 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePave Your Own Path: Graph Gradual Domain Adaptation on Fused Gromov-Wasserstein Geodesics
May 19, 2025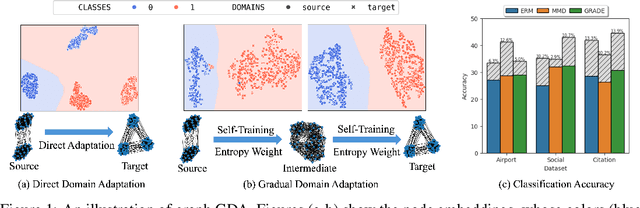
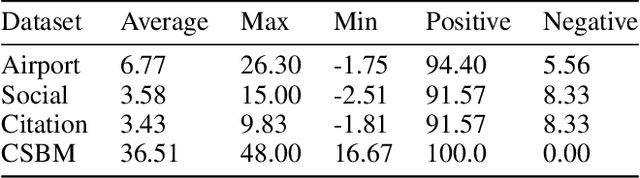
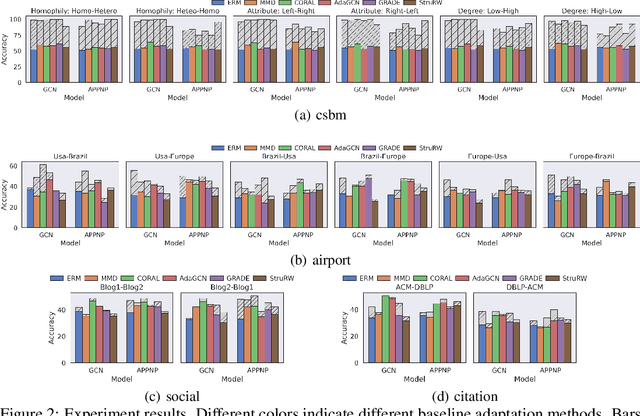
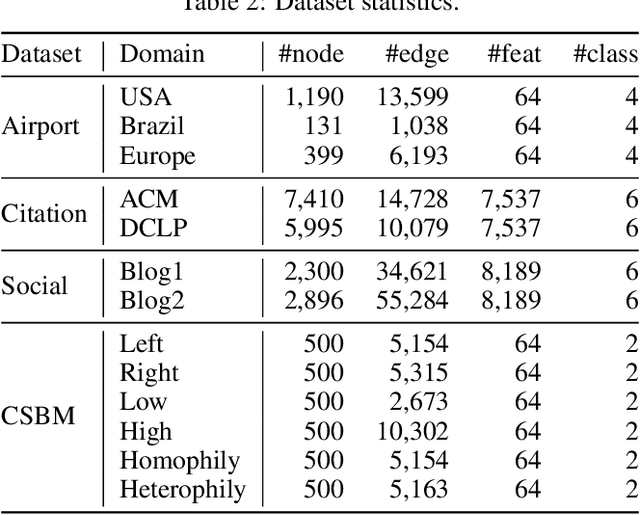
Graph neural networks, despite their impressive performance, are highly vulnerable to distribution shifts on graphs. Existing graph domain adaptation (graph DA) methods often implicitly assume a \textit{mild} shift between source and target graphs, limiting their applicability to real-world scenarios with \textit{large} shifts. Gradual domain adaptation (GDA) has emerged as a promising approach for addressing large shifts by gradually adapting the source model to the target domain via a path of unlabeled intermediate domains. Existing GDA methods exclusively focus on independent and identically distributed (IID) data with a predefined path, leaving their extension to \textit{non-IID graphs without a given path} an open challenge. To bridge this gap, we present Gadget, the first GDA framework for non-IID graph data. First (\textit{theoretical foundation}), the Fused Gromov-Wasserstein (FGW) distance is adopted as the domain discrepancy for non-IID graphs, based on which, we derive an error bound revealing that the target domain error is proportional to the length of the path. Second (\textit{optimal path}), guided by the error bound, we identify the FGW geodesic as the optimal path, which can be efficiently generated by our proposed algorithm. The generated path can be seamlessly integrated with existing graph DA methods to handle large shifts on graphs, improving state-of-the-art graph DA methods by up to 6.8\% in node classification accuracy on real-world datasets.
