 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDywave: Event-Aligned Dynamic Tokenization for Heterogeneous IoT Sensing Signal
May 13, 2026Internet of Things (IoT) systems continuously collect heterogeneous sensing signals from ubiquitous sensors to support intelligent applications such as human activity analysis, emotion monitoring, and environmental perception. These signals are inherently non-stationary and multi-scale, posing unique challenges for standard tokenization techniques. This paper proposes Dywave, a dynamic tokenization framework for IoT sensing signals that constructs compact input representations aligned with intrinsic temporal structures and underlying physical events. Dywave leverages wavelet-based hierarchical decomposition, identifies meaningful temporal boundaries corresponding to underlying semantic events, and adaptively compresses redundant intervals while preserving temporal coherence. Extensive evaluations on five real-world IoT sensing datasets across activity recognition, stress assessment, and nearby object detection demonstrate that Dywave outperforms state-of-the-art methods by up to 12% in accuracy, while improving computational efficiency by reducing input token lengths by up to 75% across mainstream sequence models. Moreover, Dywave exhibits improved robustness to domain shifts and varying sequence lengths.
Tracking without Seeing: Geospatial Inference using Encrypted Traffic from Distributed Nodes
Mar 29, 2026Accurate observation of dynamic environments traditionally relies on synthesizing raw, signal-level information from multiple distributed sensors. This work investigates an alternative approach: performing geospatial inference using only encrypted packet-level information, without access to the raw sensory data. We further explore how this indirect information can be fused with directly available sensory data to extend overall inference capabilities. We introduce GraySense, a learning-based framework that performs geospatial object tracking by analyzing encrypted wireless video transmission traffic, such as packet sizes, from cameras with inaccessible streams. GraySense leverages the inherent relationship between scene dynamics and transmitted packet sizes to infer object motion. The framework consists of two stages: (1) a Packet Grouping module that identifies frame boundaries and estimates frame sizes from encrypted network traffic, and (2) a Tracker module, based on a Transformer encoder with a recurrent state, which fuses indirect packet-based inputs with optional direct camera-based inputs to estimate the object's position. Extensive experiments with realistic videos from the CARLA simulator and emulated networks under varying conditions show that GraySense achieves 2.33 meters tracking error (Euclidean distance) without raw signal access, within the dimensions of tracked objects (4.61m x 1.93m). To our knowledge, this capability has not been previously demonstrated, expanding the use of latent signals for sensing.
Understanding the Theoretical Foundations of Deep Neural Networks through Differential Equations
Mar 18, 2026Deep neural networks (DNNs) have achieved remarkable empirical success, yet the absence of a principled theoretical foundation continues to hinder their systematic development. In this survey, we present differential equations as a theoretical foundation for understanding, analyzing, and improving DNNs. We organize the discussion around three guiding questions: i) how differential equations offer a principled understanding of DNN architectures, ii) how tools from differential equations can be used to improve DNN performance in a principled way, and iii) what real-world applications benefit from grounding DNNs in differential equations. We adopt a two-fold perspective spanning the model level, which interprets the whole DNN as a differential equation, and the layer level, which models individual DNN components as differential equations. From these two perspectives, we review how this framework connects model design, theoretical analysis, and performance improvement. We further discuss real-world applications, as well as key challenges and opportunities for future research.
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Feb 19, 2026Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.
