 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Bandits with Arm Request Costs and Delays
Oct 17, 2024

We introduce a novel extension of the contextual bandit problem, where new sets of arms can be requested with stochastic time delays and associated costs. In this setting, the learner can select multiple arms from a decision set, with each selection taking one unit of time. The problem is framed as a special case of semi-Markov decision processes (SMDPs). The arm contexts, request times, and costs are assumed to follow an unknown distribution. We consider the regret of an online learning algorithm with respect to the optimal policy that achieves the maximum average reward. By leveraging the Bellman optimality equation, we design algorithms that can effectively select arms and determine the appropriate time to request new arms, thereby minimizing their regret. Under the realizability assumption, we analyze the proposed algorithms and demonstrate that their regret upper bounds align with established results in the contextual bandit literature. We validate the algorithms through experiments on simulated data and a movie recommendation dataset, showing that their performance is consistent with theoretical analyses.
CryoRL: Reinforcement Learning Enables Efficient Cryo-EM Data Collection
Apr 15, 2022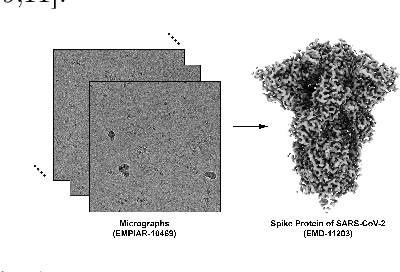

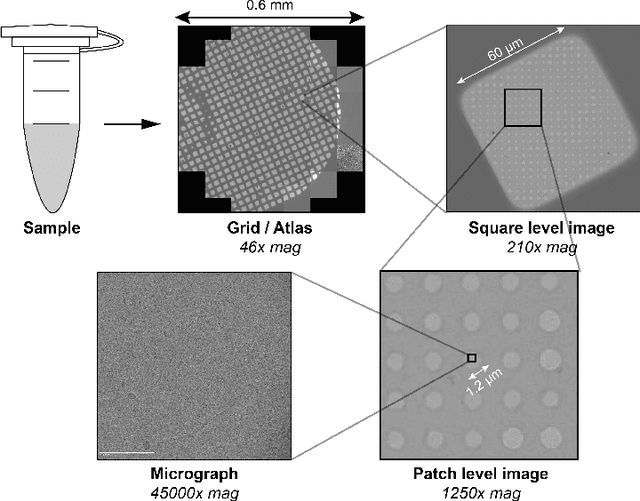

Single-particle cryo-electron microscopy (cryo-EM) has become one of the mainstream structural biology techniques because of its ability to determine high-resolution structures of dynamic bio-molecules. However, cryo-EM data acquisition remains expensive and labor-intensive, requiring substantial expertise. Structural biologists need a more efficient and objective method to collect the best data in a limited time frame. We formulate the cryo-EM data collection task as an optimization problem in this work. The goal is to maximize the total number of good images taken within a specified period. We show that reinforcement learning offers an effective way to plan cryo-EM data collection, successfully navigating heterogenous cryo-EM grids. The approach we developed, cryoRL, demonstrates better performance than average users for data collection under similar settings.