 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Frame Interpolation with Many-to-many Splatting and Spatial Selective Refinement
Oct 29, 2023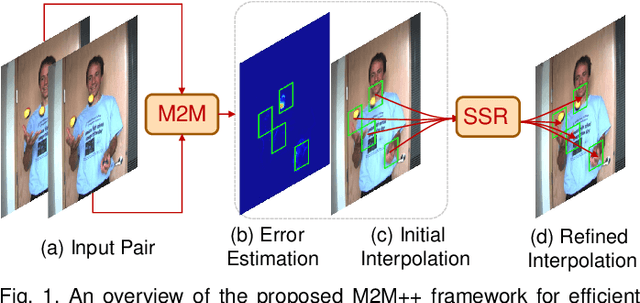
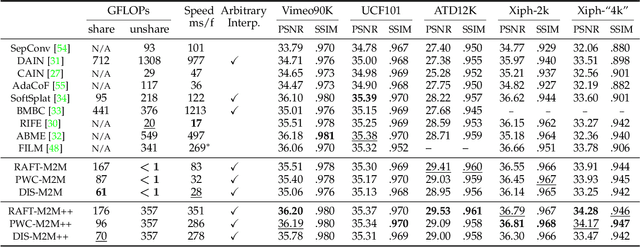
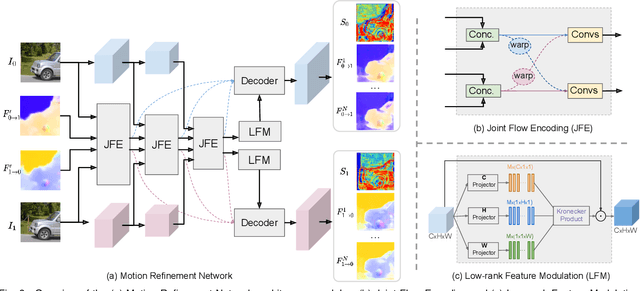
In this work, we first propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step before fusing overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context, establishing a many-to-many splatting scheme with robustness to undesirable artifacts. For each input frame pair, M2M has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. However, directly warping and fusing pixels in the intensity domain is sensitive to the quality of motion estimation and may suffer from less effective representation capacity. To improve interpolation accuracy, we further extend an M2M++ framework by introducing a flexible Spatial Selective Refinement (SSR) component, which allows for trading computational efficiency for interpolation quality and vice versa. Instead of refining the entire interpolated frame, SSR only processes difficult regions selected under the guidance of an estimated error map, thereby avoiding redundant computation. Evaluation on multiple benchmark datasets shows that our method is able to improve the efficiency while maintaining competitive video interpolation quality, and it can be adjusted to use more or less compute as needed.
DualCoOp++: Fast and Effective Adaptation to Multi-Label Recognition with Limited Annotations
Aug 03, 2023
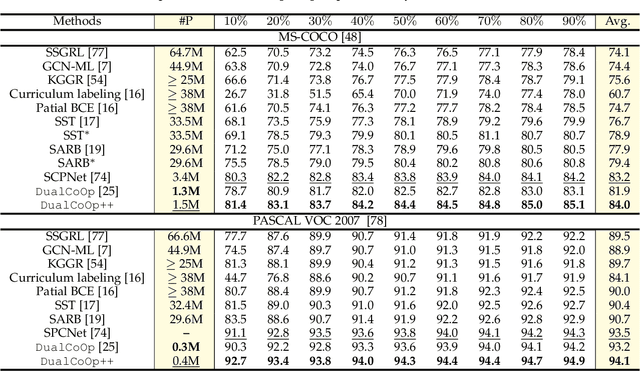
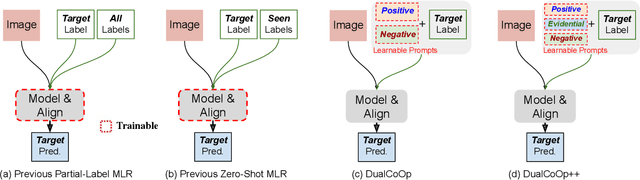
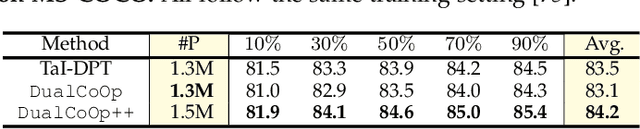
Multi-label image recognition in the low-label regime is a task of great challenge and practical significance. Previous works have focused on learning the alignment between textual and visual spaces to compensate for limited image labels, yet may suffer from reduced accuracy due to the scarcity of high-quality multi-label annotations. In this research, we leverage the powerful alignment between textual and visual features pretrained with millions of auxiliary image-text pairs. We introduce an efficient and effective framework called Evidence-guided Dual Context Optimization (DualCoOp++), which serves as a unified approach for addressing partial-label and zero-shot multi-label recognition. In DualCoOp++ we separately encode evidential, positive, and negative contexts for target classes as parametric components of the linguistic input (i.e., prompts). The evidential context aims to discover all the related visual content for the target class, and serves as guidance to aggregate positive and negative contexts from the spatial domain of the image, enabling better distinguishment between similar categories. Additionally, we introduce a Winner-Take-All module that promotes inter-class interaction during training, while avoiding the need for extra parameters and costs. As DualCoOp++ imposes minimal additional learnable overhead on the pretrained vision-language framework, it enables rapid adaptation to multi-label recognition tasks with limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the superior performance of our approach compared to state-of-the-art methods.
Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
Jun 30, 2023



Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional neural networks (CNNs). Although the jury is still out on which model type is superior, each has unique inductive biases that shape their learning and generalization performance. For example, ViTs have interesting properties with respect to early layer non-local feature dependence, as well as self-attention mechanisms which enhance learning flexibility, enabling them to ignore out-of-context image information more effectively. We hypothesize that this power to ignore out-of-context information (which we name $\textit{patch selectivity}$), while integrating in-context information in a non-local manner in early layers, allows ViTs to more easily handle occlusion. In this study, our aim is to see whether we can have CNNs $\textit{simulate}$ this ability of patch selectivity by effectively hardwiring this inductive bias using Patch Mixing data augmentation, which consists of inserting patches from another image onto a training image and interpolating labels between the two image classes. Specifically, we use Patch Mixing to train state-of-the-art ViTs and CNNs, assessing its impact on their ability to ignore out-of-context patches and handle natural occlusions. We find that ViTs do not improve nor degrade when trained using Patch Mixing, but CNNs acquire new capabilities to ignore out-of-context information and improve on occlusion benchmarks, leaving us to conclude that this training method is a way of simulating in CNNs the abilities that ViTs already possess. We will release our Patch Mixing implementation and proposed datasets for public use. Project page: https://arielnlee.github.io/PatchMixing/
The 7th AI City Challenge
Apr 15, 2023
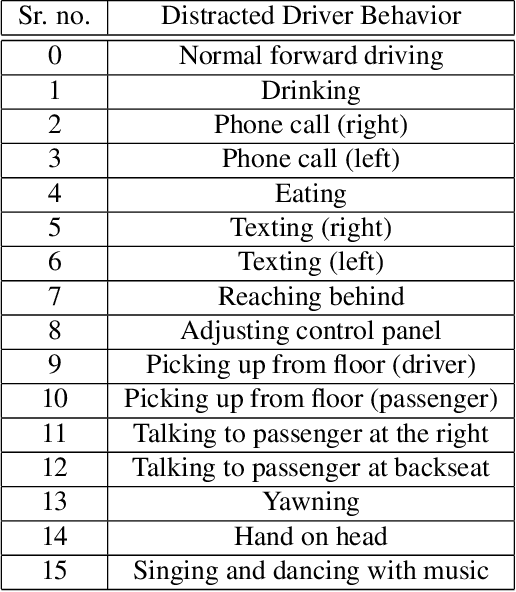

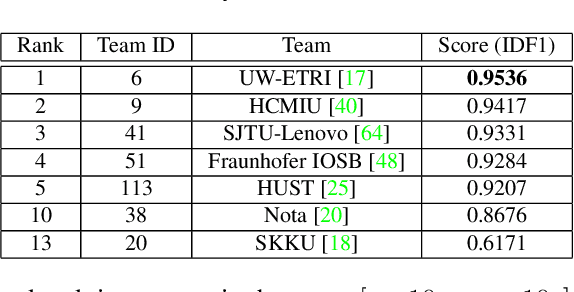
The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing
Nov 29, 2022



Modern deep neural networks tend to be evaluated on static test sets. One shortcoming of this is the fact that these deep neural networks cannot be easily evaluated for robustness issues with respect to specific scene variations. For example, it is hard to study the robustness of these networks to variations of object scale, object pose, scene lighting and 3D occlusions. The main reason is that collecting real datasets with fine-grained naturalistic variations of sufficient scale