 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Video Representation with Temporal Adversarial Augmentation
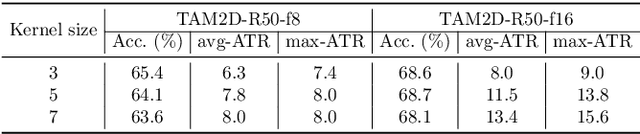
May 14, 2023Recent works reveal that adversarial augmentation benefits the generalization of neural networks (NNs) if used in an appropriate manner. In this paper, we introduce Temporal Adversarial Augmentation (TA), a novel video augmentation technique that utilizes temporal attention. Unlike conventional adversarial augmentation, TA is specifically designed to shift the attention distributions of neural networks with respect to video clips by maximizing a temporal-related loss function. We demonstrate that TA will obtain diverse temporal views, which significantly affect the focus of neural networks. Training with these examples remedies the flaw of unbalanced temporal information perception and enhances the ability to defend against temporal shifts, ultimately leading to better generalization. To leverage TA, we propose Temporal Video Adversarial Fine-tuning (TAF) framework for improving video representations. TAF is a model-agnostic, generic, and interpretability-friendly training strategy. We evaluate TAF with four powerful models (TSM, GST, TAM, and TPN) over three challenging temporal-related benchmarks (Something-something V1&V2 and diving48). Experimental results demonstrate that TAF effectively improves the test accuracy of these models with notable margins without introducing additional parameters or computational costs. As a byproduct, TAF also improves the robustness under out-of-distribution (OOD) settings. Code is available at https://github.com/jinhaoduan/TAF.
Grafting Vision Transformers
Oct 28, 2022



Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.
Augmentation Learning for Semi-Supervised Classification
Aug 03, 2022
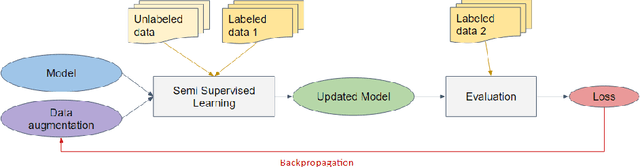

