 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Agentic AI
Dec 22, 2025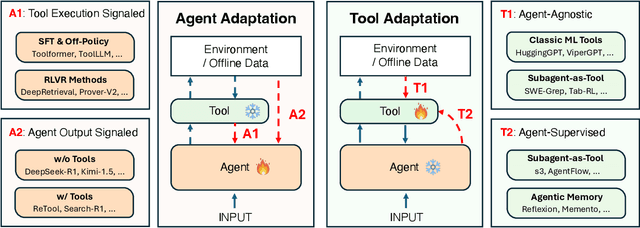
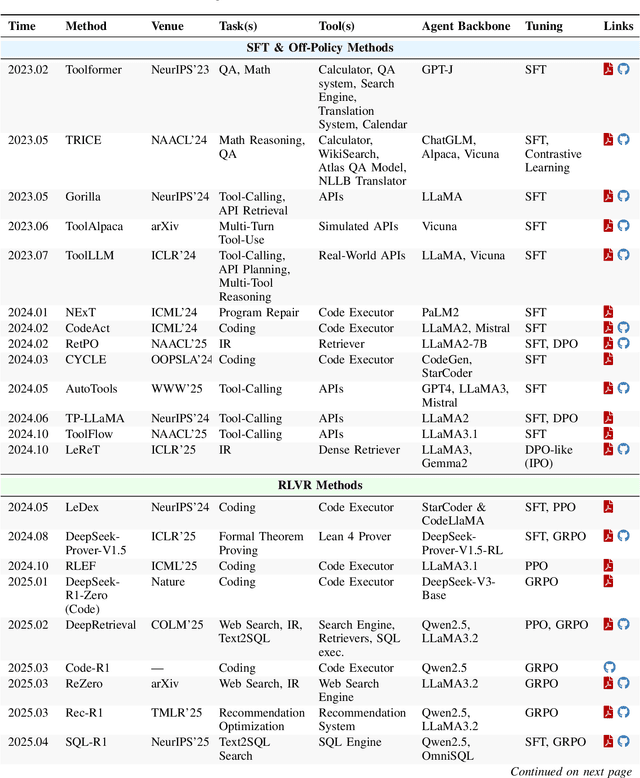
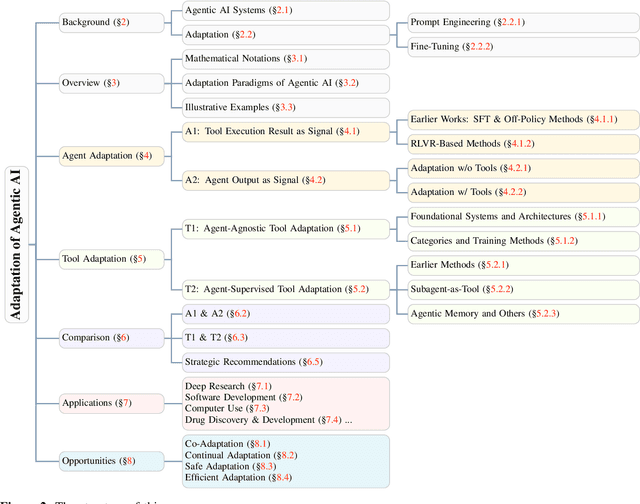
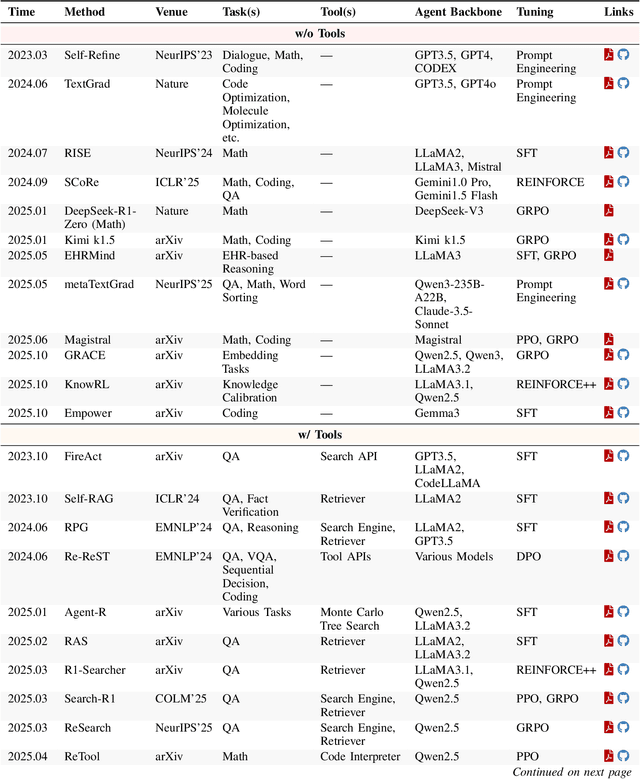
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
Jan 08, 2024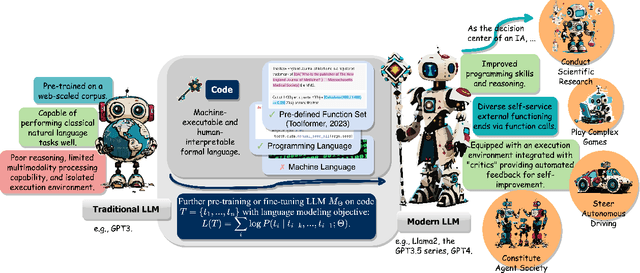
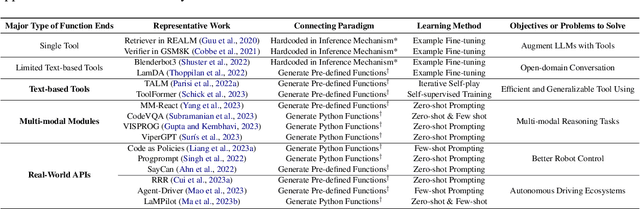
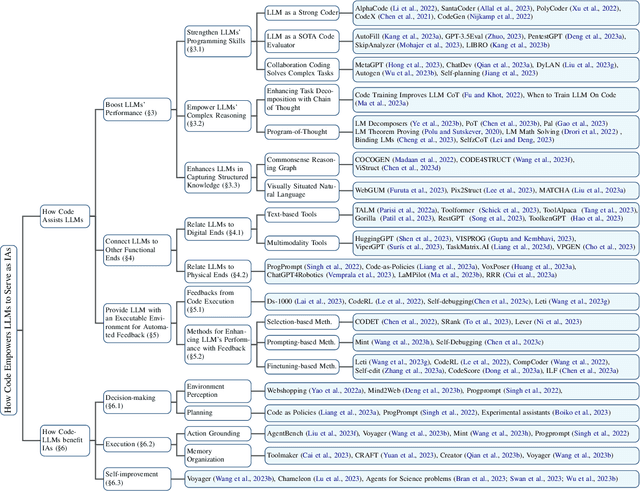

The prominent large language models (LLMs) of today differ from past language models not only in size, but also in the fact that they are trained on a combination of natural language and formal language (code). As a medium between humans and computers, code translates high-level goals into executable steps, featuring standard syntax, logical consistency, abstraction, and modularity. In this survey, we present an overview of the various benefits of integrating code into LLMs' training data. Specifically, beyond enhancing LLMs in code generation, we observe that these unique properties of code help (i) unlock the reasoning ability of LLMs, enabling their applications to a range of more complex natural language tasks; (ii) steer LLMs to produce structured and precise intermediate steps, which can then be connected to external execution ends through function calls; and (iii) take advantage of code compilation and execution environment, which also provides diverse feedback for model improvement. In addition, we trace how these profound capabilities of LLMs, brought by code, have led to their emergence as intelligent agents (IAs) in situations where the ability to understand instructions, decompose goals, plan and execute actions, and refine from feedback are crucial to their success on downstream tasks. Finally, we present several key challenges and future directions of empowering LLMs with code.