Noisy Positive-Unlabeled Learning with Self-Training for Speculative Knowledge Graph Reasoning
Jun 13, 2023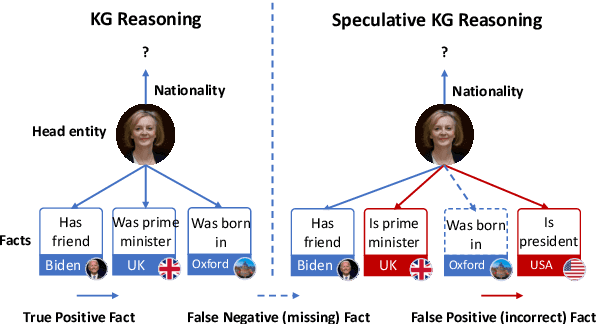
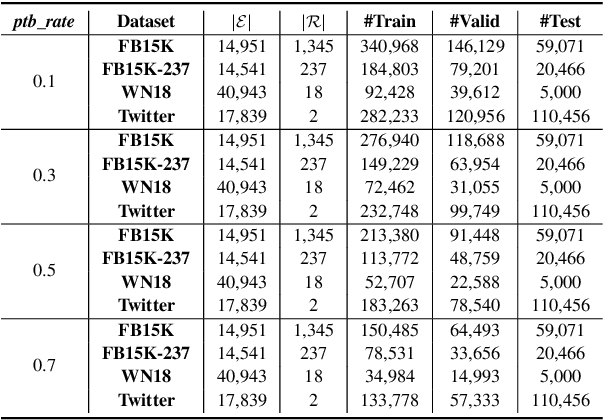
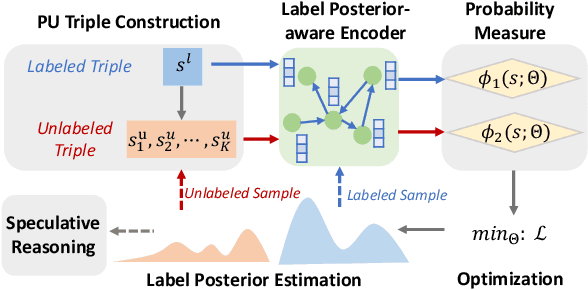
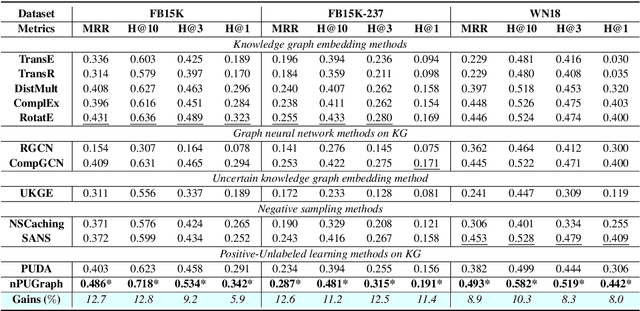
This paper studies speculative reasoning task on real-world knowledge graphs (KG) that contain both \textit{false negative issue} (i.e., potential true facts being excluded) and \textit{false positive issue} (i.e., unreliable or outdated facts being included). State-of-the-art methods fall short in the speculative reasoning ability, as they assume the correctness of a fact is solely determined by its presence in KG, making them vulnerable to false negative/positive issues. The new reasoning task is formulated as a noisy Positive-Unlabeled learning problem. We propose a variational framework, namely nPUGraph, that jointly estimates the correctness of both collected and uncollected facts (which we call \textit{label posterior}) and updates model parameters during training. The label posterior estimation facilitates speculative reasoning from two perspectives. First, it improves the robustness of a label posterior-aware graph encoder against false positive links. Second, it identifies missing facts to provide high-quality grounds of reasoning. They are unified in a simple yet effective self-training procedure. Empirically, extensive experiments on three benchmark KG and one Twitter dataset with various degrees of false negative/positive cases demonstrate the effectiveness of nPUGraph.