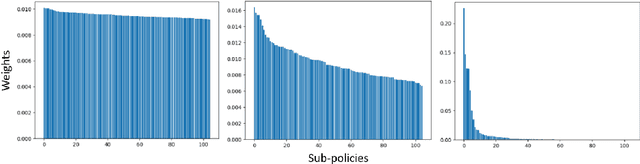
Recently, a number of new Semi-Supervised Learning methods have emerged. As the accuracy for ImageNet and similar datasets increased over time, the performance on tasks beyond the classification of natural images is yet to be explored. Most Semi-Supervised Learning methods rely on a carefully manually designed data augmentation pipeline that is not transferable for learning on images of other domains. In this work, we propose a Semi-Supervised Learning method that automatically selects the most effective data augmentation policy for a particular dataset. We build upon the Fixmatch method and extend it with meta-learning of augmentations. The augmentation is learned in additional training before the classification training and makes use of bi-level optimization, to optimize the augmentation policy and maximize accuracy. We evaluate our approach on two domain-specific datasets, containing satellite images and hand-drawn sketches, and obtain state-of-the-art results. We further investigate in an ablation the different parameters relevant for learning augmentation policies and show how policy learning can be used to adapt augmentations to datasets beyond ImageNet.
Distributed Adversarial Training to Robustify Deep Neural Networks at Scale
Jun 13, 2022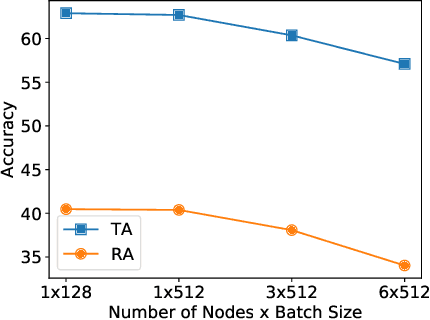
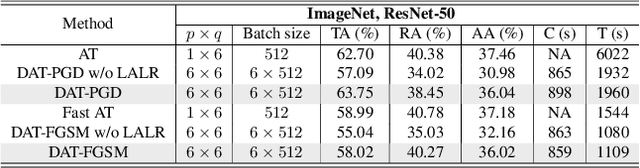
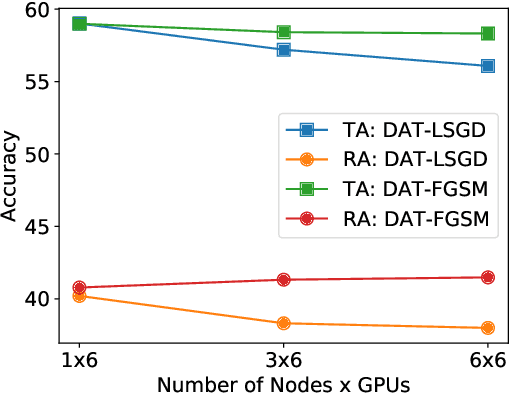
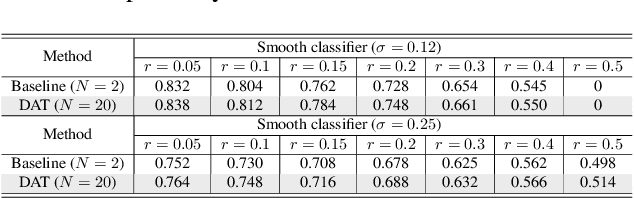
Current deep neural networks (DNNs) are vulnerable to adversarial attacks, where adversarial perturbations to the inputs can change or manipulate classification. To defend against such attacks, an effective and popular approach, known as adversarial training (AT), has been shown to mitigate the negative impact of adversarial attacks by virtue of a min-max robust training method. While effective, it remains unclear whether it can successfully be adapted to the distributed learning context. The power of distributed optimization over multiple machines enables us to scale up robust training over large models and datasets. Spurred by that, we propose distributed adversarial training (DAT), a large-batch adversarial training framework implemented over multiple machines. We show that DAT is general, which supports training over labeled and unlabeled data, multiple types of attack generation methods, and gradient compression operations favored for distributed optimization. Theoretically, we provide, under standard conditions in the optimization theory, the convergence rate of DAT to the first-order stationary points in general non-convex settings. Empirically, we demonstrate that DAT either matches or outperforms state-of-the-art robust accuracies and achieves a graceful training speedup (e.g., on ResNet-50 under ImageNet). Codes are available at https://github.com/dat-2022/dat.
Temporal Relevance Analysis for Video Action Models
Apr 25, 2022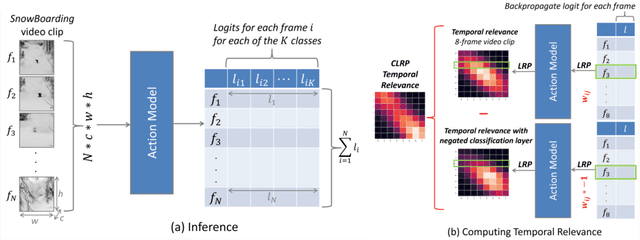
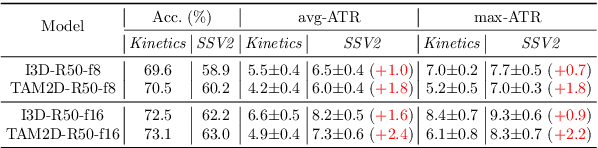
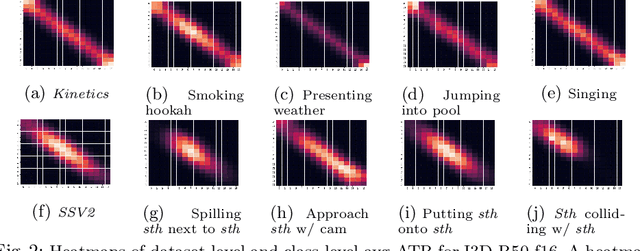
In this paper, we provide a deep analysis of temporal modeling for action recognition, an important but underexplored problem in the literature. We first propose a new approach to quantify the temporal relationships between frames captured by CNN-based action models based on layer-wise relevance propagation. We then conduct comprehensive experiments and in-depth analysis to provide a better understanding of how temporal modeling is affected by various factors such as dataset, network architecture, and input frames. With this, we further study some important questions for action recognition that lead to interesting findings. Our analysis shows that there is no strong correlation between temporal relevance and model performance; and action models tend to capture local temporal information, but less long-range dependencies. Our codes and models will be publicly available.
CryoRL: Reinforcement Learning Enables Efficient Cryo-EM Data Collection
Apr 15, 2022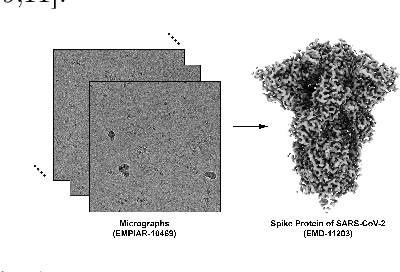

