 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image Classifier Can Suffice For Video Understanding
Paper and Code
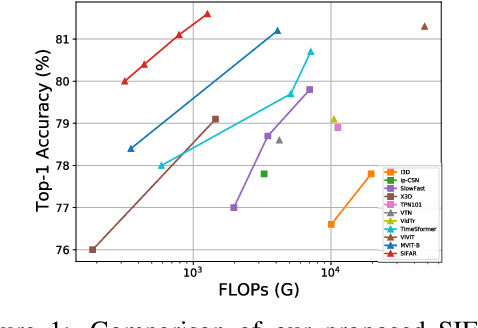
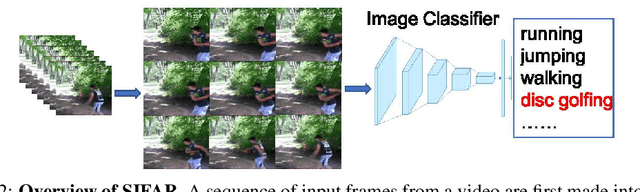
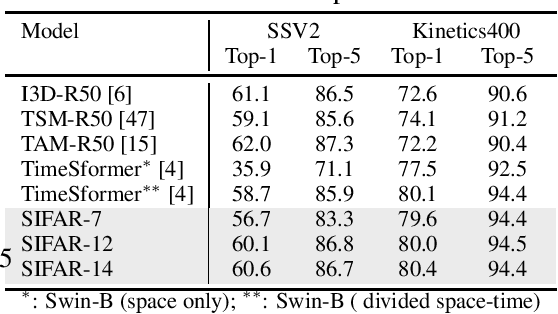
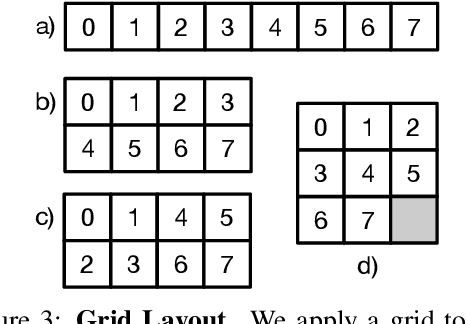
We propose a new perspective on video understanding by casting the video recognition problem as an image recognition task. We show that an image classifier alone can suffice for video understanding without temporal modeling. Our approach is simple and universal. It composes input frames into a super image to train an image classifier to fulfill the task of action recognition, in exactly the same way as classifying an image. We prove the viability of such an idea by demonstrating strong and promising performance on four public datasets including Kinetics400, Something-to-something (V2), MiT and Jester, using a recently developed vision transformer. We also experiment with the prevalent ResNet image classifiers in computer vision to further validate our idea. The results on Kinetics400 are comparable to some of the best-performed CNN approaches based on spatio-temporal modeling. our code and models will be made available at https://github.com/IBM/sifar-pytorch.