 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualCoOp++: Fast and Effective Adaptation to Multi-Label Recognition with Limited Annotations
Paper and Code
Aug 03, 2023
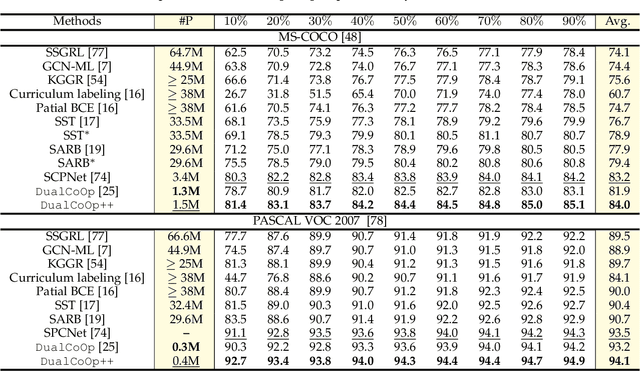
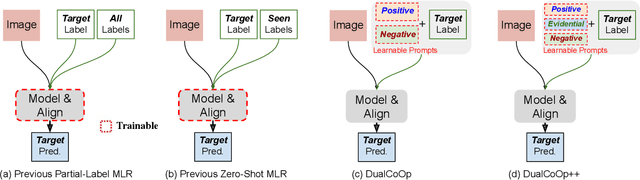
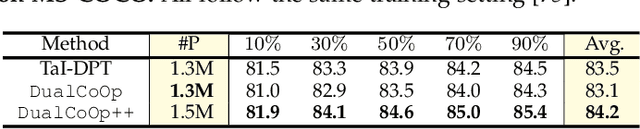
Multi-label image recognition in the low-label regime is a task of great challenge and practical significance. Previous works have focused on learning the alignment between textual and visual spaces to compensate for limited image labels, yet may suffer from reduced accuracy due to the scarcity of high-quality multi-label annotations. In this research, we leverage the powerful alignment between textual and visual features pretrained with millions of auxiliary image-text pairs. We introduce an efficient and effective framework called Evidence-guided Dual Context Optimization (DualCoOp++), which serves as a unified approach for addressing partial-label and zero-shot multi-label recognition. In DualCoOp++ we separately encode evidential, positive, and negative contexts for target classes as parametric components of the linguistic input (i.e., prompts). The evidential context aims to discover all the related visual content for the target class, and serves as guidance to aggregate positive and negative contexts from the spatial domain of the image, enabling better distinguishment between similar categories. Additionally, we introduce a Winner-Take-All module that promotes inter-class interaction during training, while avoiding the need for extra parameters and costs. As DualCoOp++ imposes minimal additional learnable overhead on the pretrained vision-language framework, it enables rapid adaptation to multi-label recognition tasks with limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the superior performance of our approach compared to state-of-the-art methods.