can be extremely time-consuming and expensive. In this work, we present Counterfactual Simulation Testing, a counterfactual framework that allows us to study the robustness of neural networks with respect to some of these naturalistic variations by building realistic synthetic scenes that allow us to ask counterfactual questions to the models, ultimately providing answers to questions such as "Would your classification still be correct if the object were viewed from the top?" or "Would your classification still be correct if the object were partially occluded by another object?". Our method allows for a fair comparison of the robustness of recently released, state-of-the-art Convolutional Neural Networks and Vision Transformers, with respect to these naturalistic variations. We find evidence that ConvNext is more robust to pose and scale variations than Swin, that ConvNext generalizes better to our simulated domain and that Swin handles partial occlusion better than ConvNext. We also find that robustness for all networks improves with network scale and with data scale and variety. We release the Naturalistic Variation Object Dataset (NVD), a large simulated dataset of 272k images of everyday objects with naturalistic variations such as object pose, scale, viewpoint, lighting and occlusions. Project page: https://counterfactualsimulation.github.io
Temporal Relevance Analysis for Video Action Models
Apr 25, 2022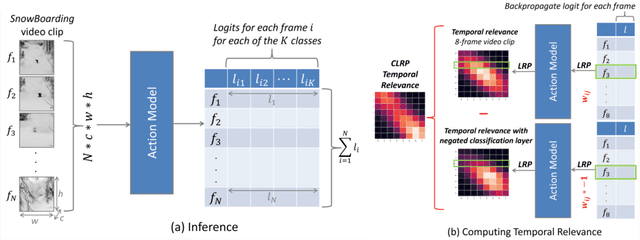
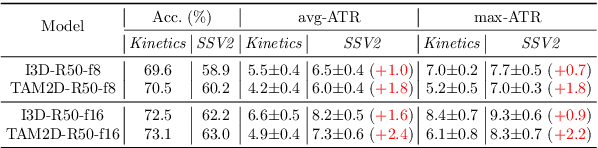
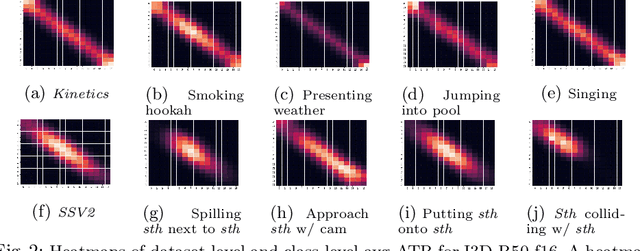
In this paper, we provide a deep analysis of temporal modeling for action recognition, an important but underexplored problem in the literature. We first propose a new approach to quantify the temporal relationships between frames captured by CNN-based action models based on layer-wise relevance propagation. We then conduct comprehensive experiments and in-depth analysis to provide a better understanding of how temporal modeling is affected by various factors such as dataset, network architecture, and input frames. With this, we further study some important questions for action recognition that lead to interesting findings. Our analysis shows that there is no strong correlation between temporal relevance and model performance; and action models tend to capture local temporal information, but less long-range dependencies. Our codes and models will be publicly available.
