 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRA: Better Length Generalisation with Threshold Relative Attention
Apr 02, 2025Transformers struggle with length generalisation, displaying poor performance even on basic tasks. We test whether these limitations can be explained through two key failures of the self-attention mechanism. The first is the inability to fully remove irrelevant information. The second is tied to position, even if the dot product between a key and query is highly negative (i.e. an irrelevant key) learned positional biases may unintentionally up-weight such information - dangerous when distances become out of distribution. Put together, these two failure cases lead to compounding generalisation difficulties. We test whether they can be mitigated through the combination of a) selective sparsity - completely removing irrelevant keys from the attention softmax and b) contextualised relative distance - distance is only considered as between the query and the keys that matter. We show how refactoring the attention mechanism with these two mitigations in place can substantially improve generalisation capabilities of decoder only transformers.
Compositional Generalization Across Distributional Shifts with Sparse Tree Operations
Dec 18, 2024Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is \textit{hybrid} neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a \textit{unified} neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model's efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
Mechanisms of Symbol Processing for In-Context Learning in Transformer Networks
Oct 23, 2024Large Language Models (LLMs) have demonstrated impressive abilities in symbol processing through in-context learning (ICL). This success flies in the face of decades of predictions that artificial neural networks cannot master abstract symbol manipulation. We seek to understand the mechanisms that can enable robust symbol processing in transformer networks, illuminating both the unanticipated success, and the significant limitations, of transformers in symbol processing. Borrowing insights from symbolic AI on the power of Production System architectures, we develop a high-level language, PSL, that allows us to write symbolic programs to do complex, abstract symbol processing, and create compilers that precisely implement PSL programs in transformer networks which are, by construction, 100% mechanistically interpretable. We demonstrate that PSL is Turing Universal, so the work can inform the understanding of transformer ICL in general. The type of transformer architecture that we compile from PSL programs suggests a number of paths for enhancing transformers' capabilities at symbol processing. (Note: The first section of the paper gives an extended synopsis of the entire paper.)
Implicit Chain of Thought Reasoning via Knowledge Distillation
Nov 02, 2023To augment language models with the ability to reason, researchers usually prompt or finetune them to produce chain of thought reasoning steps before producing the final answer. However, although people use natural language to reason effectively, it may be that LMs could reason more effectively with some intermediate computation that is not in natural language. In this work, we explore an alternative reasoning approach: instead of explicitly producing the chain of thought reasoning steps, we use the language model's internal hidden states to perform implicit reasoning. The implicit reasoning steps are distilled from a teacher model trained on explicit chain-of-thought reasoning, and instead of doing reasoning "horizontally" by producing intermediate words one-by-one, we distill it such that the reasoning happens "vertically" among the hidden states in different layers. We conduct experiments on a multi-digit multiplication task and a grade school math problem dataset and find that this approach enables solving tasks previously not solvable without explicit chain-of-thought, at a speed comparable to no chain-of-thought.