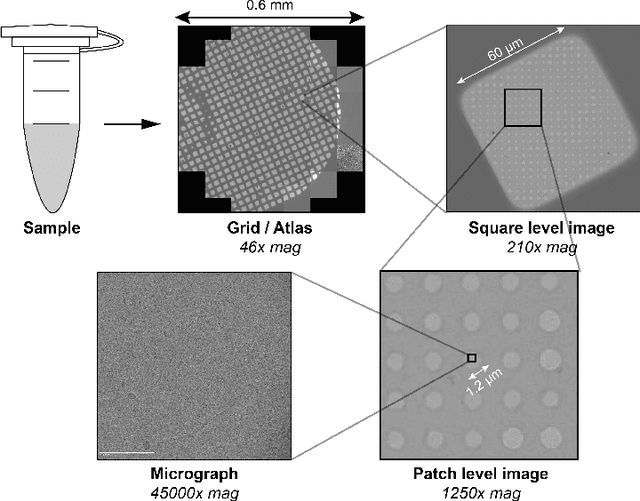

Single-particle cryo-electron microscopy (cryo-EM) has become one of the mainstream structural biology techniques because of its ability to determine high-resolution structures of dynamic bio-molecules. However, cryo-EM data acquisition remains expensive and labor-intensive, requiring substantial expertise. Structural biologists need a more efficient and objective method to collect the best data in a limited time frame. We formulate the cryo-EM data collection task as an optimization problem in this work. The goal is to maximize the total number of good images taken within a specified period. We show that reinforcement learning offers an effective way to plan cryo-EM data collection, successfully navigating heterogenous cryo-EM grids. The approach we developed, cryoRL, demonstrates better performance than average users for data collection under similar settings.
An Image Classifier Can Suffice For Video Understanding
Jun 30, 2021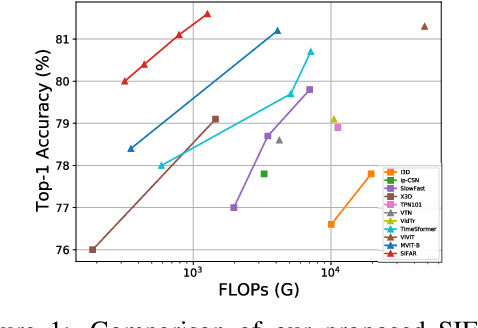
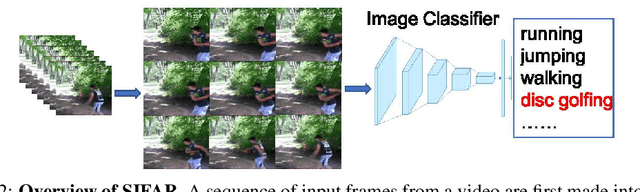
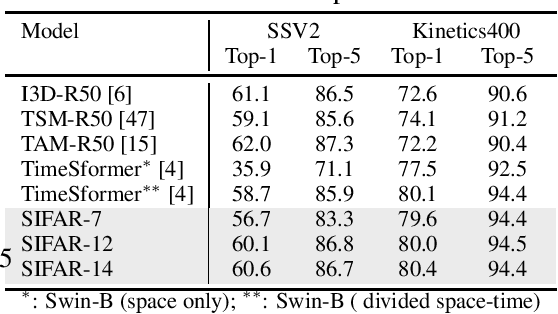
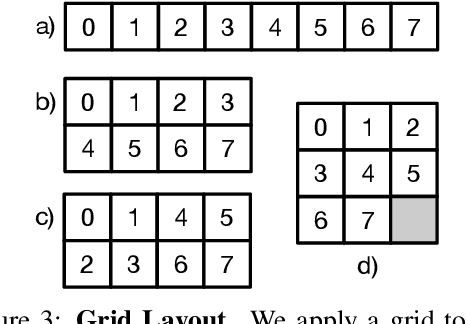
We propose a new perspective on video understanding by casting the video recognition problem as an image recognition task. We show that an image classifier alone can suffice for video understanding without temporal modeling. Our approach is simple and universal. It composes input frames into a super image to train an image classifier to fulfill the task of action recognition, in exactly the same way as classifying an image. We prove the viability of such an idea by demonstrating strong and promising performance on four public datasets including Kinetics400, Something-to-something (V2), MiT and Jester, using a recently developed vision transformer. We also experiment with the prevalent ResNet image classifiers in computer vision to further validate our idea. The results on Kinetics400 are comparable to some of the best-performed CNN approaches based on spatio-temporal modeling. our code and models will be made available at https://github.com/IBM/sifar-pytorch.
RegionViT: Regional-to-Local Attention for Vision Transformers
Jun 04, 2021
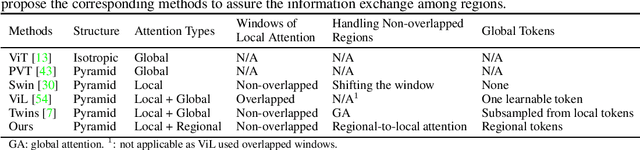