The 6th AI City Challenge
Apr 21, 2022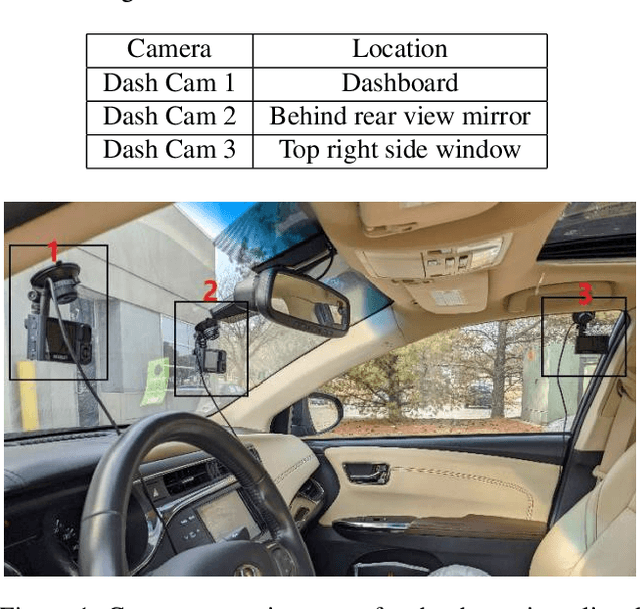
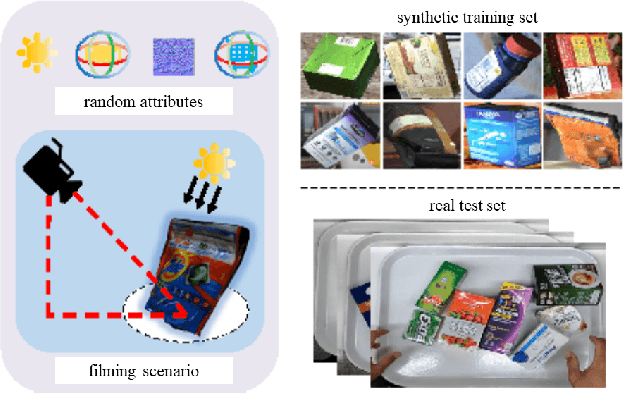
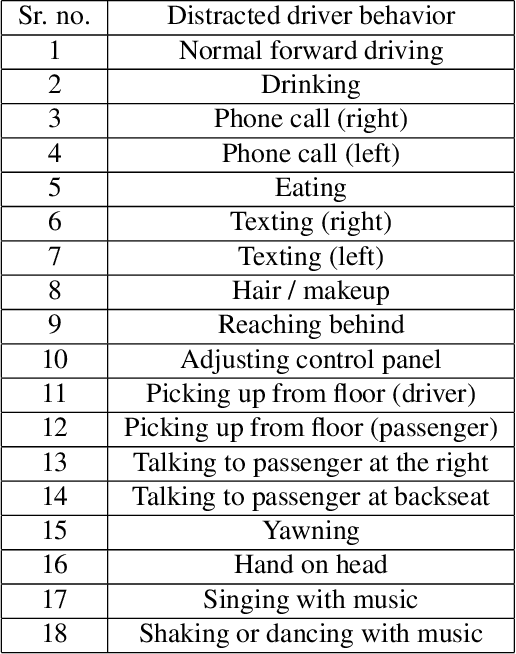
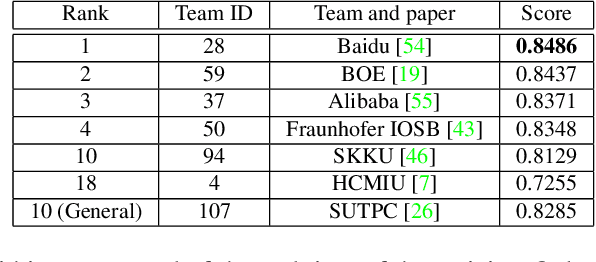
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Many-to-many Splatting for Efficient Video Frame Interpolation
Apr 07, 2022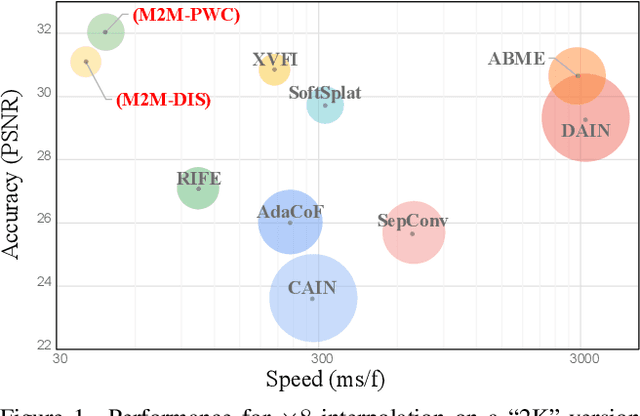
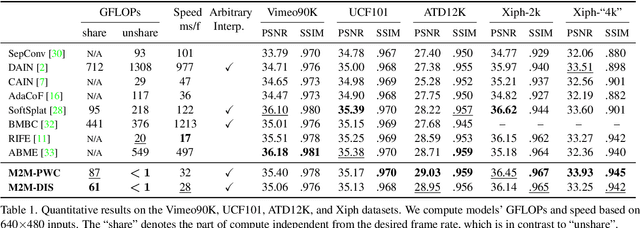
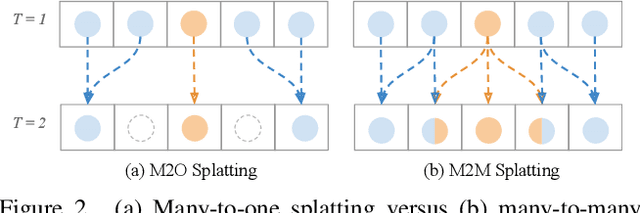
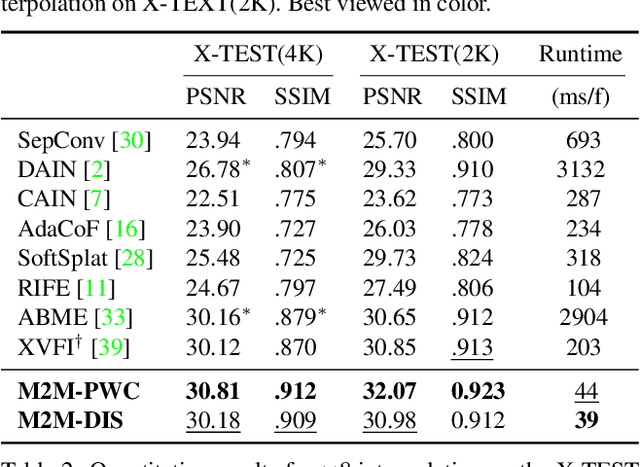
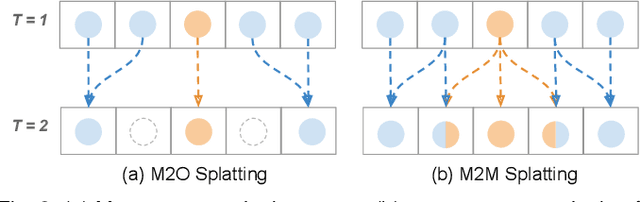
Motion-based video frame interpolation commonly relies on optical flow to warp pixels from the inputs to the desired interpolation instant. Yet due to the inherent challenges of motion estimation (e.g. occlusions and discontinuities), most state-of-the-art interpolation approaches require subsequent refinement of the warped result to generate satisfying outputs, which drastically decreases the efficiency for multi-frame interpolation. In this work, we propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Specifically, given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step, and then fuse any overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context. This establishes a many-to-many splatting scheme with robustness to artifacts like holes. Moreover, for each input frame pair, M2M only performs motion estimation once and has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. We conducted extensive experiments to analyze M2M, and found that it significantly improves efficiency while maintaining high effectiveness.