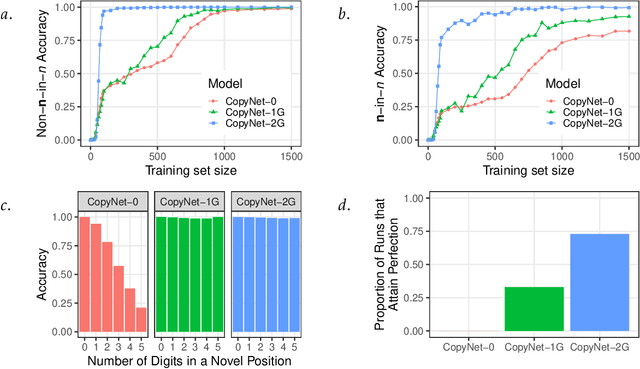
Differentiable Tree Operations Promote Compositional Generalization
Jun 01, 2023In the context of structure-to-structure transformation tasks, learning sequences of discrete symbolic operations poses significant challenges due to their non-differentiability. To facilitate the learning of these symbolic sequences, we introduce a differentiable tree interpreter that compiles high-level symbolic tree operations into subsymbolic matrix operations on tensors. We present a novel Differentiable Tree Machine (DTM) architecture that integrates our interpreter with an external memory and an agent that learns to sequentially select tree operations to execute the target transformation in an end-to-end manner. With respect to out-of-distribution compositional generalization on synthetic semantic parsing and language generation tasks, DTM achieves 100% while existing baselines such as Transformer, Tree Transformer, LSTM, and Tree2Tree LSTM achieve less than 30%. DTM remains highly interpretable in addition to its perfect performance.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022

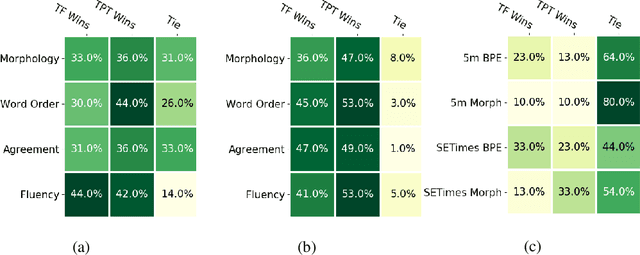
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Neurocompositional computing: From the Central Paradox of Cognition to a new generation of AI systems
May 02, 2022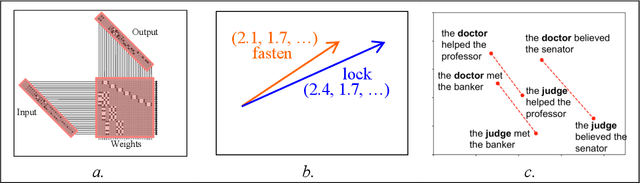
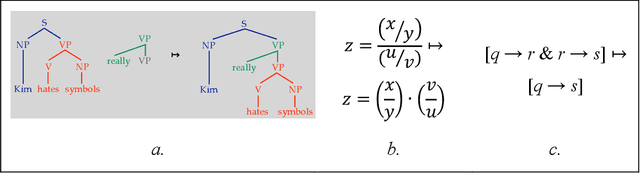
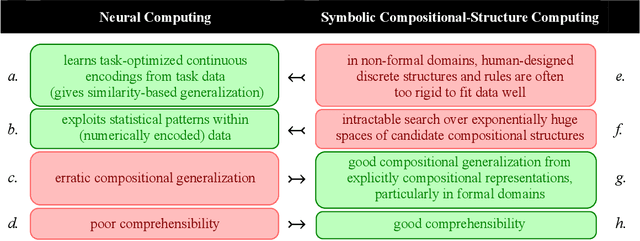
What explains the dramatic progress from 20th-century to 21st-century AI, and how can the remaining limitations of current AI be overcome? The widely accepted narrative attributes this progress to massive increases in the quantity of computational and data resources available to support statistical learning in deep artificial neural networks. We show that an additional crucial factor is the development of a new type of computation. Neurocompositional computing adopts two principles that must be simultaneously respected to enable human-level cognition: the principles of Compositionality and Continuity. These have seemed irreconcilable until the recent mathematical discovery that compositionality can be realized not only through discrete methods of symbolic computing, but also through novel forms of continuous neural computing. The revolutionary recent progress in AI has resulted from the use of limited forms of neurocompositional computing. New, deeper forms of neurocompositional computing create AI systems that are more robust, accurate, and comprehensible.
