 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases
Paper and Code
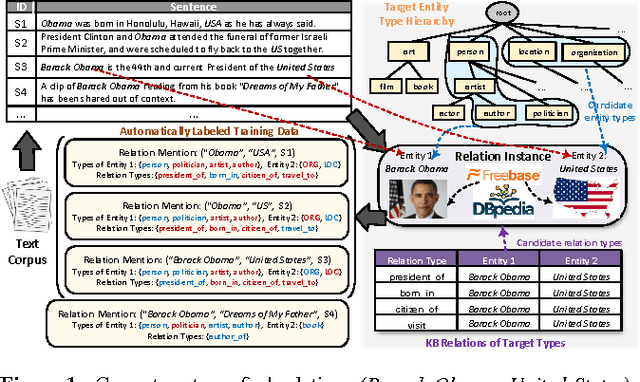



Extracting entities and relations for types of interest from text is important for understanding massive text corpora. Traditionally, systems of entity relation extraction have relied on human-annotated corpora for training and adopted an incremental pipeline. Such systems require additional human expertise to be ported to a new domain, and are vulnerable to errors cascading down the pipeline. In this paper, we investigate joint extraction of typed entities and relations with labeled data heuristically obtained from knowledge bases (i.e., distant supervision). As our algorithm for type labeling via distant supervision is context-agnostic, noisy training data poses unique challenges for the task. We propose a novel domain-independent framework, called CoType, that runs a data-driven text segmentation algorithm to extract entity mentions, and jointly embeds entity mentions, relation mentions, text features and type labels into two low-dimensional spaces (for entity and relation mentions respectively), where, in each space, objects whose types are close will also have similar representations. CoType, then using these learned embeddings, estimates the types of test (unlinkable) mentions. We formulate a joint optimization problem to learn embeddings from text corpora and knowledge bases, adopting a novel partial-label loss function for noisy labeled data and introducing an object "translation" function to capture the cross-constraints of entities and relations on each other. Experiments on three public datasets demonstrate the effectiveness of CoType across different domains (e.g., news, biomedical), with an average of 25% improvement in F1 score compared to the next best method.