BIOT: Cross-data Biosignal Learning in the Wild
May 10, 2023Biological signals, such as electroencephalograms (EEG), play a crucial role in numerous clinical applications, exhibiting diverse data formats and quality profiles. Current deep learning models for biosignals are typically specialized for specific datasets and clinical settings, limiting their broader applicability. Motivated by the success of large language models in text processing, we explore the development of foundational models that are trained from multiple data sources and can be fine-tuned on different downstream biosignal tasks. To overcome the unique challenges associated with biosignals of various formats, such as mismatched channels, variable sample lengths, and prevalent missing values, we propose a Biosignal Transformer (\method). The proposed \method model can enable cross-data learning with mismatched channels, variable lengths, and missing values by tokenizing diverse biosignals into unified "biosignal sentences". Specifically, we tokenize each channel into fixed-length segments containing local signal features, flattening them to form consistent "sentences". Channel embeddings and {\em relative} position embeddings are added to preserve spatio-temporal features. The \method model is versatile and applicable to various biosignal learning settings across different datasets, including joint pre-training for larger models. Comprehensive evaluations on EEG, electrocardiogram (ECG), and human activity sensory signals demonstrate that \method outperforms robust baselines in common settings and facilitates learning across multiple datasets with different formats. Use CHB-MIT seizure detection task as an example, our vanilla \method model shows 3\% improvement over baselines in balanced accuracy, and the pre-trained \method models (optimized from other data sources) can further bring up to 4\% improvements.
ManyDG: Many-domain Generalization for Healthcare Applications
Jan 21, 2023The vast amount of health data has been continuously collected for each patient, providing opportunities to support diverse healthcare predictive tasks such as seizure detection and hospitalization prediction. Existing models are mostly trained on other patients data and evaluated on new patients. Many of them might suffer from poor generalizability. One key reason can be overfitting due to the unique information related to patient identities and their data collection environments, referred to as patient covariates in the paper. These patient covariates usually do not contribute to predicting the targets but are often difficult to remove. As a result, they can bias the model training process and impede generalization. In healthcare applications, most existing domain generalization methods assume a small number of domains. In this paper, considering the diversity of patient covariates, we propose a new setting by treating each patient as a separate domain (leading to many domains). We develop a new domain generalization method ManyDG, that can scale to such many-domain problems. Our method identifies the patient domain covariates by mutual reconstruction and removes them via an orthogonal projection step. Extensive experiments show that ManyDG can boost the generalization performance on multiple real-world healthcare tasks (e.g., 3.7% Jaccard improvements on MIMIC drug recommendation) and support realistic but challenging settings such as insufficient data and continuous learning.
MedML: Fusing Medical Knowledge and Machine Learning Models for Early Pediatric COVID-19 Hospitalization and Severity Prediction