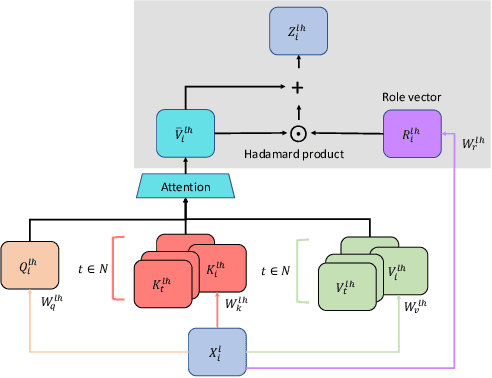
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
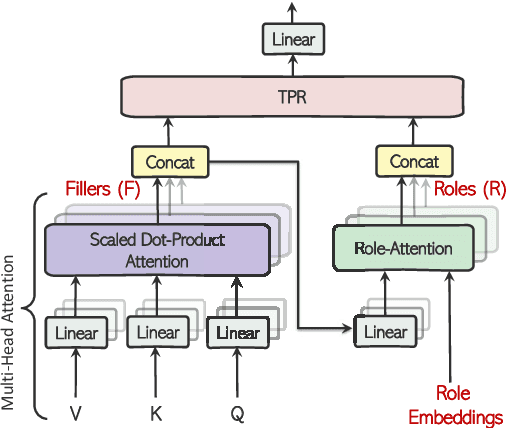
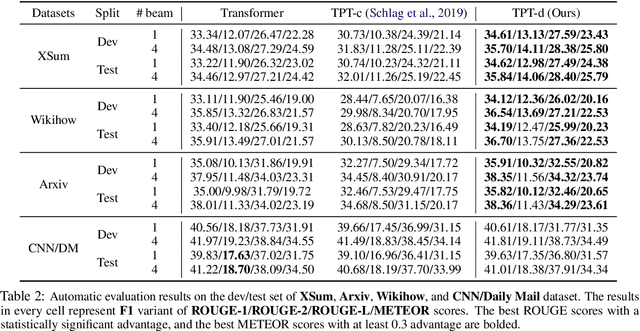
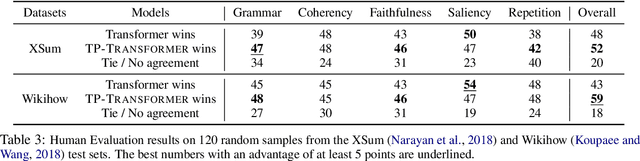
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.
Compositional Processing Emerges in Neural Networks Solving Math Problems
May 19, 2021
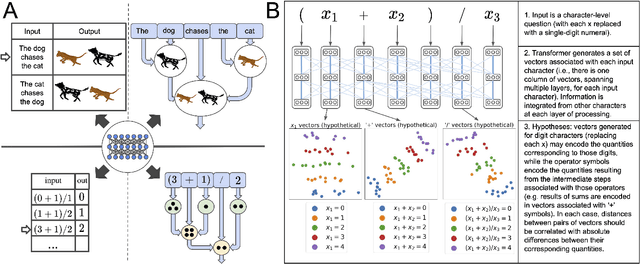
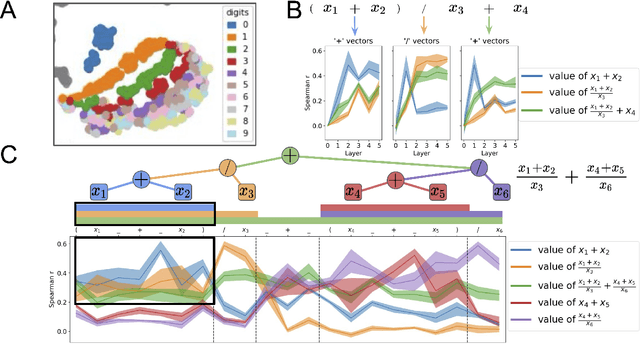
A longstanding question in cognitive science concerns the learning mechanisms underlying compositionality in human cognition. Humans can infer the structured relationships (e.g., grammatical rules) implicit in their sensory observations (e.g., auditory speech), and use this knowledge to guide the composition of simpler meanings into complex wholes. Recent progress in artificial neural networks has shown that when large models are trained on enough linguistic data, grammatical structure emerges in their representations. We extend this work to the domain of mathematical reasoning, where it is possible to formulate precise hypotheses about how meanings (e.g., the quantities corresponding to numerals) should be composed according to structured rules (e.g., order of operations). Our work shows that neural networks are not only able to infer something about the structured relationships implicit in their training data, but can also deploy this knowledge to guide the composition of individual meanings into composite wholes.
