 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocCHA: Towards LLM-Augmented Interactive Online diagnosis System
Jul 10, 2025Despite the impressive capabilities of Large Language Models (LLMs), existing Conversational Health Agents (CHAs) remain static and brittle, incapable of adaptive multi-turn reasoning, symptom clarification, or transparent decision-making. This hinders their real-world applicability in clinical diagnosis, where iterative and structured dialogue is essential. We propose DocCHA, a confidence-aware, modular framework that emulates clinical reasoning by decomposing the diagnostic process into three stages: (1) symptom elicitation, (2) history acquisition, and (3) causal graph construction. Each module uses interpretable confidence scores to guide adaptive questioning, prioritize informative clarifications, and refine weak reasoning links. Evaluated on two real-world Chinese consultation datasets (IMCS21, DX), DocCHA consistently outperforms strong prompting-based LLM baselines (GPT-3.5, GPT-4o, LLaMA-3), achieving up to 5.18 percent higher diagnostic accuracy and over 30 percent improvement in symptom recall, with only modest increase in dialogue turns. These results demonstrate the effectiveness of DocCHA in enabling structured, transparent, and efficient diagnostic conversations -- paving the way for trustworthy LLM-powered clinical assistants in multilingual and resource-constrained settings.
SCRAG: Social Computing-Based Retrieval Augmented Generation for Community Response Forecasting in Social Media Environments
Apr 18, 2025This paper introduces SCRAG, a prediction framework inspired by social computing, designed to forecast community responses to real or hypothetical social media posts. SCRAG can be used by public relations specialists (e.g., to craft messaging in ways that avoid unintended misinterpretations) or public figures and influencers (e.g., to anticipate social responses), among other applications related to public sentiment prediction, crisis management, and social what-if analysis. While large language models (LLMs) have achieved remarkable success in generating coherent and contextually rich text, their reliance on static training data and susceptibility to hallucinations limit their effectiveness at response forecasting in dynamic social media environments. SCRAG overcomes these challenges by integrating LLMs with a Retrieval-Augmented Generation (RAG) technique rooted in social computing. Specifically, our framework retrieves (i) historical responses from the target community to capture their ideological, semantic, and emotional makeup, and (ii) external knowledge from sources such as news articles to inject time-sensitive context. This information is then jointly used to forecast the responses of the target community to new posts or narratives. Extensive experiments across six scenarios on the X platform (formerly Twitter), tested with various embedding models and LLMs, demonstrate over 10% improvements on average in key evaluation metrics. A concrete example further shows its effectiveness in capturing diverse ideologies and nuances. Our work provides a social computing tool for applications where accurate and concrete insights into community responses are crucial.
Uncovering Cross-Domain Recommendation Ability of Large Language Models
Mar 10, 2025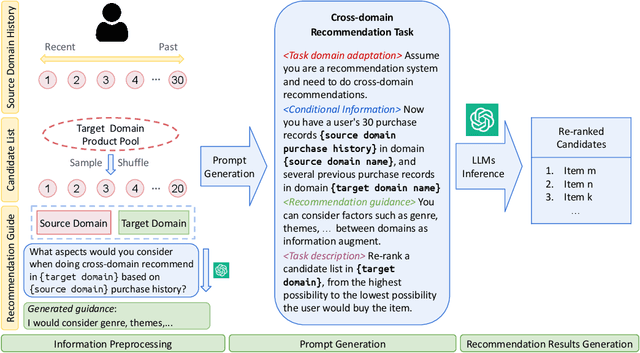
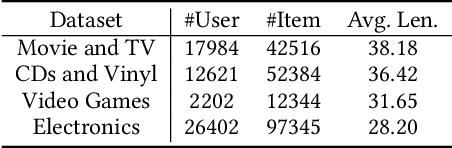

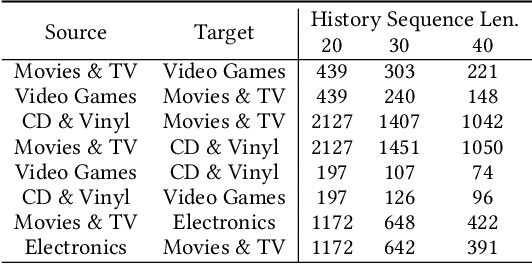
Cross-Domain Recommendation (CDR) seeks to enhance item retrieval in low-resource domains by transferring knowledge from high-resource domains. While recent advancements in Large Language Models (LLMs) have demonstrated their potential in Recommender Systems (RS), their ability to effectively transfer domain knowledge for improved recommendations remains underexplored. To bridge this gap, we propose LLM4CDR, a novel CDR pipeline that constructs context-aware prompts by leveraging users' purchase history sequences from a source domain along with shared features between source and target domains. Through extensive experiments, we show that LLM4CDR achieves strong performance, particularly when using LLMs with large parameter sizes and when the source and target domains exhibit smaller domain gaps. For instance, incorporating CD and Vinyl purchase history for recommendations in Movies and TV yields a 64.28 percent MAP 1 improvement. We further investigate key factors including source domain data, domain gap, prompt design, and LLM size, which impact LLM4CDR's effectiveness in CDR tasks. Our results highlight that LLM4CDR excels when leveraging a single, closely related source domain and benefits significantly from larger LLMs. These insights pave the way for future research on LLM-driven cross-domain recommendations.