Jul 25, 2022


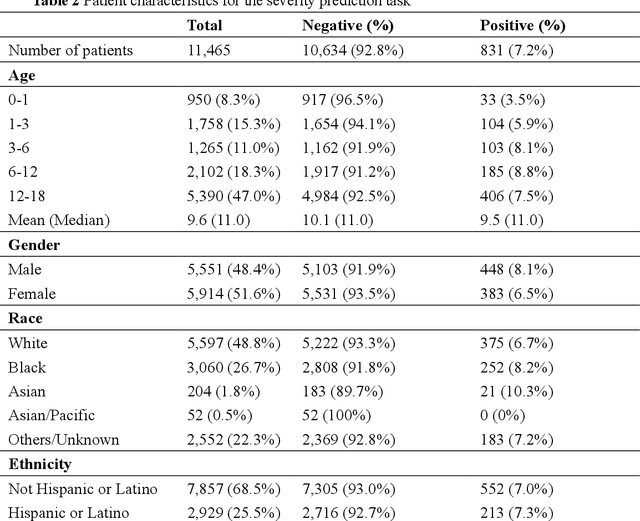
The COVID-19 pandemic has caused devastating economic and social disruption, straining the resources of healthcare institutions worldwide. This has led to a nationwide call for models to predict hospitalization and severe illness in patients with COVID-19 to inform distribution of limited healthcare resources. We respond to one of these calls specific to the pediatric population. To address this challenge, we study two prediction tasks for the pediatric population using electronic health records: 1) predicting which children are more likely to be hospitalized, and 2) among hospitalized children, which individuals are more likely to develop severe symptoms. We respond to the national Pediatric COVID-19 data challenge with a novel machine learning model, MedML. MedML extracts the most predictive features based on medical knowledge and propensity scores from over 6 million medical concepts and incorporates the inter-feature relationships between heterogeneous medical features via graph neural networks (GNN). We evaluate MedML across 143,605 patients for the hospitalization prediction task and 11,465 patients for the severity prediction task using data from the National Cohort Collaborative (N3C) dataset. We also report detailed group-level and individual-level feature importance analyses to evaluate the model interpretability. MedML achieves up to a 7% higher AUROC score and up to a 14% higher AUPRC score compared to the best baseline machine learning models and performs well across all nine national geographic regions and over all three-month spans since the start of the pandemic. Our cross-disciplinary research team has developed a method of incorporating clinical domain knowledge as the framework for a new type of machine learning model that is more predictive and explainable than current state-of-the-art data-driven feature selection methods.
GOCPT: Generalized Online Canonical Polyadic Tensor Factorization and Completion
May 08, 2022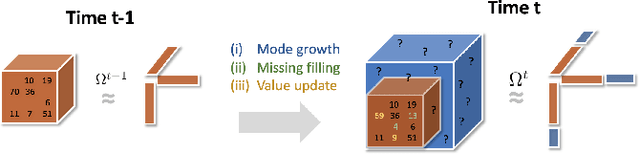
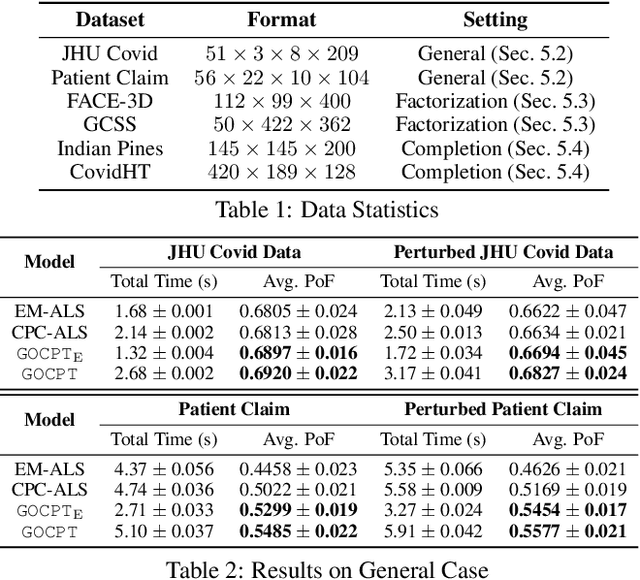
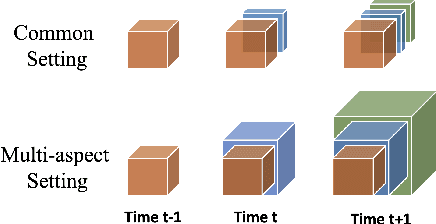
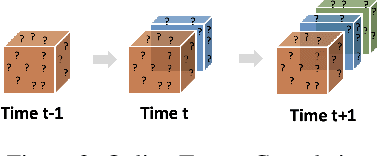
Low-rank tensor factorization or completion is well-studied and applied in various online settings, such as online tensor factorization (where the temporal mode grows) and online tensor completion (where incomplete slices arrive gradually). However, in many real-world settings, tensors may have more complex evolving patterns: (i) one or more modes can grow; (ii) missing entries may be filled; (iii) existing tensor elements can change. Existing methods cannot support such complex scenarios. To fill the gap, this paper proposes a Generalized Online Canonical Polyadic (CP) Tensor factorization and completion framework (named GOCPT) for this general setting, where we maintain the CP structure of such dynamic tensors during the evolution. We show that existing online tensor factorization and completion setups can be unified under the GOCPT framework. Furthermore, we propose a variant, named GOCPTE, to deal with cases where historical tensor elements are unavailable (e.g., privacy protection), which achieves similar fitness as GOCPT but with much less computational cost. Experimental results demonstrate that our GOCPT can improve fitness by up to 2:8% on the JHU Covid data and 9:2% on a proprietary patient claim dataset over baselines. Our variant GOCPTE shows up to 1:2% and 5:5% fitness improvement on two datasets with about 20% speedup compared to the best model.
