 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPINACH: SPARQL-Based Information Navigation for Challenging Real-World Questions
Jul 16, 2024

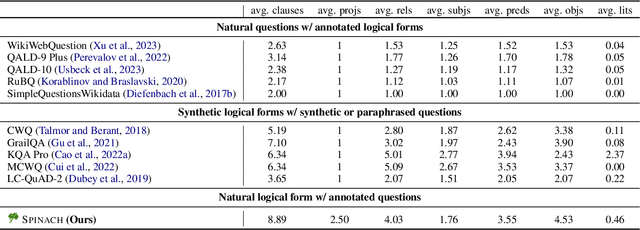
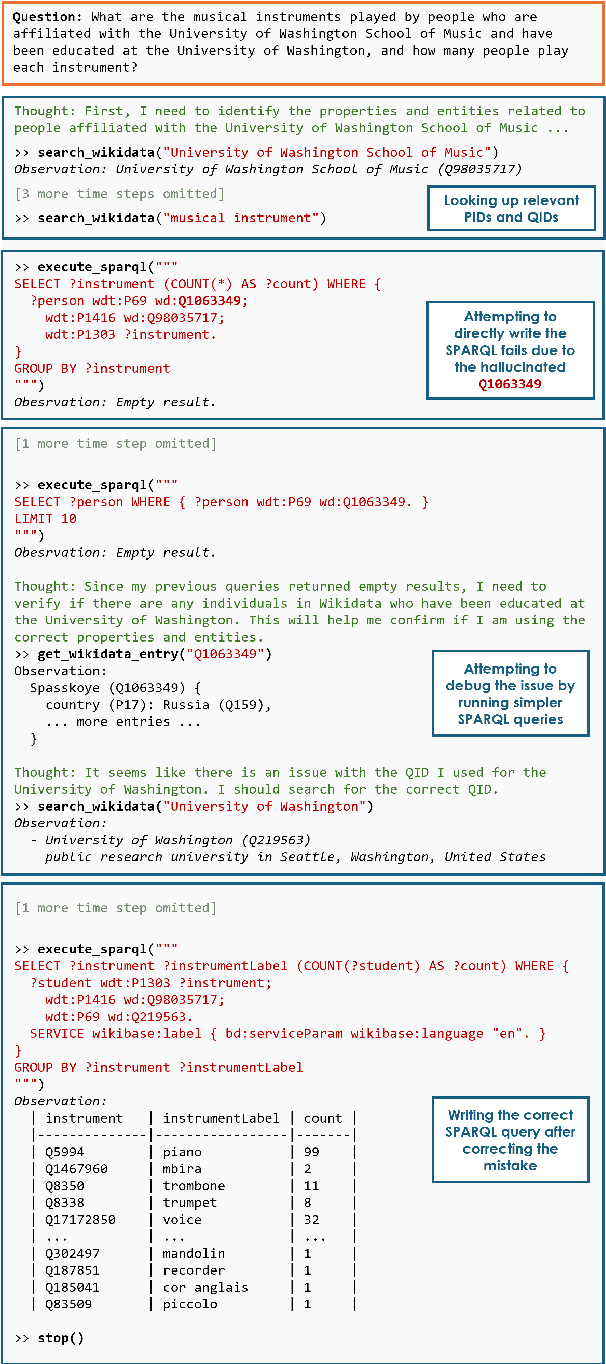
Recent work integrating Large Language Models (LLMs) has led to significant improvements in the Knowledge Base Question Answering (KBQA) task. However, we posit that existing KBQA datasets that either have simple questions, use synthetically generated logical forms, or are based on small knowledge base (KB) schemas, do not capture the true complexity of KBQA tasks. To address this, we introduce the SPINACH dataset, an expert-annotated KBQA dataset collected from forum discussions on Wikidata's "Request a Query" forum with 320 decontextualized question-SPARQL pairs. Much more complex than existing datasets, SPINACH calls for strong KBQA systems that do not rely on training data to learn the KB schema, but can dynamically explore large and often incomplete schemas and reason about them. Along with the dataset, we introduce the SPINACH agent, a new KBQA approach that mimics how a human expert would write SPARQLs for such challenging questions. Experiments on existing datasets show SPINACH's capability in KBQA, achieving a new state of the art on the QALD-7, QALD-9 Plus and QALD-10 datasets by 30.1%, 27.0%, and 10.0% in F1, respectively, and coming within 1.6% of the fine-tuned LLaMA SOTA model on WikiWebQuestions. On our new SPINACH dataset, SPINACH agent outperforms all baselines, including the best GPT-4-based KBQA agent, by 38.1% in F1.