from as few as a few sentences or one document. Moreover, a learned LM-Switch can be transferred to other LMs of different sizes, achieving a detoxification performance similar to the best baseline. We will make our code available to the research community following publication.
Fine-Grained Chemical Entity Typing with Multimodal Knowledge Representation
Aug 29, 2021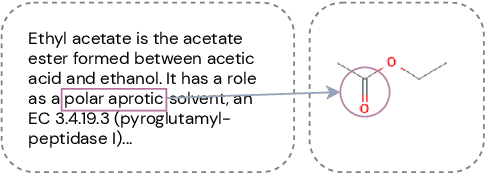
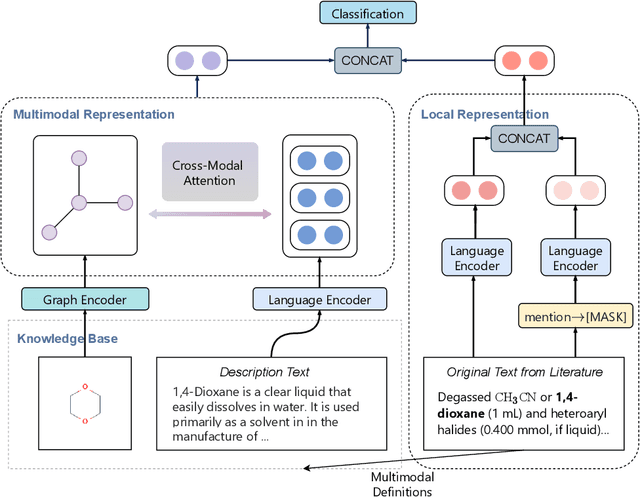
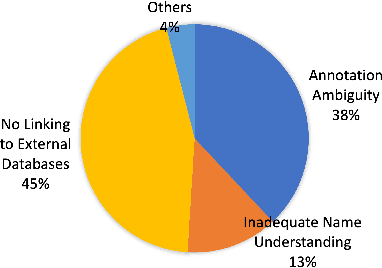
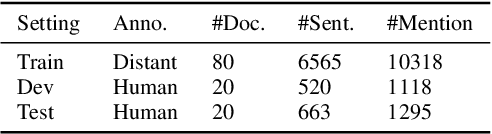
Automated knowledge discovery from trending chemical literature is essential for more efficient biomedical research. How to extract detailed knowledge about chemical reactions from the core chemistry literature is a new emerging challenge that has not been well studied. In this paper, we study the new problem of fine-grained chemical entity typing, which poses interesting new challenges especially because of the complex name mentions frequently occurring in chemistry literature and graphic representation of entities. We introduce a new benchmark data set (CHEMET) to facilitate the study of the new task and propose a novel multi-modal representation learning framework to solve the problem of fine-grained chemical entity typing by leveraging external resources with chemical structures and using cross-modal attention to learn effective representation of text in the chemistry domain. Experiment results show that the proposed framework outperforms multiple state-of-the-art methods.
HySPA: Hybrid Span Generation for Scalable Text-to-Graph Extraction
Jun 30, 2021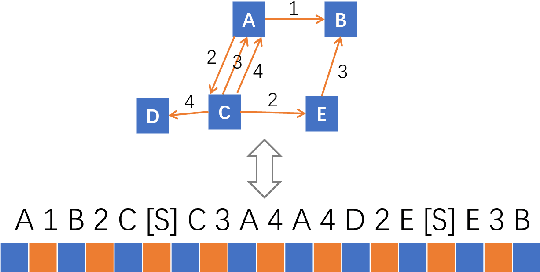

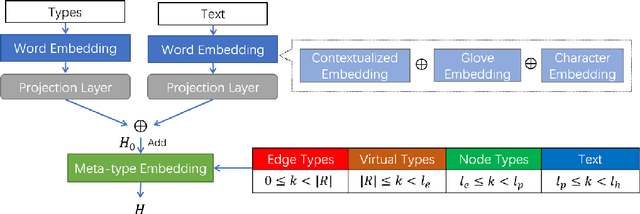
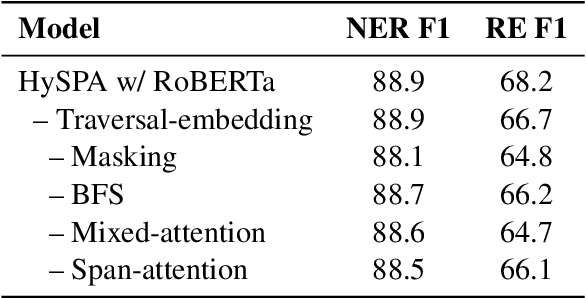
Text-to-Graph extraction aims to automatically extract information graphs consisting of mentions and types from natural language texts. Existing approaches, such as table filling and pairwise scoring, have shown impressive performance on various information extraction tasks, but they are difficult to scale to datasets with longer input texts because of their second-order space/time complexities with respect to the input length. In this work, we propose a Hybrid Span Generator (HySPA) that invertibly maps the information graph to an alternating sequence of nodes and edge types, and directly generates such sequences via a hybrid span decoder which can decode both the spans and the types recurrently in linear time and space complexities. Extensive experiments on the ACE05 dataset show that our approach also significantly outperforms state-of-the-art on the joint entity and relation extraction task.