Perturbation-based Graph Active Learning for Weakly-Supervised Belief Representation Learning
Oct 24, 2024



This paper addresses the problem of optimizing the allocation of labeling resources for semi-supervised belief representation learning in social networks. The objective is to strategically identify valuable messages on social media graphs that are worth labeling within a constrained budget, ultimately maximizing the task's performance. Despite the progress in unsupervised or semi-supervised methods in advancing belief and ideology representation learning on social networks and the remarkable efficacy of graph learning techniques, the availability of high-quality curated labeled social data can greatly benefit and further improve performances. Consequently, allocating labeling efforts is a critical research problem in scenarios where labeling resources are limited. This paper proposes a graph data augmentation-inspired perturbation-based active learning strategy (PerbALGraph) that progressively selects messages for labeling according to an automatic estimator, obviating human guidance. This estimator is based on the principle that messages in the network that exhibit heightened sensitivity to structural features of the observational data indicate landmark quality that significantly influences semi-supervision processes. We design the estimator to be the prediction variance under a set of designed graph perturbations, which is model-agnostic and application-independent. Extensive experiment results demonstrate the effectiveness of the proposed strategy for belief representation learning tasks.
Noisy Positive-Unlabeled Learning with Self-Training for Speculative Knowledge Graph Reasoning
Jun 13, 2023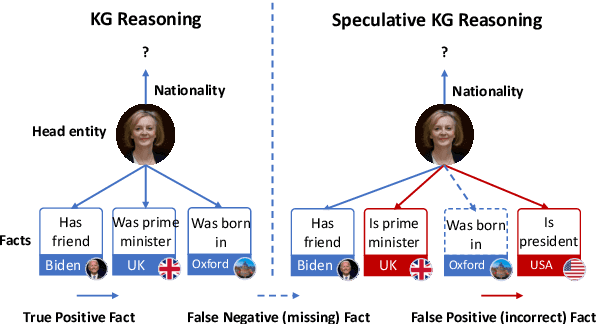
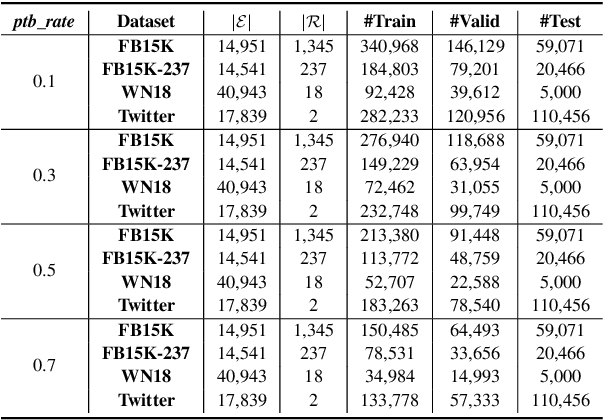
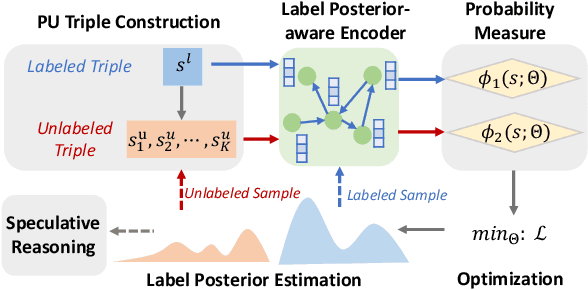
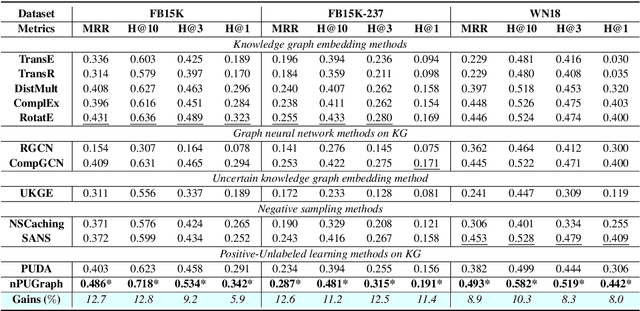
