 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Privacy Always Harm Fairness? Data-Dependent Trade-offs via Chernoff Information Neural Estimation
Jan 20, 2026Fairness and privacy are two vital pillars of trustworthy machine learning. Despite extensive research on these individual topics, the relationship between fairness and privacy has received significantly less attention. In this paper, we utilize the information-theoretic measure Chernoff Information to highlight the data-dependent nature of the relationship among the triad of fairness, privacy, and accuracy. We first define Noisy Chernoff Difference, a tool that allows us to analyze the relationship among the triad simultaneously. We then show that for synthetic data, this value behaves in 3 distinct ways (depending on the distribution of the data). We highlight the data distributions involved in these cases and explore their fairness and privacy implications. Additionally, we show that Noisy Chernoff Difference acts as a proxy for the steepness of the fairness-accuracy curves. Finally, we propose a method for estimating Chernoff Information on data from unknown distributions and utilize this framework to examine the triad dynamic on real datasets. This work builds towards a unified understanding of the fairness-privacy-accuracy relationship and highlights its data-dependent nature.
PASS: Private Attributes Protection with Stochastic Data Substitution
Jun 08, 2025The growing Machine Learning (ML) services require extensive collections of user data, which may inadvertently include people's private information irrelevant to the services. Various studies have been proposed to protect private attributes by removing them from the data while maintaining the utilities of the data for downstream tasks. Nevertheless, as we theoretically and empirically show in the paper, these methods reveal severe vulnerability because of a common weakness rooted in their adversarial training based strategies. To overcome this limitation, we propose a novel approach, PASS, designed to stochastically substitute the original sample with another one according to certain probabilities, which is trained with a novel loss function soundly derived from information-theoretic objective defined for utility-preserving private attributes protection. The comprehensive evaluation of PASS on various datasets of different modalities, including facial images, human activity sensory signals, and voice recording datasets, substantiates PASS's effectiveness and generalizability.
Dropout-Based Rashomon Set Exploration for Efficient Predictive Multiplicity Estimation
Feb 01, 2024



Predictive multiplicity refers to the phenomenon in which classification tasks may admit multiple competing models that achieve almost-equally-optimal performance, yet generate conflicting outputs for individual samples. This presents significant concerns, as it can potentially result in systemic exclusion, inexplicable discrimination, and unfairness in practical applications. Measuring and mitigating predictive multiplicity, however, is computationally challenging due to the need to explore all such almost-equally-optimal models, known as the Rashomon set, in potentially huge hypothesis