Self-supervised EEG Representation Learning for Automatic Sleep Staging
Oct 27, 2021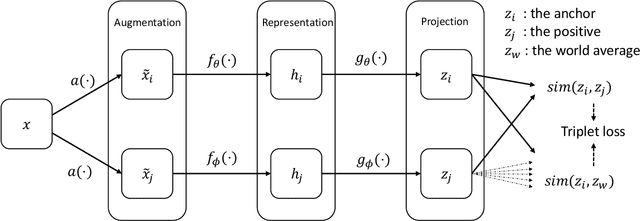
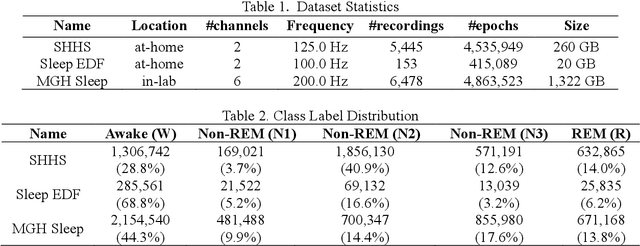
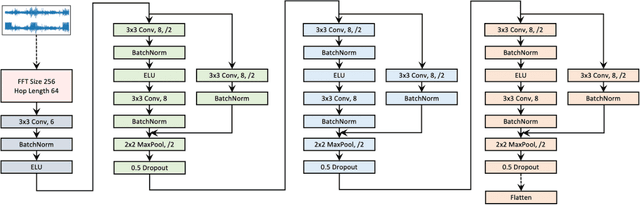
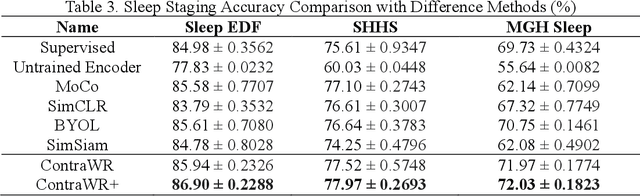
Objective: In this paper, we aim to learn robust vector representations from massive unlabeled Electroencephalogram (EEG) signals, such that the learned representations (1) are expressive enough to replace the raw signals in the sleep staging task; and (2) provide better predictive performance than supervised models in scenarios of fewer labels and noisy samples. Materials and Methods: We propose a self-supervised model, named Contrast with the World Representation (ContraWR), for EEG signal representation learning, which uses global statistics from the dataset to distinguish signals associated with different sleep stages. The ContraWR model is evaluated on three real-world EEG datasets that include both at-home and in-lab recording settings. Results: ContraWR outperforms recent self-supervised learning methods, MoCo, SimCLR, BYOL, SimSiam on the sleep staging task across three datasets. ContraWR also beats supervised learning when fewer training labels are available (e.g., 4% accuracy improvement when less than 2% data is labeled). Moreover, the model provides informative representations in 2D projection. Discussion: The proposed model can be generalized to other unsupervised physiological signal learning tasks. Future directions include exploring task-specific data augmentations and combining self-supervised with supervised methods, building upon the initial success of self-supervised learning in this paper. Conclusions: We show that ContraWR is robust to noise and can provide high-quality EEG representations for downstream prediction tasks. In low-label scenarios (e.g., only 2% data has labels), ContraWR shows much better predictive power (e.g., 4% improvement on sleep staging accuracy) than supervised baselines.