A Unified Framework for Domain Adaptive Pose Estimation
Apr 06, 2022
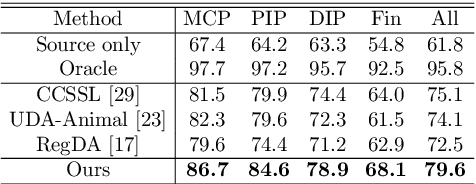
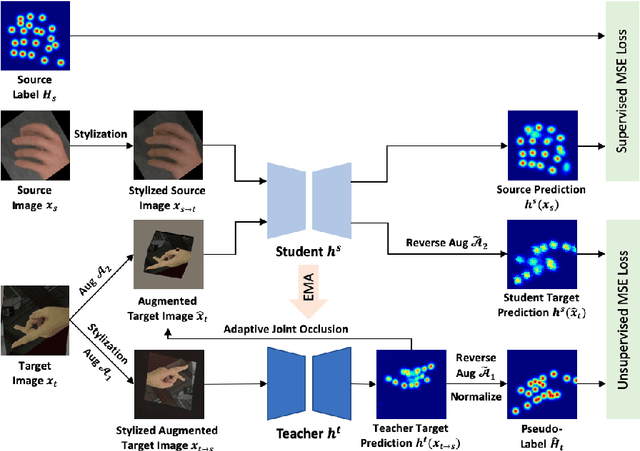
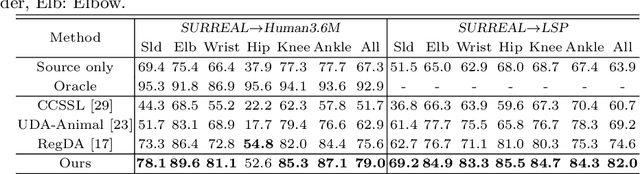
While pose estimation is an important computer vision task, it requires expensive annotation and suffers from domain shift. In this paper, we investigate the problem of domain adaptive 2D pose estimation that transfers knowledge learned on a synthetic source domain to a target domain without supervision. While several domain adaptive pose estimation models have been proposed recently, they are not generic but only focus on either human pose or animal pose estimation, and thus their effectiveness is somewhat limited to specific scenarios. In this work, we propose a unified framework that generalizes well on various domain adaptive pose estimation problems. We propose to align representations using both input-level and output-level cues (pixels and pose labels, respectively), which facilitates the knowledge transfer from the source domain to the unlabeled target domain. Our experiments show that our method achieves state-of-the-art performance under various domain shifts. Our method outperforms existing baselines on human pose estimation by up to 4.5 percent points (pp), hand