spaces. To address this challenge, we propose a novel framework that utilizes dropout techniques for exploring models in the Rashomon set. We provide rigorous theoretical derivations to connect the dropout parameters to properties of the Rashomon set, and empirically evaluate our framework through extensive experimentation. Numerical results show that our technique consistently outperforms baselines in terms of the effectiveness of predictive multiplicity metric estimation, with runtime speedup up to $20\times \sim 5000\times$. With efficient Rashomon set exploration and metric estimation, mitigation of predictive multiplicity is then achieved through dropout ensemble and model selection.
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022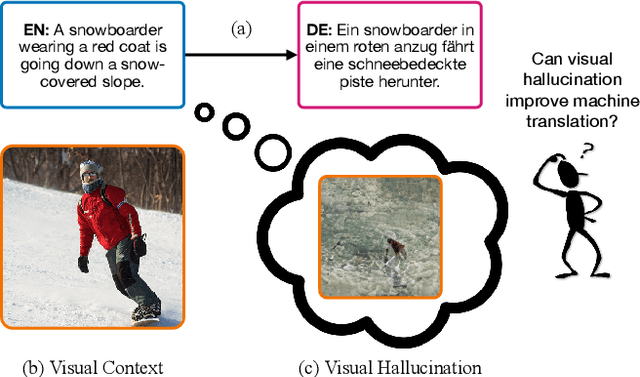
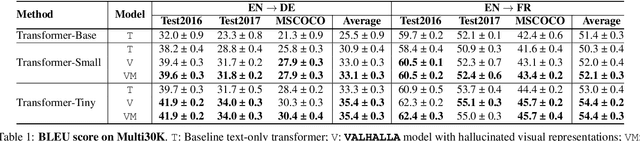
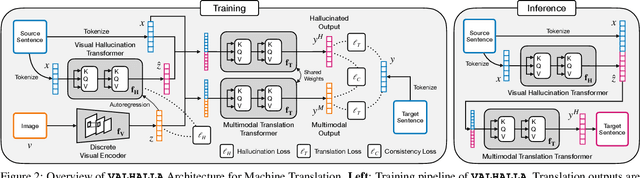

Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
Temporal Relevance Analysis for Video Action Models
Apr 25, 2022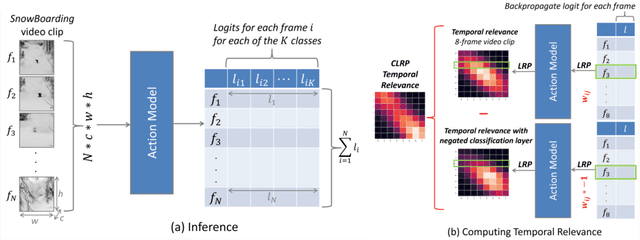
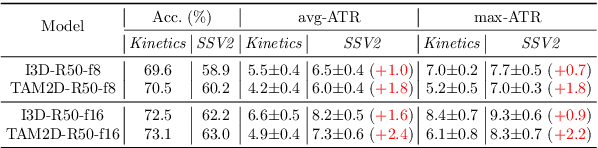
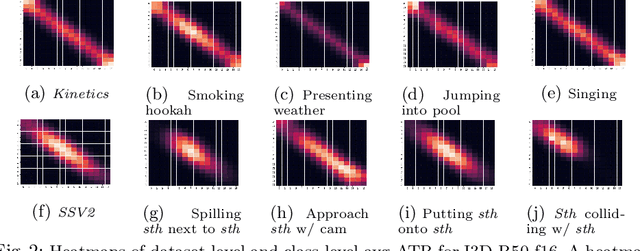
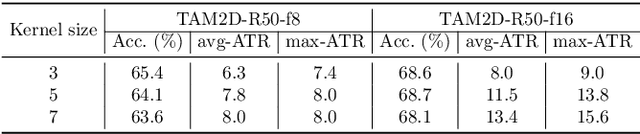
In this paper, we provide a deep analysis of temporal modeling for action recognition, an important but underexplored problem in the literature. We first propose a new approach to quantify the temporal relationships between frames captured by CNN-based action models based on layer-wise relevance propagation. We then conduct comprehensive experiments and in-depth analysis to provide a better understanding of how temporal modeling is affected by various factors such as dataset, network architecture, and input frames. With this, we further study some important questions for action recognition that lead to interesting findings. Our analysis shows that there is no strong correlation between temporal relevance and model performance; and action models tend to capture local temporal information, but less long-range dependencies. Our codes and models will be publicly available.
An Image Classifier Can Suffice For Video Understanding
Jun 30, 2021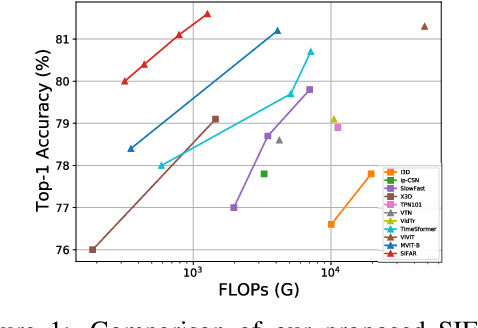
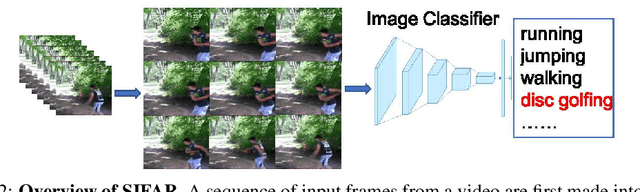
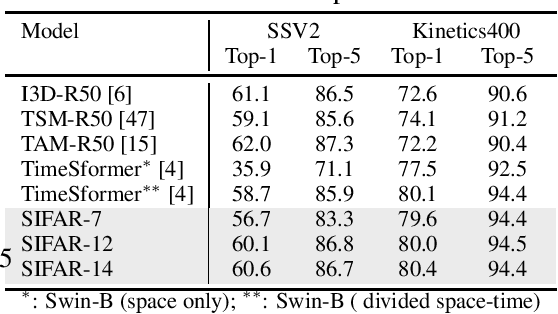
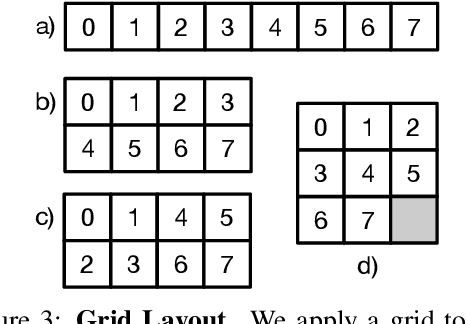
We propose a new perspective on video understanding by casting the video recognition problem as an image recognition task. We show that an image classifier alone can suffice for video understanding without temporal modeling. Our approach is simple and universal. It composes input frames into a super image to train an image classifier to fulfill the task of action recognition, in exactly the same way as classifying an image. We prove the viability of such an idea by demonstrating strong and promising performance on four public datasets including Kinetics400, Something-to-something (V2), MiT and Jester, using a recently developed vision transformer. We also experiment with the prevalent ResNet image classifiers in computer vision to further validate our idea. The results on Kinetics400 are comparable to some of the best-performed CNN approaches based on spatio-temporal modeling. our code and models will be made available at https://github.com/IBM/sifar-pytorch.