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Nov 18, 2020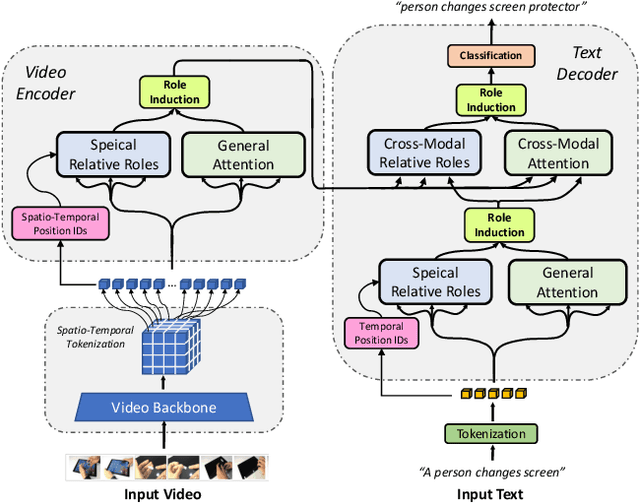
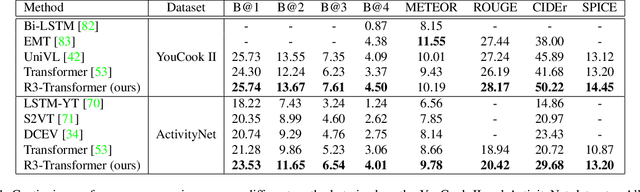
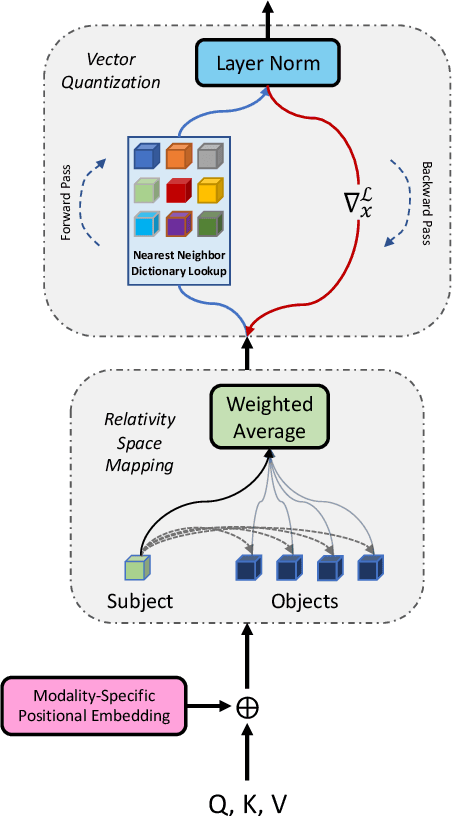
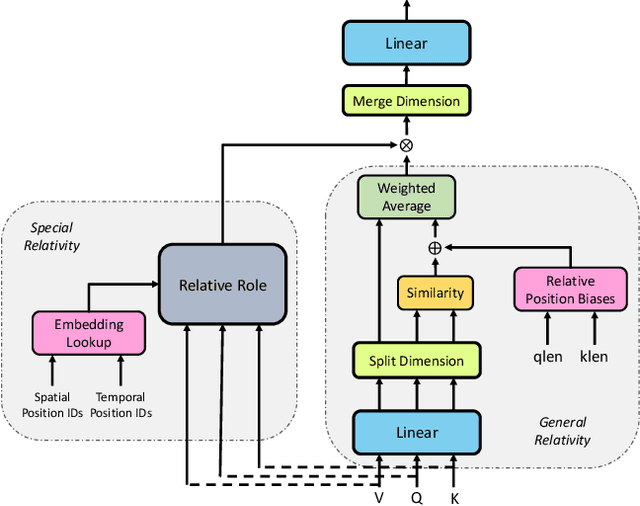
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer