 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Multi-Cultural Knowledge Acquisition & LM Benchmarking
Feb 14, 2024



Pretrained large language models have revolutionized many applications but still face challenges related to cultural bias and a lack of cultural commonsense knowledge crucial for guiding cross-culture communication and interactions. Recognizing the shortcomings of existing methods in capturing the diverse and rich cultures across the world, this paper introduces a novel approach for massively multicultural knowledge acquisition. Specifically, our method strategically navigates from densely informative Wikipedia documents on cultural topics to an extensive network of linked pages. Leveraging this valuable source of data collection, we construct the CultureAtlas dataset, which covers a wide range of sub-country level geographical regions and ethnolinguistic groups, with data cleaning and preprocessing to ensure textual assertion sentence self-containment, as well as fine-grained cultural profile information extraction. Our dataset not only facilitates the evaluation of language model performance in culturally diverse contexts but also serves as a foundational tool for the development of culturally sensitive and aware language models. Our work marks an important step towards deeper understanding and bridging the gaps of cultural disparities in AI, to promote a more inclusive and balanced representation of global cultures in the digital domain.
Instruct and Extract: Instruction Tuning for On-Demand Information Extraction
Oct 24, 2023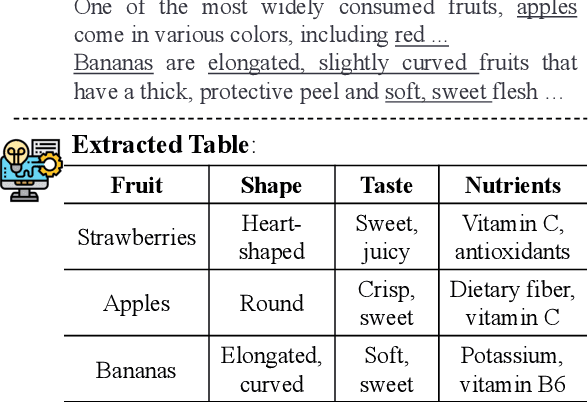
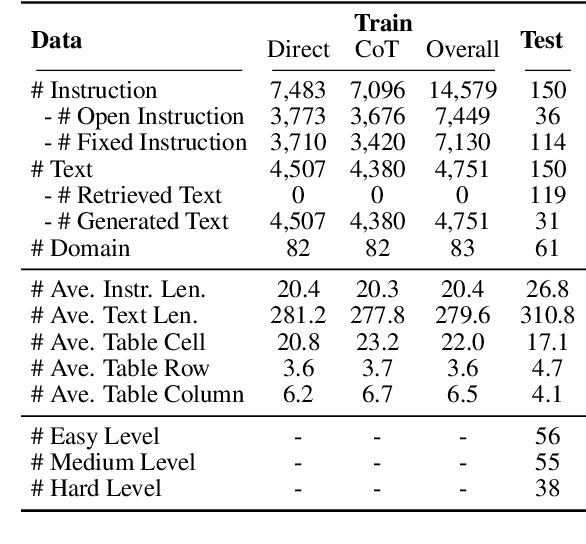
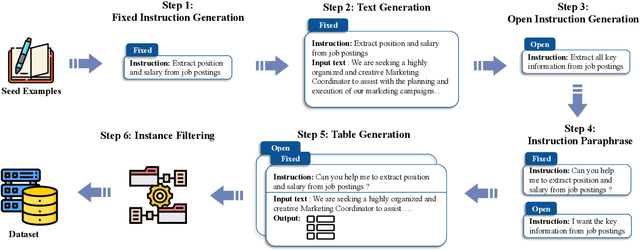
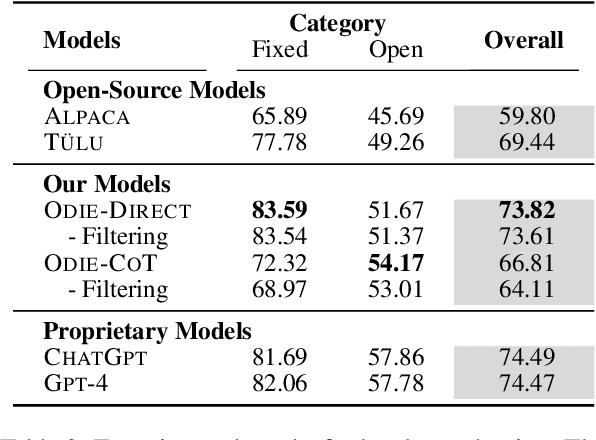
Large language models with instruction-following capabilities open the door to a wider group of users. However, when it comes to information extraction - a classic task in natural language processing - most task-specific systems cannot align well with long-tail ad hoc extraction use cases for non-expert users. To address this, we propose a novel paradigm, termed On-Demand Information Extraction, to fulfill the personalized demands of real-world users. Our task aims to follow the instructions to extract the desired content from the associated text and present it in a structured tabular format. The table headers can either be user-specified or inferred contextually by the model. To facilitate research in this emerging area, we present a benchmark named InstructIE, inclusive of both automatically generated training data, as well as the human-annotated test set. Building on InstructIE, we further develop an On-Demand Information Extractor, ODIE. Comprehensive evaluations on our benchmark reveal that ODIE substantially outperforms the existing open-source models of similar size. Our code and dataset are released on https://github.com/yzjiao/On-Demand-IE.
Open-Domain Hierarchical Event Schema Induction by Incremental Prompting and Verification
Jul 05, 2023Event schemas are a form of world knowledge about the typical progression of events. Recent methods for event schema induction use information extraction systems to construct a large number of event graph instances from documents, and then learn to generalize the schema from such instances. In contrast, we propose to treat event schemas as a form of commonsense knowledge that can be derived from large language models (LLMs). This new paradigm greatly simplifies the schema induction process and allows us to handle both hierarchical relations and temporal relations between events in a straightforward way. Since event schemas have complex graph structures, we design an incremental prompting and verification method to break down the construction of a complex event graph into three stages: event skeleton construction, event expansion, and event-event relation verification. Compared to directly using LLMs to generate a linearized graph, our method can generate large and complex schemas with 7.2% F1 improvement in temporal relations and 31.0% F1 improvement in hierarchical relations. In addition, compared to the previous state-of-the-art closed-domain schema induction model, human assessors were able to cover $\sim$10% more events when translating the schemas into coherent stories and rated our schemas 1.3 points higher (on a 5-point scale) in terms of readability.