pose estimation by up to 7.4 pp, and animal pose estimation by up to 4.8 pp for dogs and 3.3 pp for sheep. These results suggest that our method is able to mitigate domain shift on diverse tasks and even unseen domains and objects (e.g., trained on horse and tested on dog).
A Broad Study of Pre-training for Domain Generalization and Adaptation
Mar 25, 2022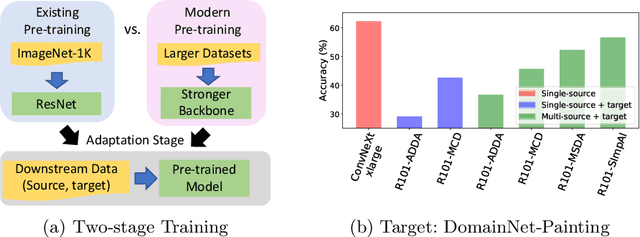
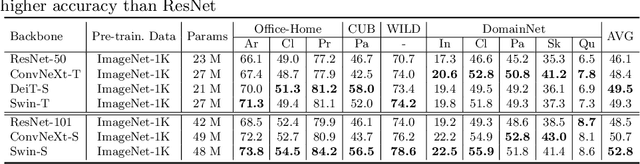
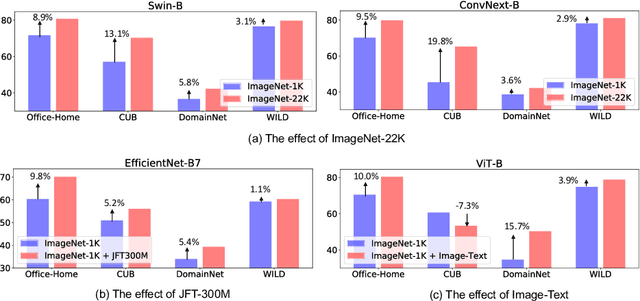
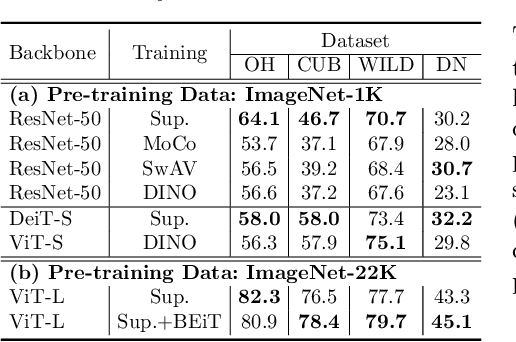
Deep models must learn robust and transferable representations in order to perform well on new domains. While domain transfer methods (e.g., domain adaptation, domain generalization) have been proposed to learn transferable representations across domains, they are typically applied to ResNet backbones pre-trained on ImageNet. Thus, existing works pay little attention to the effects of pre-training on domain transfer tasks. In this paper, we provide a broad study and in-depth analysis of pre-training for domain adaptation and generalization, namely: network architectures, size, pre-training loss, and datasets. We observe that simply using a state-of-the-art backbone outperforms existing state-of-the-art domain adaptation baselines and set new baselines on Office-Home and DomainNet improving by 10.7\% and 5.5\%. We hope that this work can provide more insights for future domain transfer research.