Augmented Tensor Decomposition with Stochastic Optimization
Jul 14, 2021

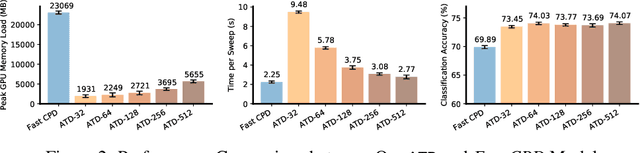
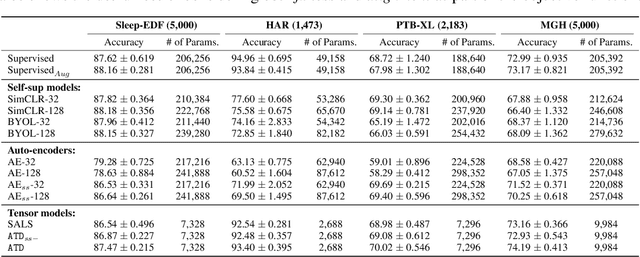
Tensor decompositions are powerful tools for dimensionality reduction and feature interpretation of multidimensional data such as signals. Existing tensor decomposition objectives (e.g., Frobenius norm) are designed for fitting raw data under statistical assumptions, which may not align with downstream classification tasks. Also, real-world tensor data are usually high-ordered and have large dimensions with millions or billions of entries. Thus, it is expensive to decompose the whole tensor with traditional algorithms. In practice, raw tensor data also contains redundant information while data augmentation techniques may be used to smooth out noise in samples. This paper addresses the above challenges by proposing augmented tensor decomposition (ATD), which effectively incorporates data augmentations to boost downstream classification. To reduce the memory footprint of the decomposition, we propose a stochastic algorithm that updates the factor matrices in a batch fashion. We evaluate ATD on multiple signal datasets. It shows comparable or better performance (e.g., up to 15% in accuracy) over self-supervised and autoencoder baselines with less than 5% of model parameters, achieves 0.6% ~ 1.3% accuracy gain over other tensor-based baselines, and reduces the memory footprint by 9X when compared to standard tensor decomposition algorithms.
MTC: Multiresolution Tensor Completion from Partial and Coarse Observations
Jun 18, 2021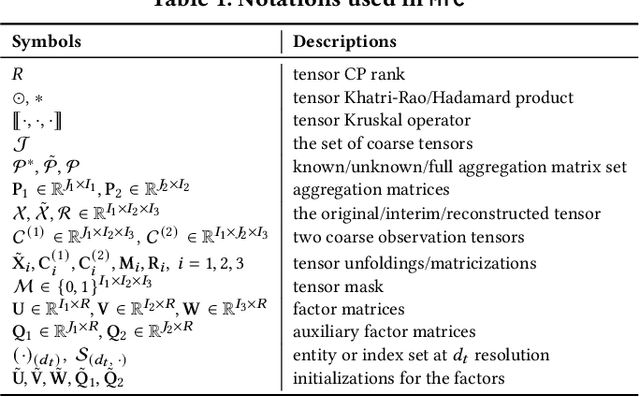
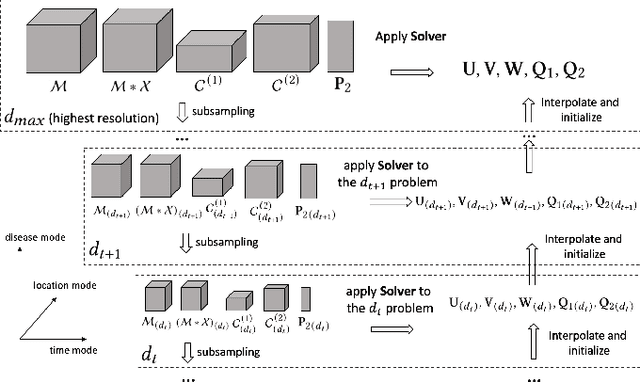
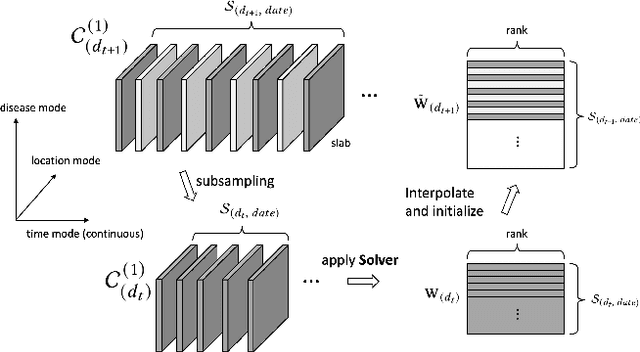

Existing tensor completion formulation mostly relies on partial observations from a single tensor. However, tensors extracted from real-world data are often more complex due to: (i) Partial observation: Only a small subset (e.g., 5%) of tensor elements are available. (ii) Coarse observation: Some tensor modes only present coarse and aggregated patterns (e.g., monthly summary instead of daily reports). In this paper, we are given a subset of the tensor and some aggregated/coarse observations (along one or more modes) and seek to recover the original fine-granular tensor with low-rank