 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Analogy: Enhancing Few-Shot Prompting for Math Word Problem Solving with Computational Graph-Based Retrieval
Nov 25, 2024



Large language models (LLMs) are known to struggle with complicated reasoning tasks such as math word problems (MWPs). In this paper, we present how analogy from similarly structured questions can improve LLMs' problem-solving capabilities for MWPs. Specifically, we rely on the retrieval of problems with similar computational graphs to the given question to serve as exemplars in the prompt, providing the correct reasoning path for the generation model to refer to. Empirical results across six math word problem datasets demonstrate the effectiveness of our proposed method, which achieves a significant improvement of up to 6.7 percent on average in absolute value, compared to baseline methods. These results highlight our method's potential in addressing the reasoning challenges in current LLMs.
Cascade Speculative Drafting for Even Faster LLM Inference
Dec 21, 2023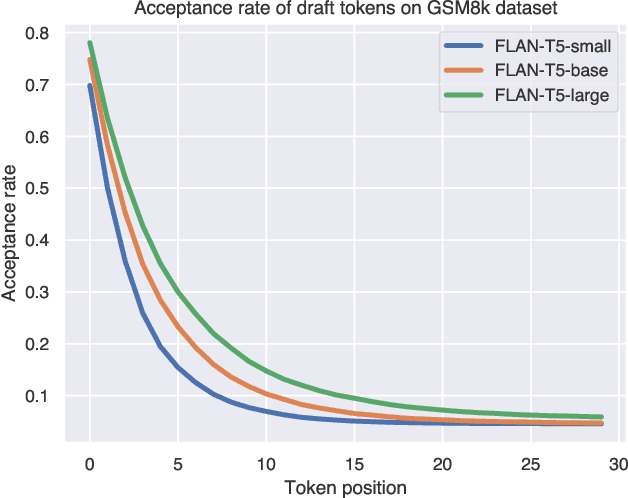

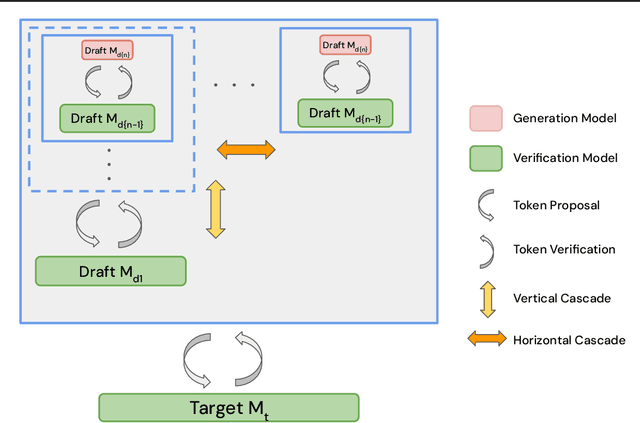
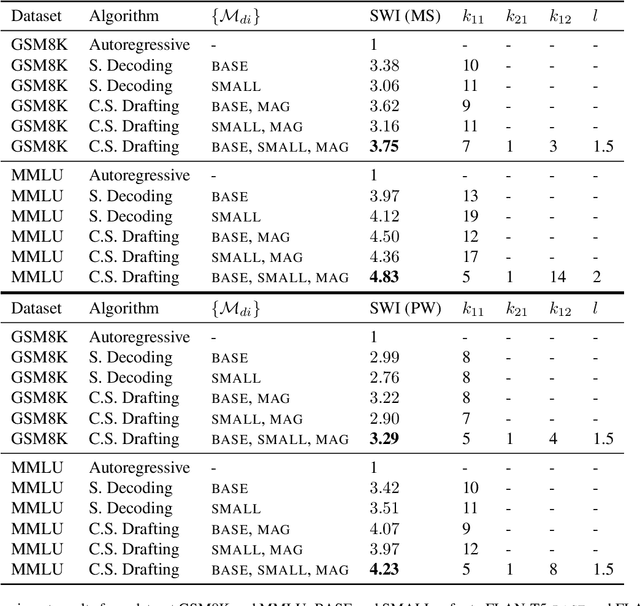
Speculative decoding enhances the efficiency of large language models (LLMs) by leveraging a draft model to draft for a larger target model to review. However, drafting in speculative decoding involves slow autoregressive generation and generating tokens of different importance with the same time allocation. These two inefficiencies lead to its suboptimal performance. To address this issue, we introduce Cascade Speculative Drafting (CS. Drafting), a novel approach that employs two types of cascades. The Vertical Cascade eliminates autoregressive generation from neural models. The Horizontal Cascade constitutes efficient time allocation in drafting with its optimality supported by our theoretical analysis. Combining both cascades, our CS. Drafting algorithm has achieved up to 72 percent additional speedup over speculative decoding in our experiments while keeping the same output distribution.
NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
Nov 07, 2021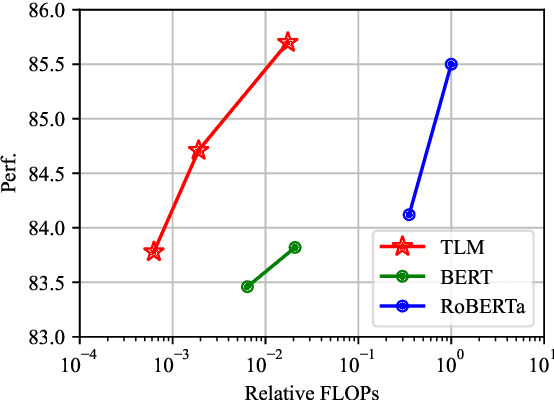
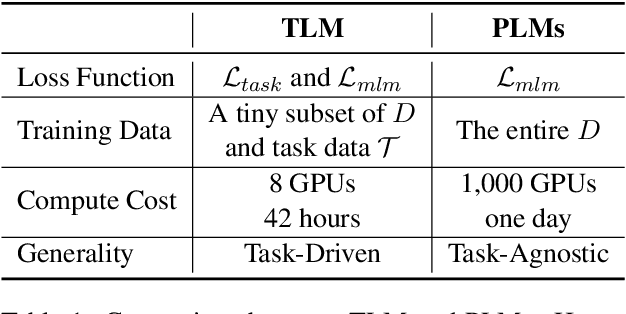
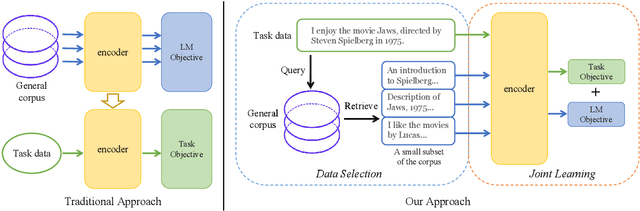
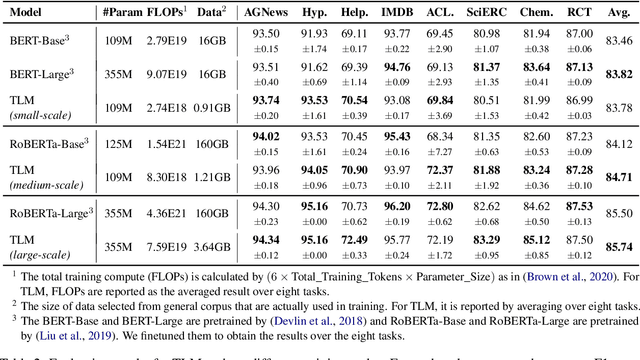
Pretrained language models have become the standard approach for many NLP tasks due to strong performance, but they are very expensive to train. We propose a simple and efficient learning framework, TLM, that does not rely on large-scale pretraining. Given some labeled task data and a large general corpus, TLM uses task data as queries to retrieve a tiny subset of the general corpus and jointly optimizes the task objective and the language modeling objective from scratch. On eight classification datasets in four domains, TLM achieves results better than or similar to pretrained language models (e.g., RoBERTa-Large) while reducing the training FLOPs by two orders of magnitude. With high accuracy and efficiency, we hope TLM will contribute to democratizing NLP and expediting its development.
EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
Aug 03, 2021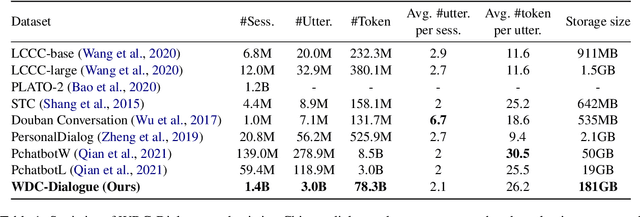
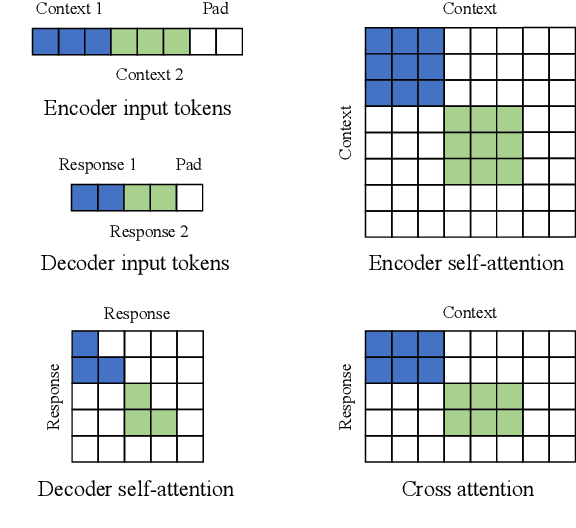
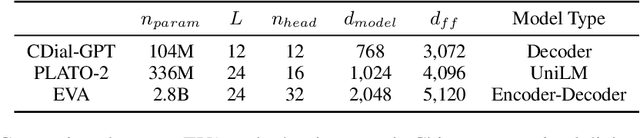
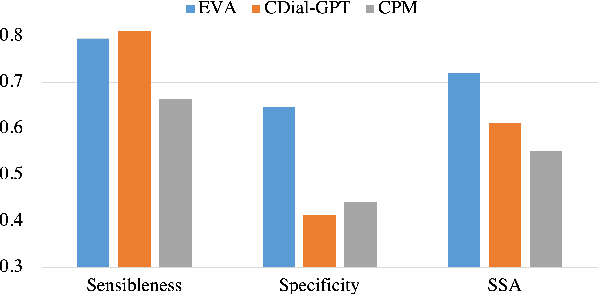
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.