CSRAP: Enhanced Canvas Attention Scheduling for Real-Time Mission Critical Perception
Aug 07, 2025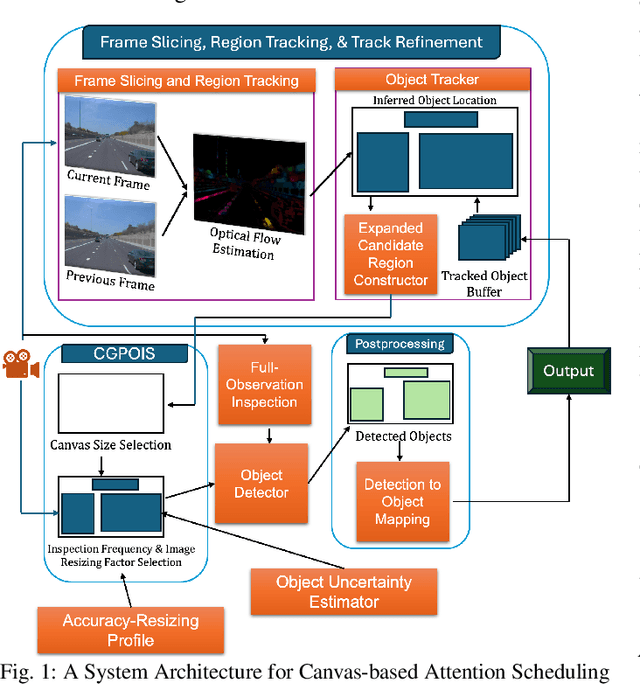
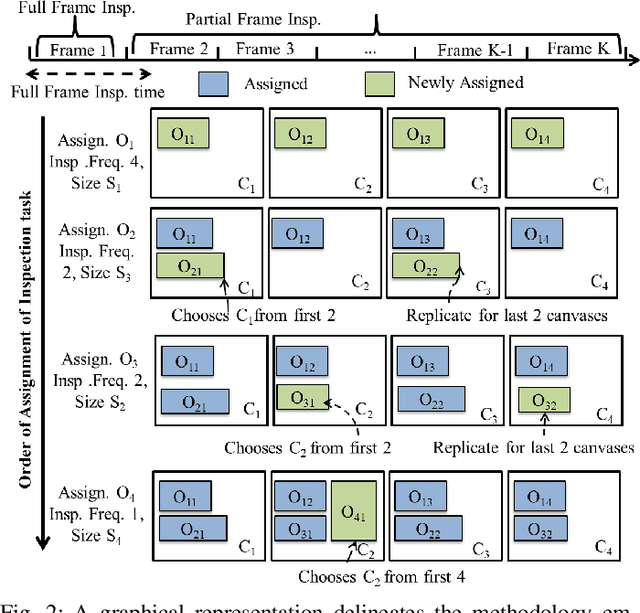
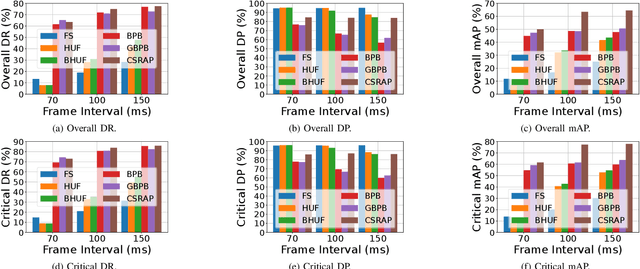
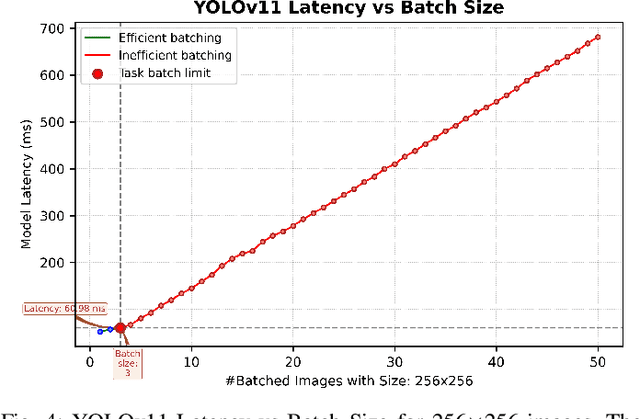
Real-time perception on edge platforms faces a core challenge: executing high-resolution object detection under stringent latency constraints on limited computing resources. Canvas-based attention scheduling was proposed in earlier work as a mechanism to reduce the resource demands of perception subsystems. It consolidates areas of interest in an input data frame onto a smaller area, called a canvas frame, that can be processed at the requisite frame rate. This paper extends prior canvas-based attention scheduling literature by (i) allowing for variable-size canvas frames and (ii) employing selectable canvas frame rates that may depart from the original data frame rate. We evaluate our solution by running YOLOv11, as the perception module, on an NVIDIA Jetson Orin Nano to inspect video frames from the Waymo Open Dataset. Our results show that the additional degrees of freedom improve the attainable quality/cost trade-offs, thereby allowing for a consistently higher mean average precision (mAP) and recall with respect to the state of the art.