This paper studies speculative reasoning task on real-world knowledge graphs (KG) that contain both \textit{false negative issue} (i.e., potential true facts being excluded) and \textit{false positive issue} (i.e., unreliable or outdated facts being included). State-of-the-art methods fall short in the speculative reasoning ability, as they assume the correctness of a fact is solely determined by its presence in KG, making them vulnerable to false negative/positive issues. The new reasoning task is formulated as a noisy Positive-Unlabeled learning problem. We propose a variational framework, namely nPUGraph, that jointly estimates the correctness of both collected and uncollected facts (which we call \textit{label posterior}) and updates model parameters during training. The label posterior estimation facilitates speculative reasoning from two perspectives. First, it improves the robustness of a label posterior-aware graph encoder against false positive links. Second, it identifies missing facts to provide high-quality grounds of reasoning. They are unified in a simple yet effective self-training procedure. Empirically, extensive experiments on three benchmark KG and one Twitter dataset with various degrees of false negative/positive cases demonstrate the effectiveness of nPUGraph.
Learning to Sample and Aggregate: Few-shot Reasoning over Temporal Knowledge Graphs
Oct 16, 2022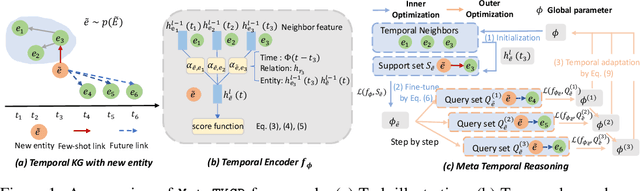
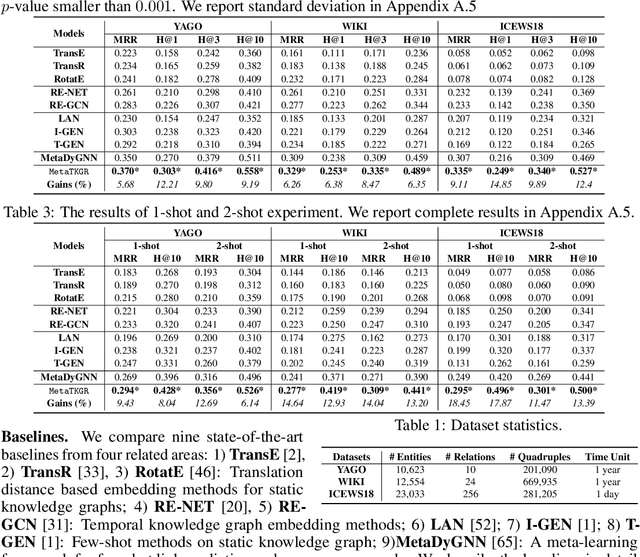
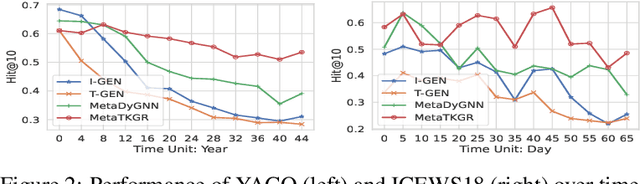
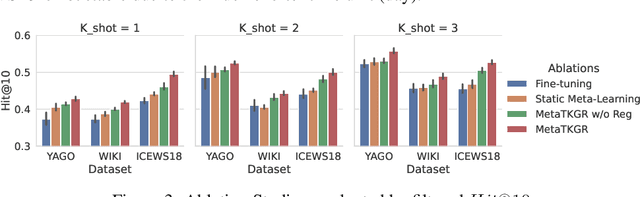
In this paper, we investigate a realistic but underexplored problem, called few-shot temporal knowledge graph reasoning, that aims to predict future facts for newly emerging entities based on extremely limited observations in evolving graphs. It offers practical value in applications that need to derive instant new knowledge about new entities in temporal knowledge graphs (TKGs) with minimal supervision. The challenges mainly come from the few-shot and time shift properties of new entities. First, the limited observations associated with them are insufficient for training a model from scratch. Second, the potentially dynamic distributions from the initially observable facts to the future facts ask for explicitly modeling the evolving characteristics of new entities. We correspondingly propose a novel Meta Temporal Knowledge Graph Reasoning (MetaTKGR) framework. Unlike prior work that relies on rigid neighborhood aggregation schemes to enhance low-data entity representation, MetaTKGR dynamically adjusts the strategies of sampling and aggregating neighbors from recent facts for new entities, through temporally supervised signals on future facts as instant feedback. Besides, such a meta temporal reasoning procedure goes beyond existing meta-learning paradigms on static knowledge graphs that fail to handle temporal adaptation with large entity variance. We further provide a theoretical analysis and propose a temporal adaptation regularizer to stabilize the meta temporal reasoning over time. Empirically, extensive experiments on three real-world TKGs demonstrate the superiority of MetaTKGR over state-of-the-art baselines by a large margin.
Unsupervised Belief Representation Learning in Polarized Networks with Information-Theoretic Variational Graph Auto-Encoders
Oct 11, 2021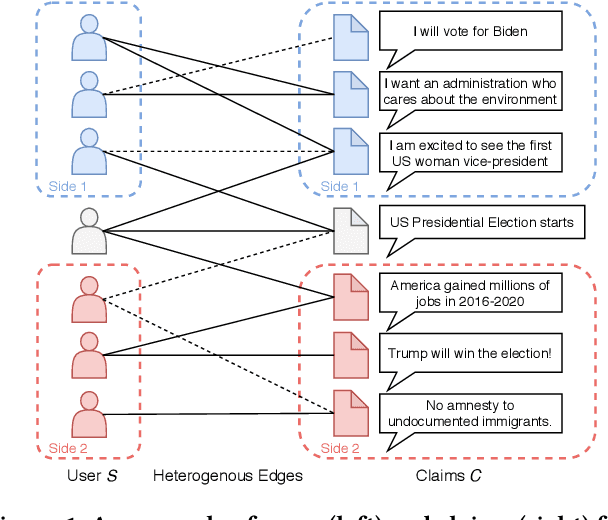
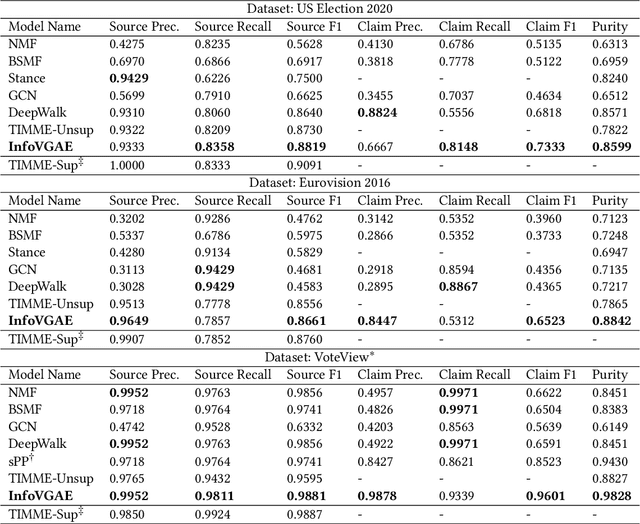
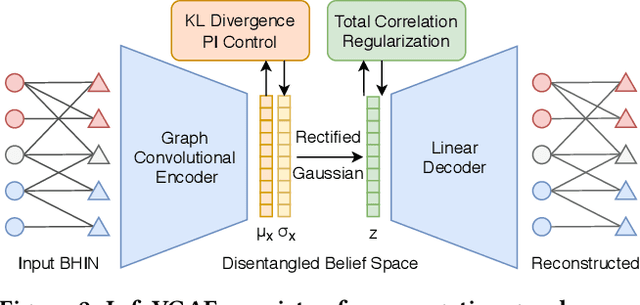

This paper develops a novel unsupervised algorithm for belief representation learning in polarized networks that (i) uncovers the latent dimensions of the underlying belief space and (ii) jointly embeds users and content items (that they interact with) into that space in a manner that facilitates a number of downstream tasks, such as stance detection, stance prediction, and ideology mapping. Inspired by total correlation in information theory, we propose a novel Information-Theoretic Variational Graph Auto-Encoder (InfoVGAE) that learns to project both users and content items (e.g., posts that represent user views) into an appropriate disentangled latent space. In order to better disentangle orthogonal latent variables in that space, we develop total correlation regularization, PI control module, and adopt rectified Gaussian