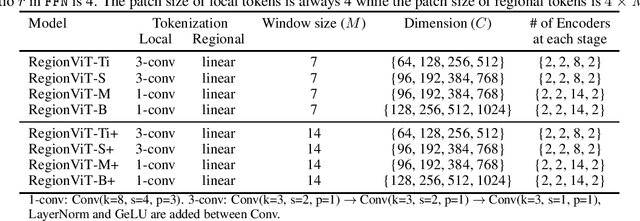
Vision transformer (ViT) has recently showed its strong capability in achieving comparable results to convolutional neural networks (CNNs) on image classification. However, vanilla ViT simply inherits the same architecture from the natural language processing directly, which is often not optimized for vision applications. Motivated by this, in this paper, we propose a new architecture that adopts the pyramid structure and employ a novel regional-to-local attention rather than global self-attention in vision transformers. More specifically, our model first generates regional tokens and local tokens from an image with different patch sizes, where each regional token is associated with a set of local tokens based on the spatial location. The regional-to-local attention includes two steps: first, the regional self-attention extract global information among all regional tokens and then the local self-attention exchanges the information among one regional token and the associated local tokens via self-attention. Therefore, even though local self-attention confines the scope in a local region but it can still receive global information. Extensive experiments on three vision tasks, including image classification, object detection and action recognition, show that our approach outperforms or is on par with state-of-the-art ViT variants including many concurrent works. Our source codes and models will be publicly available.
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
May 12, 2021



Multi-modal learning, which focuses on utilizing various modalities to improve the performance of a model, is widely used in video recognition. While traditional multi-modal learning offers excellent recognition results, its computational expense limits its impact for many real-world applications. In this paper, we propose an adaptive multi-modal learning framework, called AdaMML, that selects on-the-fly the optimal modalities for each segment conditioned on the input for efficient video recognition. Specifically, given a video segment, a multi-modal policy network is used to decide what modalities should be used for processing by the recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on four challenging diverse datasets demonstrate that our proposed adaptive approach yields 35%-55% reduction in computation when compared to the traditional baseline that simply uses all the modalities irrespective of the input, while also achieving consistent improvements in accuracy over the state-of-the-art methods.
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021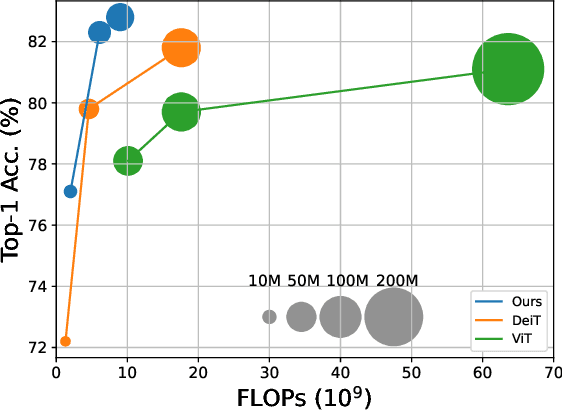
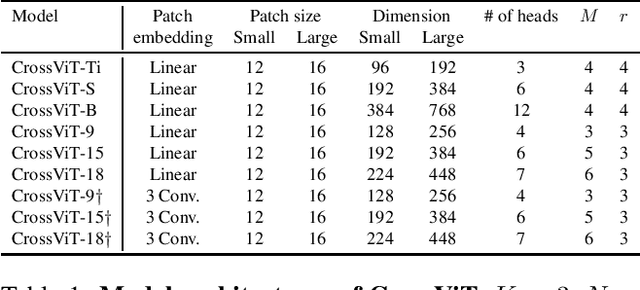


The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%