factorization. We formulate a coupled tensor completion problem and propose an efficient Multi-resolution Tensor Completion model (MTC) to solve the problem. Our MTC model explores tensor mode properties and leverages the hierarchy of resolutions to recursively initialize an optimization setup, and optimizes on the coupled system using alternating least squares. MTC ensures low computational and space complexity. We evaluate our model on two COVID-19 related spatio-temporal tensors. The experiments show that MTC could provide 65.20% and 75.79% percentage of fitness (PoF) in tensor completion with only 5% fine granular observations, which is 27.96% relative improvement over the best baseline. To evaluate the learned low-rank factors, we also design a tensor prediction task for daily and cumulative disease case predictions, where MTC achieves 50% in PoF and 30% relative improvements over the best baseline.
Change Matters: Medication Change Prediction with Recurrent Residual Networks
May 05, 2021
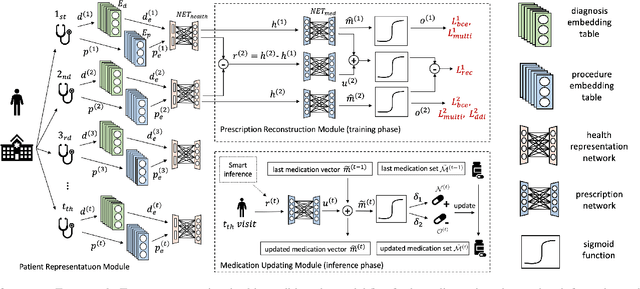

Deep learning is revolutionizing predictive healthcare, including recommending medications to patients with complex health conditions. Existing approaches focus on predicting all medications for the current visit, which often overlaps with medications from previous visits. A more clinically relevant task is to identify medication changes. In this paper, we propose a new recurrent residual network, named MICRON, for medication change prediction. MICRON takes the changes in patient health records as input and learns to update a hidden medication vector and the medication set recurrently with a reconstruction design. The medication vector is like the memory cell that encodes longitudinal information of medications. Unlike traditional methods that require the entire patient history for prediction, MICRON has a residual-based inference that allows for sequential updating based only on new patient features (e.g., new diagnoses in the recent visit) more efficiently. We evaluated MICRON on real inpatient and outpatient datasets. MICRON achieves 3.5% and 7.8% relative improvements over the best baseline in F1 score, respectively. MICRON also requires fewer parameters, which significantly reduces the training time to 38.3s per epoch with 1.5x speed-up.