 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Speculative Drafting for Even Faster LLM Inference
Paper and Code
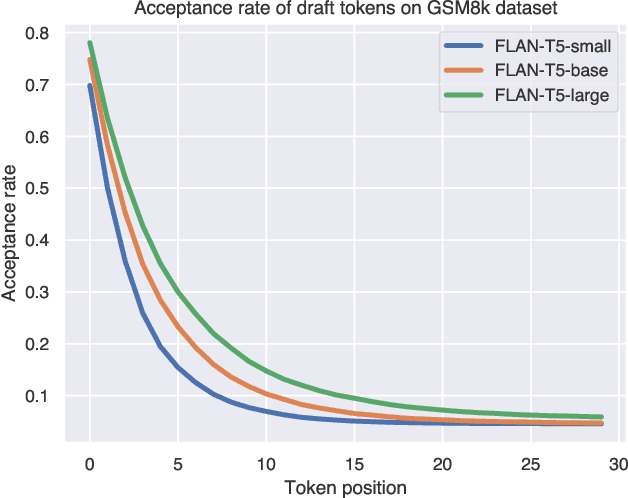

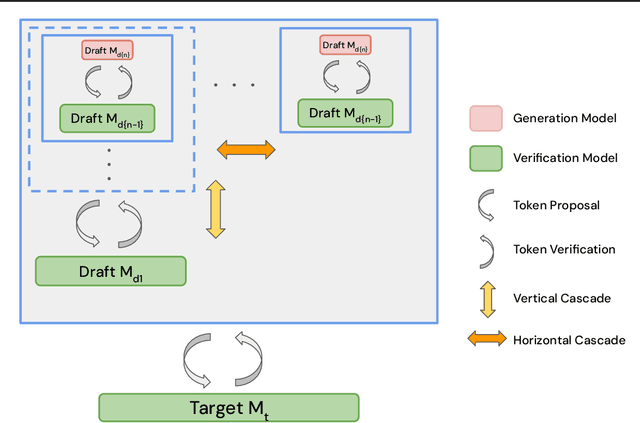
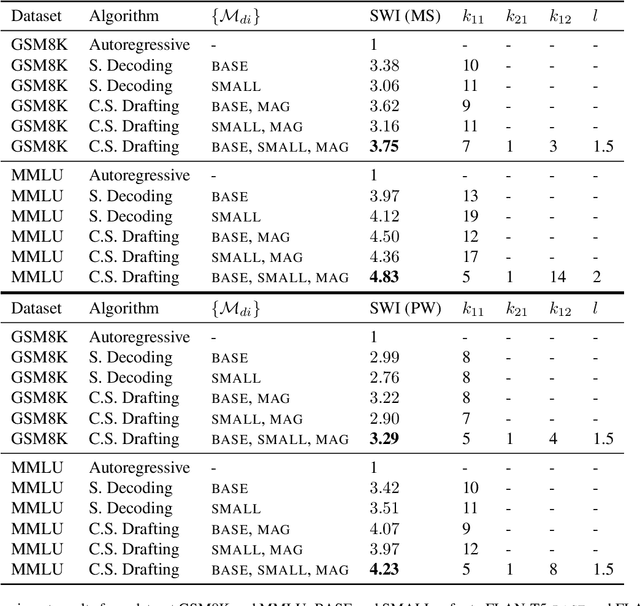
Speculative decoding enhances the efficiency of large language models (LLMs) by leveraging a draft model to draft for a larger target model to review. However, drafting in speculative decoding involves slow autoregressive generation and generating tokens of different importance with the same time allocation. These two inefficiencies lead to its suboptimal performance. To address this issue, we introduce Cascade Speculative Drafting (CS. Drafting), a novel approach that employs two types of cascades. The Vertical Cascade eliminates autoregressive generation from neural models. The Horizontal Cascade constitutes efficient time allocation in drafting with its optimality supported by our theoretical analysis. Combining both cascades, our CS. Drafting algorithm has achieved up to 72 percent additional speedup over speculative decoding in our experiments while keeping the same output distribution.