DocCHA: Towards LLM-Augmented Interactive Online diagnosis System
Jul 10, 2025Despite the impressive capabilities of Large Language Models (LLMs), existing Conversational Health Agents (CHAs) remain static and brittle, incapable of adaptive multi-turn reasoning, symptom clarification, or transparent decision-making. This hinders their real-world applicability in clinical diagnosis, where iterative and structured dialogue is essential. We propose DocCHA, a confidence-aware, modular framework that emulates clinical reasoning by decomposing the diagnostic process into three stages: (1) symptom elicitation, (2) history acquisition, and (3) causal graph construction. Each module uses interpretable confidence scores to guide adaptive questioning, prioritize informative clarifications, and refine weak reasoning links. Evaluated on two real-world Chinese consultation datasets (IMCS21, DX), DocCHA consistently outperforms strong prompting-based LLM baselines (GPT-3.5, GPT-4o, LLaMA-3), achieving up to 5.18 percent higher diagnostic accuracy and over 30 percent improvement in symptom recall, with only modest increase in dialogue turns. These results demonstrate the effectiveness of DocCHA in enabling structured, transparent, and efficient diagnostic conversations -- paving the way for trustworthy LLM-powered clinical assistants in multilingual and resource-constrained settings.
PASS: Private Attributes Protection with Stochastic Data Substitution
Jun 08, 2025The growing Machine Learning (ML) services require extensive collections of user data, which may inadvertently include people's private information irrelevant to the services. Various studies have been proposed to protect private attributes by removing them from the data while maintaining the utilities of the data for downstream tasks. Nevertheless, as we theoretically and empirically show in the paper, these methods reveal severe vulnerability because of a common weakness rooted in their adversarial training based strategies. To overcome this limitation, we propose a novel approach, PASS, designed to stochastically substitute the original sample with another one according to certain probabilities, which is trained with a novel loss function soundly derived from information-theoretic objective defined for utility-preserving private attributes protection. The comprehensive evaluation of PASS on various datasets of different modalities, including facial images, human activity sensory signals, and voice recording datasets, substantiates PASS's effectiveness and generalizability.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
SPAR: Self-supervised Placement-Aware Representation Learning for Multi-Node IoT Systems
May 22, 2025This work develops the underpinnings of self-supervised placement-aware representation learning given spatially-distributed (multi-view and multimodal) sensor observations, motivated by the need to represent external environmental state in multi-sensor IoT systems in a manner that correctly distills spatial phenomena from the distributed multi-vantage observations. The objective of sensing in IoT systems is, in general, to collectively represent an externally observed environment given multiple vantage points from which sensory observations occur. Pretraining of models that help interpret sensor data must therefore encode the relation between signals observed by sensors and the observers' vantage points in order to attain a representation that encodes the observed spatial phenomena in a manner informed by the specific placement of the measuring instruments, while allowing arbitrary placement. The work significantly advances self-supervised model pretraining from IoT signals beyond current solutions that often overlook the distinctive spatial nature of IoT data. Our framework explicitly learns the dependencies between measurements and geometric observer layouts and structural characteristics, guided by a core design principle: the duality between signals and observer positions. We further provide theoretical analyses from the perspectives of information theory and occlusion-invariant representation learning to offer insight into the rationale behind our design. Experiments on three real-world datasets--covering vehicle monitoring, human activity recognition, and earthquake localization--demonstrate the superior generalizability and robustness of our method across diverse modalities, sensor placements, application-level inference tasks, and spatial scales.
SCRAG: Social Computing-Based Retrieval Augmented Generation for Community Response Forecasting in Social Media Environments
Apr 18, 2025This paper introduces SCRAG, a prediction framework inspired by social computing, designed to forecast community responses to real or hypothetical social media posts. SCRAG can be used by public relations specialists (e.g., to craft messaging in ways that avoid unintended misinterpretations) or public figures and influencers (e.g., to anticipate social responses), among other applications related to public sentiment prediction, crisis management, and social what-if analysis. While large language models (LLMs) have achieved remarkable success in generating coherent and contextually rich text, their reliance on static training data and susceptibility to hallucinations limit their effectiveness at response forecasting in dynamic social media environments. SCRAG overcomes these challenges by integrating LLMs with a Retrieval-Augmented Generation (RAG) technique rooted in social computing. Specifically, our framework retrieves (i) historical responses from the target community to capture their ideological, semantic, and emotional makeup, and (ii) external knowledge from sources such as news articles to inject time-sensitive context. This information is then jointly used to forecast the responses of the target community to new posts or narratives. Extensive experiments across six scenarios on the X platform (formerly Twitter), tested with various embedding models and LLMs, demonstrate over 10% improvements on average in key evaluation metrics. A concrete example further shows its effectiveness in capturing diverse ideologies and nuances. Our work provides a social computing tool for applications where accurate and concrete insights into community responses are crucial.