Distribution for the latent space. The latent representation of users and content can then be used to quantify their ideological leaning and detect/predict their stances on issues. We evaluate the performance of the proposed InfoVGAE on three real-world datasets, of which two are collected from Twitter and one from U.S. Congress voting records. The evaluation results show that our model outperforms state-of-the-art unsupervised models and produce comparable result with supervised models. We also discuss stance prediction and user ranking within ideological groups.
Controllable Variational Autoencoder
Apr 13, 2020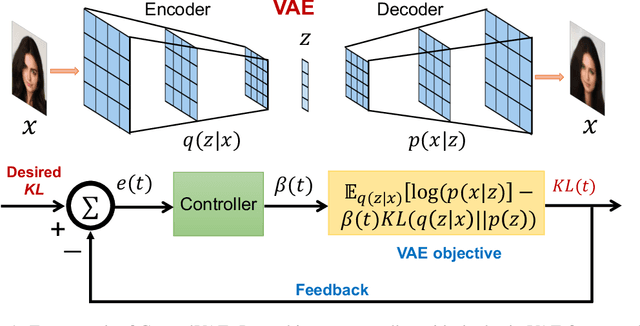

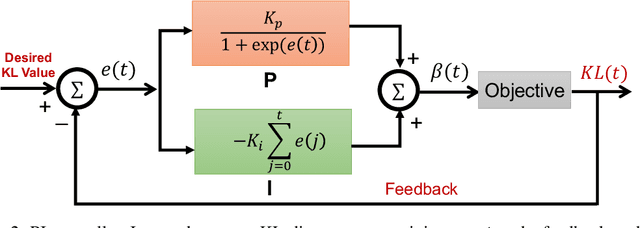

Variational Autoencoders (VAE) and their variants have been widely used in a variety of applications, such as dialog generation, image generation and disentangled representation learning. However, the existing VAE models have some limitations in different applications. For example, a VAE easily suffers from KL vanishing in language modeling and low reconstruction quality for disentangling. To address these issues, we propose a novel controllable variational autoencoder framework, ControlVAE, that combines a controller, inspired by automatic control theory, with the basic VAE to improve the performance of resulting generative models. Specifically, we design a new non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to automatically tune the hyperparameter (weight) added in the VAE objective using the output KL-divergence as feedback during model training. The framework is evaluated using three applications; namely, language modeling, disentangled representation learning, and image generation. The results show that ControlVAE can achieve better disentangling and reconstruction quality than the existing methods. For language modelling, it not only averts the KL-vanishing, but also improves the diversity of generated text. Finally, we also demonstrate that ControlVAE improves the reconstruction quality of generated images compared to the original VAE.