Disentangling Overlapping Beliefs by Structured Matrix Factorization
Feb 13, 2020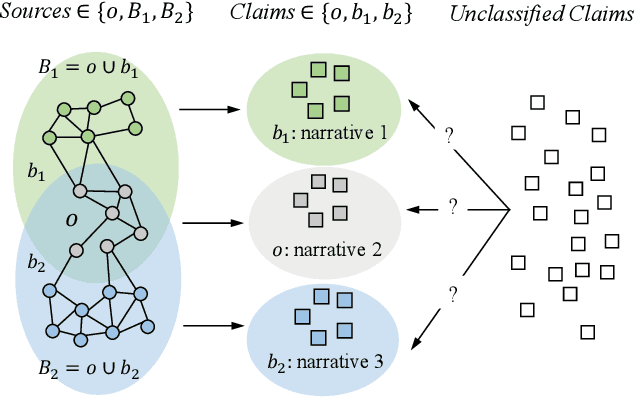


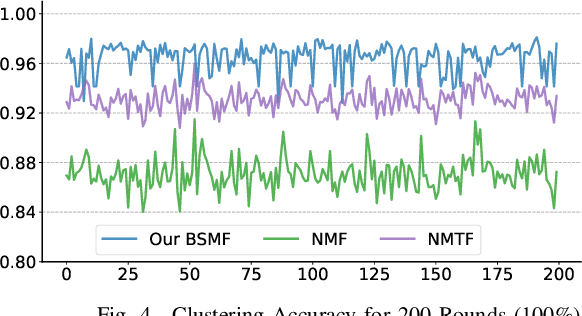
Much work on social media opinion polarization focuses on identifying separate or orthogonal beliefs from media traces, thereby missing points of agreement among different communities. This paper develops a new class of Non-negative Matrix Factorization (NMF) algorithms that allow identification of both agreement and disagreement points when beliefs of different communities partially overlap. Specifically, we propose a novel Belief Structured Matrix Factorization algorithm (BSMF) to identify partially overlapping beliefs in polarized public social media. BSMF is totally unsupervised and considers three types of information: (i) who posted which opinion, (ii) keyword-level message similarity, and (iii) empirically observed social dependency graphs (e.g., retweet graphs), to improve belief separation. In the space of unsupervised belief separation algorithms, the emphasis was mostly given to the problem of identifying disjoint (e.g., conflicting) beliefs. The case when individuals with different beliefs agree on some subset of points was less explored. We observe that social beliefs overlap even in polarized scenarios. Our proposed unsupervised algorithm captures both the latent belief intersections and dissimilarities. We discuss the properties of the algorithm and conduct extensive experiments on both synthetic data and real-world datasets. The results show that our model outperforms all compared baselines by a great margin.
CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases
Jun 02, 2017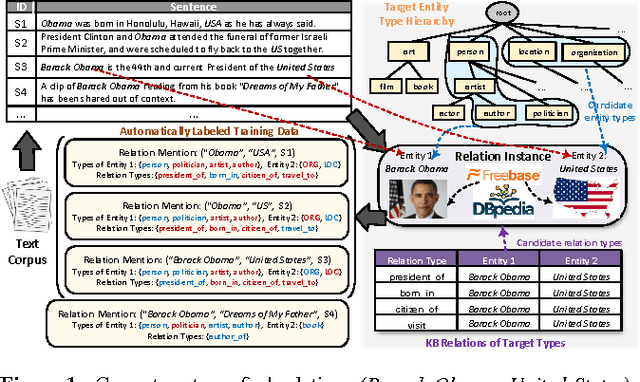



Extracting entities and relations for types of interest from text is important for understanding massive text corpora. Traditionally, systems of entity relation extraction have relied on human-annotated corpora for training and adopted an incremental pipeline. Such systems require additional human expertise to be ported to a new domain, and are vulnerable to errors cascading down the pipeline. In this paper, we investigate joint extraction of typed entities and relations with labeled data heuristically obtained from knowledge bases (i.e., distant supervision). As our algorithm for type labeling via distant supervision is context-agnostic, noisy training data poses unique challenges for the task. We propose a novel domain-independent framework, called CoType, that runs a data-driven text segmentation algorithm to extract entity mentions, and jointly embeds entity mentions, relation mentions, text features and type labels into two low-dimensional spaces (for entity and relation mentions respectively), where, in each space, objects whose types are close will also have similar representations. CoType, then using these learned embeddings, estimates the types of test (unlinkable) mentions. We formulate a joint optimization problem to learn embeddings from text corpora and knowledge bases, adopting a novel partial-label loss function for noisy labeled data and introducing an object "translation" function to capture the cross-constraints of entities and relations on each other. Experiments on three public datasets demonstrate the effectiveness of CoType across different domains (e.g., news, biomedical), with an average of 25% improvement in F1 score compared to the next best method.